mjpdejong
Shared posts
Stroom uit zoet en zout water
Cambrian Genomics CEO says his company just raised $10M to ‘print more DNA’

Cambrian Genomics, which has created a promising DNA-printing technology, has raised a sizable $10 million round of funding, by far the largest in the company’s history.
The funding round was described in a Securities and Exchange Commission filing Thursday. The round has a total of 127 participants, and Cambrian isn’t talking about who led the round or how much the participants contributed.
But there are some known names involved. These include Yammer co-founder Adam Pisoni, Draper Associates, and Cloudera founder Jeff Hammerbacher.
In his wry way, Cambrian founder and CEO Austen Heinz told VentureBeat his company will use the new money to “print more DNA.” But there’s more to it than that.
So far we’ve seen just the outlines of what Cambrian might do with its DNA-printing technology. Much of the discussion about the company so far has focused on the novelty factor of the company’s first DNA product, which makes plants glow in the dark.
Cambrian’s second major product isn’t so much novel as it is sensational, even controversial.
Heinz spoke yesterday at the DEMO conference about one of the companies in Cambrian’s new accelerator program. The company, called Personal Probiotics, uses Cambrian’s “Creature Creator” to print a special virus that kills off microbes in the vagina that cause yeast infections and other sexually transmitted diseases (STDs).
The product, called “Sweet Peach,” also reduces vaginal odor, which is what most in the media have seized upon, and not in a way that was very complimentary, or fair, to Cambrian. The pleasant “peach” odor is created as an indicator that it is working within the woman’s body, Heinz said.
Cambrian’s technology is already being used for far less sensitive, and perhaps more useful, use cases. The company has been doing work printing DNA for the huge pharma company Glaxo Smith Kline. It’s also in talks to formalize a similar business relationship with Roche.
Big pharma companies are asking Cambrian to print various types of DNA that can be used in the drug discovery and testing process.
“We’re helping them make drugs,” Heinz said. For example, Cambrian’s DNA can be used for producing small molecules or for making new screens to find small molecules, Heinz said. “DNA can be used for every part of the process,” Heinz said.
Heinz says that his company also intends to print DNA for customers in the industrial chemical and agricultural industries. He says producing seeds used by consumers is in itself a million-dollar industry.
But perhaps the biggest initiative going on at Cambrian now is the development of its incubator, which supplies resources and work space to companies building products on the DNA-printing technology.
Heinz says the incubator may show more upside for his company in the future, because Cambrian can take an equity stake in them, something that would be impossible with its big pharma customers.
Cambrian isn’t the only company on earth printing the blueprint of life, but it has already filed three patents on its DNA-printing tech, two of which are currently under review.
Ranked: The 12 programming languages that will earn you the most

Computer programming has quickly become one of the most lucrative industries in the US.
The average salary for a computer programmer just hit an all-time high as it approaches $100,000.
But there are some languages and skill sets that are more valuable than others, and Quartz has compiled some data to break down these differences.
Quartz’s Max Nisen pulled out some figures on the most valuable programming languages based on a larger study from the Brookings Institution that was published in July.
Based on that data, here are programming languages listed next to their average annual salary from lowest to highest:
12. PERL - $82,513
11. SQL – $85,511
10. Visual Basic – $85,962
9. C# – $89,074
8. R- $90,055
7. C – 90,134
6. JavaScript – $91,461
5. C++ – $93,502
4. JAVA – $94,908
3. Python – $100,717
2. Objective C – $108,225
1. Ruby on Rails – $109,460
While some of these coding languages can help you earn $100,000, train to become a Salesforce architect if you want one of the highest-paying jobs in tech.
According to data from IT recruiting firm Mondo that was published in March, Salesforce Architects can earn between $180,000 and $200,000.
This story originally appeared on www.businessinsider.com.
Mobile developer or publisher? VentureBeat is studying mobile marketing automation. Fill out our 5-minute survey, and we'll share the data with you.

Cambrian Genomics CEO: We’ll design every human on a computer and make poop smell like bananas

Above: CEO Austen Heinz, right.
VIENNA, Austria — Say this for Austen Heinz: His vision for the future will either thrill you or leave you fearing for the future of humanity. There’s not really any room in the middle.
In a pair of interviews, on and off the stage at the Pioneers Festival in Vienna today, the CEO of San Francisco-based Cambrian Genomics explained the mission of his company, which is often benignly described as “laser-printing DNA.”
So what does that mean?
“We want to make everything that is alive on the planet,” he explained. “Everything that is alive is not optimal. It can be made better.”
