One of the corruptions that can stymie all efforts at disaster recovery is broken boot page. If the boot page can’t be processed, the database can’t be brought online or even put into emergency mode. I first demonstrated how to work around this in my session on Advanced Data Recovery Techniques at PASS in 2014 and here I’d like to walk through the steps of what to do.
First of all, I’ll create a broken boot page in a test database:
-- Drop old database
USE [master];
GO
IF DATABASEPROPERTYEX (N'Company', N'Version') != 0
BEGIN
ALTER DATABASE [Company] SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE [Company];
END
-- Create database and table
CREATE DATABASE [Company] ON PRIMARY (
NAME = N'Company',
FILENAME = N'D:\SQLskills\Company.mdf')
LOG ON (
NAME = N'Company_log',
FILENAME = N'D:\SQLskills\Company_log.ldf');
GO
USE [Company];
GO
CREATE TABLE [Sales] (
[SalesID] INT IDENTITY,
[CustomerID] INT DEFAULT CONVERT (INT, 100000 * RAND ()),
[SalesDate] DATETIME DEFAULT GETDATE (),
[SalesAmount] MONEY DEFAULT CONVERT (MONEY, 100 * RAND ()));
CREATE CLUSTERED INDEX [SalesCI] ON [Sales] ([SalesID]);
GO
-- Populate the table
SET NOCOUNT ON;
GO
INSERT INTO [Sales] DEFAULT VALUES;
GO 5000
-- Create some nonclustered indexes
CREATE NONCLUSTERED INDEX [SalesNCI_CustomerID] ON [Sales] ([CustomerID]);
CREATE NONCLUSTERED INDEX [SalesNCI_SalesDate_SalesAmount] ON [Sales] ([SalesDate]) INCLUDE ([SalesAmount]);
GO
-- Create a good backup
BACKUP DATABASE [Company] TO DISK = N'C:\SQLskills\OldCompany.bck'
WITH INIT;
-- And detach it
USE [master]
GO
EXEC sp_detach_db N'Company';
GO
Now I’ll corrupt it using a hex editor. The one I like to use is called HxD and it’s a freeware tool you can download from here.

And then go to the offset of the boot page. It’s page 9 always, so the offset is 8192 x 9 = 73728.
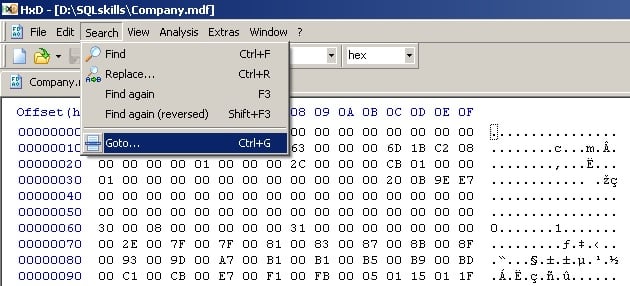
And make sure to select the ‘dec’ option to input the number in decimal, offset from beginning of the file:

You’ll see the boot page contents, including the name of the database:
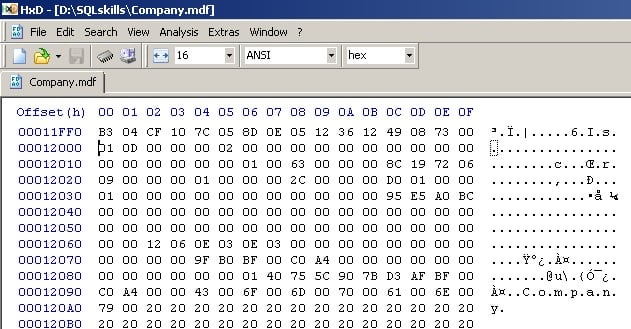
Highlight all the lines down to the database name, and then right-click and select Fill selection…
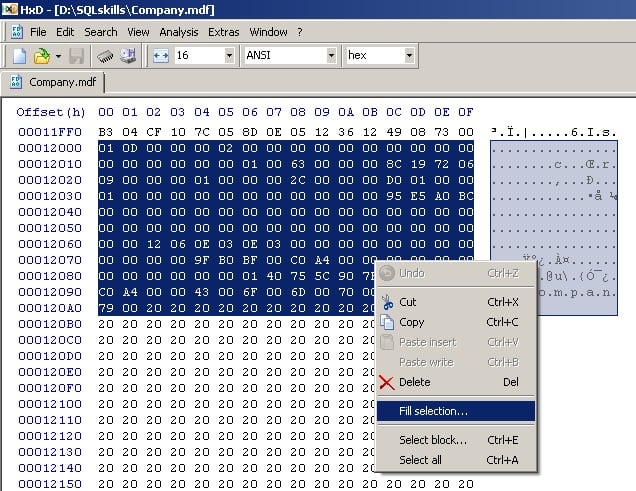