But he doesn’t have plans for replication: “We want to make totally new organisms that have never existed,” he said. “And replace every existing organism with a better one. It just seems obvious that eventually every human will be designed on a computer.”
Lest you think these are the ravings of a mad scientist, or the opening scene of a new sci-fi dystopian thriller, well, it’s not. Heinz is calm and rational in his view. And while his company has not disclosed its total fundraising, it’s backed by such notable Silicon Valley names as Peter Thiel.
The technology at work here is complex, but essentially Cambrian Genomics says it has found a way to dramatically reduce the cost of printing a strand of DNA. Sequencing of the genome is so advanced, Heinz explained, that basically people can take DNA code from libraries and create organic mash-ups, much the way any programmer can pull computer code from code libraries. That new code is then laser printed for a fraction of what it used to cost.
The most notable example of this technology at work was the “glowing plants” campaign on Kickstarter. Using these synthetic biology techniques, the campaign promised to take bioluminescence genes from bacteria and fireflies and insert them into several plants to make them glow in the dark.
The backers raised $484,013 from 8,433 backers. But then Kickstarter responded by changing its rules by banning genetically modified organisms from its platform.
Now Heinz is fighting back. He said on stage that the company will soon launch its own crowd-funding platform for GMOs, called “creature creators.” Cambrian will also help other people create slick videos to promote their synthetic biological creations.
One such project he mentioned on stage was Petomics. The project essentially aims to take genetic material for the odor of bananas and inject it into E. coli bacteria. The modified bacteria would be introduced into pet food and the result would be … poop that smells like bananas.
“It’s a pretty strong smell, too,” Heinz said.
Heinz doesn’t appear to fear the potential backlash such biological tinkering could provoke. For him, there is a simple logic at work at makes such technology inevitable. People are essentially badly designed computers, he said.
“We are running a program that is designed for us to die,” he said. “I think obviously every organism will be designed synthetically. It’s not a stretch to take it to every human and everything that’s alive.”
A picture is worth a thousand (coherent) words: building a natural description of images
“Two pizzas sitting on top of a stove top oven”
“A group of people shopping at an outdoor market”
“Best seats in the house”
People can summarize a complex scene in a few words without thinking twice. It’s much more difficult for computers. But we’ve just gotten a bit closer -- we’ve developed a machine-learning system that can automatically produce captions (like the three above) to accurately describe images the first time it sees them. This kind of system could eventually help visually impaired people understand pictures, provide alternate text for images in parts of the world where mobile connections are slow, and make it easier for everyone to search on Google for images.
Recent research has greatly improved object detection, classification, and labeling. But accurately describing a complex scene requires a deeper representation of what’s going on in the scene, capturing how the various objects relate to one another and translating it all into natural-sounding language.
 |
| Automatically captioned: “Two pizzas sitting on top of a stove top oven” |
This idea comes from recent advances in machine translation between languages, where a Recurrent Neural Network (RNN) transforms, say, a French sentence into a vector representation, and a second RNN uses that vector representation to generate a target sentence in German.
Now, what if we replaced that first RNN and its input words with a deep Convolutional Neural Network (CNN) trained to classify objects in images? Normally, the CNN’s last layer is used in a final Softmax among known classes of objects, assigning a probability that each object might be in the image. But if we remove that final layer, we can instead feed the CNN’s rich encoding of the image into a RNN designed to produce phrases. We can then train the whole system directly on images and their captions, so it maximizes the likelihood that descriptions it produces best match the training descriptions for each image.
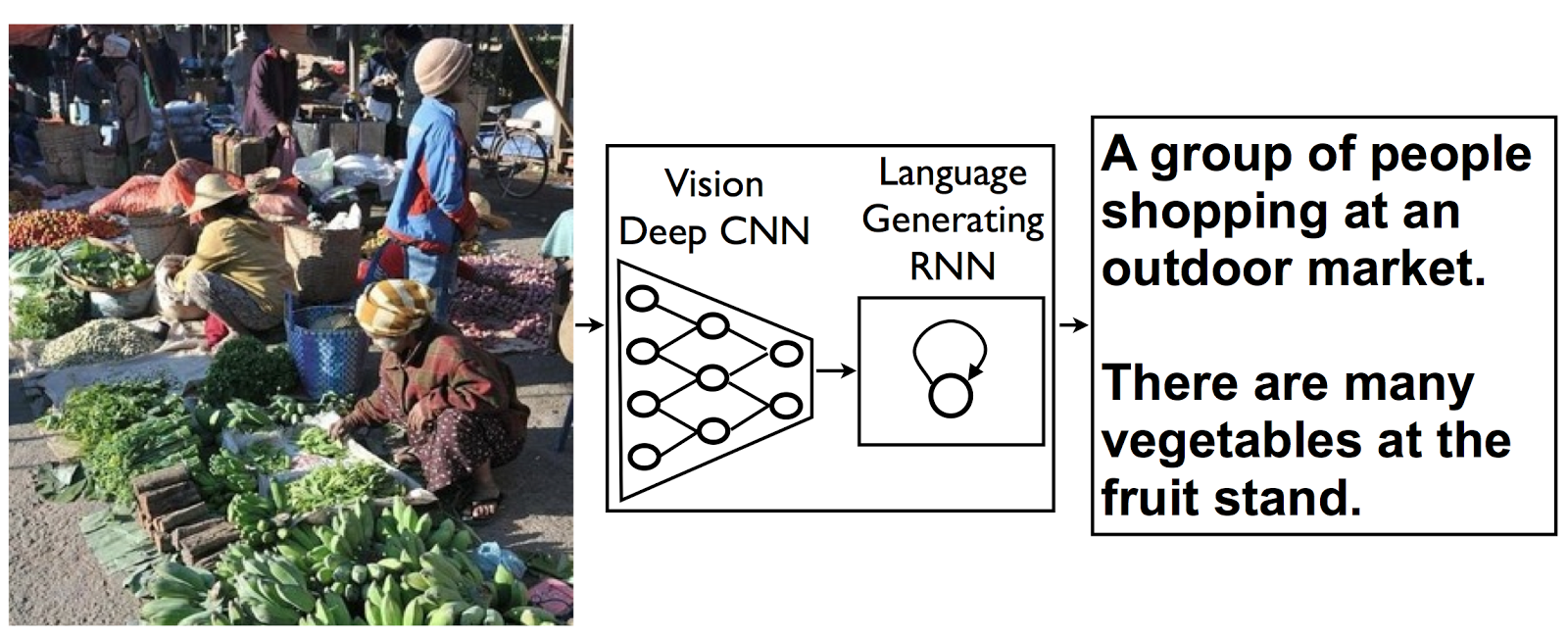 |
| The model combines a vision CNN with a language-generating RNN so it can take in an image and generate a fitting natural-language caption. |
 |
| A selection of evaluation results, grouped by human rating. |

24bit vs 16bit, the myth exploded!
| Sjon shared this story . |
It seems to me that there is a lot of misunderstanding regarding what bit depth is and how it works in digital audio. This misunderstanding exists not only in the consumer and audiophile worlds but also in some education establishments and even some professionals. This misunderstanding comes from supposition of how digital audio works rather than how it actually works. It's easy to see in a photograph the difference between a low bit depth image and one with a higher bit depth, so it's logical to suppose that higher bit depths in audio also means better quality. This supposition is further enforced by the fact that the term 'resolution' is often applied to bit depth and obviously more resolution means higher quality. So 24bit is Hi-Rez audio and 24bit contains more data, therefore higher resolution and better quality. All completely logical supposition but I'm afraid this supposition is not entirely in line with the actual facts of how digital audio works. I'll try to explain:
When recording, an Analogue to Digital Converter (ADC) reads the incoming analogue waveform and measures it so many times a second (1*). In the case of CD there are 44,100 measurements made per second (the sampling frequency). These measurements are stored in the digital domain in the form of computer bits. The more bits we use, the more accurately we can measure the analogue waveform. This is because each bit can only store two values (0 or 1), to get more values we do the same with bits as we do in normal counting. IE. Once we get to 9, we have to add another column (the tens column) and we can keep adding columns add infinitum for 100s, 1000s, 10000s, etc. The exact same is true for bits but because we only have two values per bit (rather than 10) we need more columns, each column (or additional bit) doubles the number of vaules we have available. IE. 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024 .... If these numbers appear a little familiar it is because all computer technology is based on bits so these numbers crop up all over the place. In the case of 16bit we have roughly 65,000 different values available. The problem is that an analogue waveform is constantly varying. No matter how many times a second we measure the waveform or how many bits we use to store the measurement, there are always going to be errors. These errors in quantifying the value of a constantly changing waveform are called quantisation errors. Quantisation errors are bad, they cause distortion in the waveform when we convert back to analogue and listen to it.