And then select the default to fill that area with zeroes:
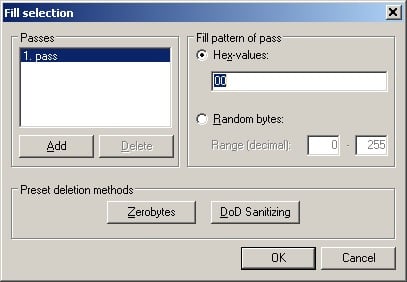
Which will make it look like this:
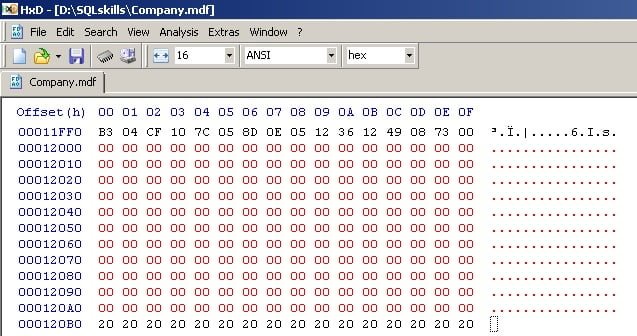
Then hit the disk icon to save the file. Ignore any security errors you get about the ownership of the backup file.
Throughout the rest of these steps, if you get “Access is denied” from SQL Server, you need to change the security in the directory you’re using so the SQL Server service account has the correct file permissions.
You will also see different messages through some of these steps depending on which version of SQL Server you’re using – I’m using SQL Server 2014.
Exit from HxD.
Now we’re ready to try to salvage this database.
First I’ll try to attach it:
USE [master];
GO
-- Try attaching it again
EXEC sp_attach_db @dbname = N'Company',
@filename1 = N'D:\SQLskills\Company.mdf',
@filename2 = N'D:\SQLskills\Company_log.ldf';
GO
Msg 1813, Level 16, State 2, Line 5
Could not open new database 'Company'. CREATE DATABASE is aborted.
Msg 824, Level 24, State 2, Line 5
SQL Server detected a logical consistency-based I/O error: incorrect pageid (expected 1:9; actual 0:0). It occurred during a read of page (1:9) in database ID 6 at offset 0x00000000012000 in file 'D:\SQLskills\Company.mdf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
The attach failed. You can verify this yourself by looking in sys.databases for the database – it’s not there.
I’ll try a hack-attach. I copied off the corrupt database files, and then create the dummy database and set it offline (to release SQL Server’s locks on the files):
CREATE DATABASE [Company] ON PRIMARY (
NAME = N'Company',
FILENAME = N'D:\SQLskills\Company.mdf')
LOG ON (
NAME = N'Company_log',
FILENAME = N'D:\SQLskills\Company_log.ldf');
GO
ALTER DATABASE [Company] SET OFFLINE;
GO
Then delete the dummy database files, and copy in the original corrupt database files. And then try to bring the database online again, completing the hack-attach:
ALTER DATABASE [Company] SET ONLINE;
GO
Msg 5181, Level 16, State 5, Line 33
Could not restart database "Company". Reverting to the previous status.
Msg 5069, Level 16, State 1, Line 33
ALTER DATABASE statement failed.
Msg 824, Level 24, State 2, Line 33
SQL Server detected a logical consistency-based I/O error: incorrect pageid (expected 1:9; actual 0:0). It occurred during a read of page (1:9) in database ID 6 at offset 0x00000000012000 in file 'D:\SQLskills\Company.mdf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
Hmmm… but did it work?
SELECT DATABASEPROPERTYEX (N'Company', N'STATUS');
GO
SUSPECT
Yes! Now let’s try doing an emergency-mode repair:
ALTER DATABASE [Company] SET EMERGENCY;
GO
ALTER DATABASE [Company] SET SINGLE_USER;
GO
Msg 824, Level 24, State 2, Line 43
SQL Server detected a logical consistency-based I/O error: incorrect pageid (expected 1:9; actual 0:0). It occurred during a read of page (1:9) in database ID 6 at offset 0x00000000012000 in file 'D:\SQLskills\Company.mdf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.
Nope – it’s not going to work because the broken boot page won’t allow the database to be accessed at all.
Now we’ll fix it, again using a hex editor.
First off I’ll set the database offline again, copy off the broken files, and drop the database so it’s gone from SQL Server.
ALTER DATABASE [Company] SET OFFLINE;
GO
-- ***** Copy off the corrupt files
DROP DATABASE [Company];
GO
Now I’ll restore an older copy of the database and set it offline so I can open the files with HxD:
RESTORE DATABASE [Company] FROM
DISK = N'C:\SQLskills\OldCompany.bck'
WITH REPLACE;
GO
ALTER DATABASE [Company] SET OFFLINE;
GO
In HxD, I then open the restored copy of the database AND the corrupt database, and go to the boot page offset in both, just as I did in the setup phase above:
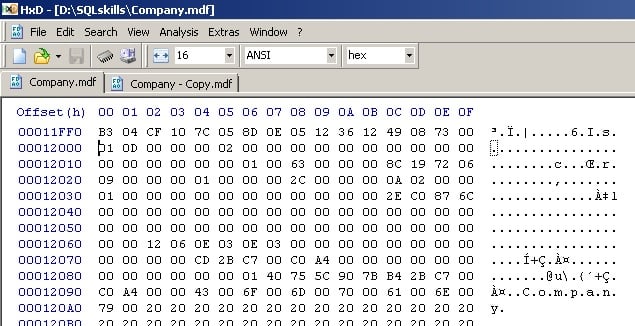
And you can see that the boot page is intact in the restored copy.
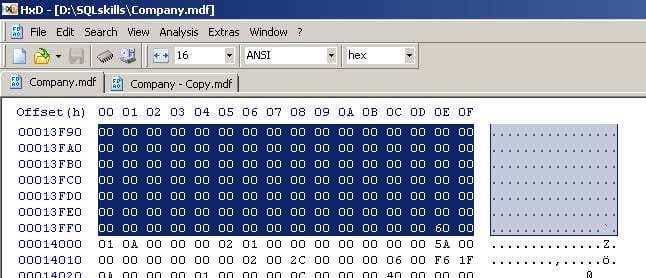
Next, I’ll highlight from 12000 (hexadecimal) down to, but not including, 14000, and then right-click and hit Copy to copy the whole 8192 bytes. These offsets are the same in every database.
Then go to the corrupt file, at offset 12000 (same in every database), right-click and select Paste Write to overwrite the broken boot page:
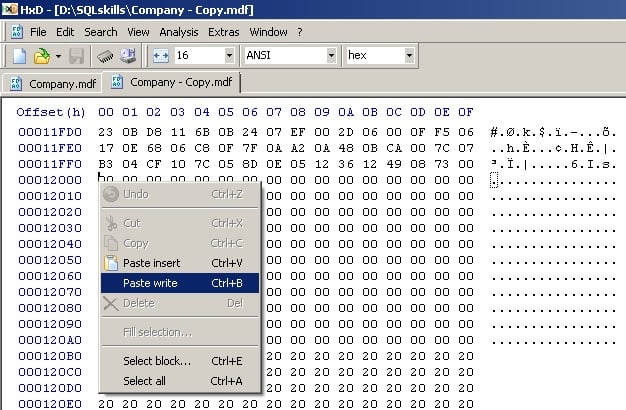
And you’ll see everything between 12000 and 14000 (same in every database) go red:
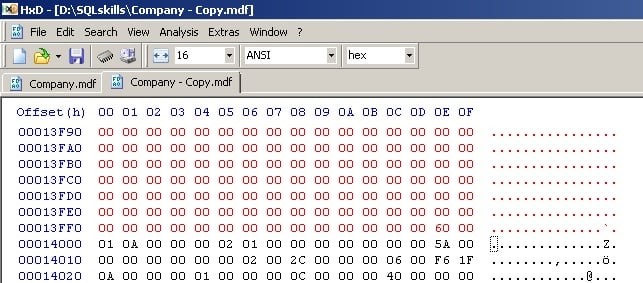
Now save the file and exit HxD.
Delete the restored files, and rename the corrupt files to their correct names. You’ll notice that HxD created a backup copy of the file we just changed – you can ignore it.
ALTER DATABASE [Company] SET ONLINE;
GO
Msg 5181, Level 16, State 5, Line 79
Could not restart database "Company". Reverting to the previous status.
Msg 5069, Level 16, State 1, Line 79
ALTER DATABASE statement failed.
Msg 9003, Level 20, State 9, Line 79
The log scan number (45:16:0) passed to log scan in database 'Company' is not valid. This error may indicate data corruption or that the log file (.ldf) does not match the data file (.mdf). If this error occurred during replication, re-create the publication. Otherwise, restore from backup if the problem results in a failure during startup.
Msg 3414, Level 21, State 1, Line 79
An error occurred during recovery, preventing the database 'Company' (6:0) from restarting. Diagnose the recovery errors and fix them, or restore from a known good backup. If errors are not corrected or expected, contact Technical Support.
Good – the 824 message is gone, but now you can see we have another issue: all the LSNs in the boot page are incorrect now as we’re now using an older boot page that doesn’t match the more recent transaction log. Emergency mode and/or emergency-mode repair is necessary to either access the data or repair the corrupt database.
ALTER DATABASE [Company] SET EMERGENCY;
GO
ALTER DATABASE [Company] SET SINGLE_USER;
GO
DBCC CHECKDB (N'Company', REPAIR_ALLOW_DATA_LOSS) WITH NO_INFOMSGS;
GO
Warning: The log for database 'Company' has been rebuilt. Transactional consistency has been lost. The RESTORE chain was broken, and the server no longer has context on the previous log files, so you will need to know what they were. You should run DBCC CHECKDB to validate physical consistency. The database has been put in dbo-only mode. When you are ready to make the database available for use, you will need to reset database options and delete any extra log files.
In this case there were no other corruptions, so all emergency-mode repair had to do is rebuild the transaction log.
Now we can get in to the database and access the data.
Note: the data is likely to be transactionally inconsistent. If you continue to use the database in production following this procedure, you do so entirely at your own risk.
If you don’t have a backup of the original database, you can use any database as a source for a good boot page – just make sure it has the same name as the one you’re trying to fix. Bear in mind that the further away from a recent backup of the original database, the more trouble you’ll have trying to get crash recovery to work.
And there you have it – no longer do broken boot pages have to curtail data recovery efforts.
Enjoy!
The post Disaster recovery 101: fixing a broken boot page appeared first on Paul S. Randal.









![clip_image001[1]](http://sqlblog.com/blogs/greg_low/clip_image0011_4ABC12E7.png "clip_image001[1]")


")













 So it is now possible to track aggregate runtime metrics for user-defined functions.
So it is now possible to track aggregate runtime metrics for user-defined functions.
 [Advertisement]
[Advertisement]

 [Advertisement] Use NuGet or npm? Check out
[Advertisement] Use NuGet or npm? Check out 