So far so good, what I've said until now would agree with the supposition of how digital audio works. I seem to have agreed that more bits = higher resolution. True, however, where the facts start to diverge from the supposition is in understanding the result of this higher resolution. Going back to what I said above, each time we increase the bit depth by one bit, we double the number of values we have available (EG. 4bit = 16 values, 5bit = 32 values). If we double the number of values, we halve the amount of quantisation errors. Still with me? Because now we come to the whole nub of the matter. There is in fact a perfect solution to quantisation errors which completely (100%) eliminates quantisation distortion, the process is called 'Dither' and is built into every ADC on the market.
Dither: Essentially during the conversion process a very small amount of white noise is added to the signal, this has the effect of completely randomising the quantisation errors. Randomisation in digital audio, once converted back to analogue is heard as pure white (un-correlated) noise. The result is that we have an absolutely perfect measurement of the waveform (2*) plus some noise. In other words, by dithering,
allthe measurement errors have been converted to noise. (3*).
Hopefully you're still with me, because we can now go on to precisely what happens with bit depth. Going back to the above, when we add a 'bit' of data we double the number of values available and therefore halve the number of quantisation errors. If we halve the number of quantisation errors, the result (after dithering) is a perfect waveform with halve the amount of noise. To phrase this using audio terminology, each extra bit of data moves the noise floor down by 6dB (half). We can turn this around and say that each bit of data provides 6dB of dynamic range (*4). Therefore 16bit x 6db = 96dB. This 96dB figure defines the dynamic range of CD. (24bit x 6dB = 144dB).
So, 24bit does add more 'resolution' compared to 16bit but this added resolution doesn't mean higher quality, it just means we can encode a larger dynamic range. This is the misunderstanding made by many. There are no extra magical properties, nothing which the science does not understand or cannot measure. The only difference between 16bit and 24bit is 48dB of dynamic range (8bits x 6dB = 48dB) and
nothing else. This is not a question for interpretation or opinion, it is the provable, undisputed logical mathematics which underpins the very existence of digital audio.
So, can you actually hear any benefits of the larger (48dB) dynamic range offered by 24bit? Unfortunately, no you can't. The entire dynamic range of some types of music is sometimes less than 12dB. The recordings with the largest dynamic range tend to be symphony orchestra recordings but even these virtually never have a dynamic range greater than about 60dB. All of these are well inside the 96dB range of the humble CD. What is more, modern dithering techniques (see 3 below), perceptually enhance the dynamic range of CD by moving the quantisation noise out of the frequency band where our hearing is most sensitive. This gives a percievable dynamic range for CD up to 120dB (150dB in certain frequency bands).
You have to realise that when playing back a CD, the amplifier is usually set so that the quietest sounds on the CD can just be heard above the noise floor of the listening environment (sitting room or cans). So if the average noise floor for a sitting room is say 50dB (or 30dB for cans) then the dynamic range of the CD starts at this point and is capable of 96dB (at least) above the room noise floor. If the full dynamic range of a CD was actually used (on top of the noise floor), the home listener (if they had the equipment) would almost certainly cause themselves severe pain and permanent hearing damage. If this is the case with CD, what about 24bit Hi-Rez. If we were to use the full dynamic range of 24bit and a listener had the equipment to reproduce it all, there is a fair chance, depending on age and general health, that the listener would die instantly. The most fit would probably just go into coma for a few weeks and wake up totally deaf. I'm not joking or exaggerating here, think about it, 144dB + say 50dB for the room's noise floor. But 180dB is the figure often quoted for sound pressure levels powerful enough to kill and some people have been killed by 160dB. However, this is unlikely to happen in the real world as no DACs on the market can output the 144dB dynamic range of 24bit (so they are not true 24bit converters), almost no one has a speaker system capable of 144dB dynamic range and as said before, around 60dB is the most dynamic range you will find on a commercial recording.
So, if you accept the facts, why does 24bit audio even exist, what's the point of it? There are some useful application for 24bit when recording and mixing music. In fact, when mixing it's pretty much the norm now to use 48bit resolution. The reason it's useful is due to summing artefacts, multiple processing in series and mainly headroom. In other words, 24bit is very useful when recording and mixing but pointless for playback. Remember, even a recording with 60dB dynamic range is only using 10bits of data, the other 6bits on a CD are just noise. So, the difference in the real world between 16bit and 24bit is an extra 8bits of noise.
I know that some people are going to say this is all rubbish, and that “I can easily hear the difference between a 16bit commercial recording and a 24bit Hi-Rez version”. Unfortunately, you can't, it's not that you don't have the equipment or the ears, it is not humanly possible in theory or in practice under any conditions!! Not unless you can tell the difference between white noise and white noise that is well below the noise floor of your listening environment!! If you play a 24bit recording and then the same recording in 16bit and notice a difference, it is either because something has been 'done' to the 16bit recording, some inappropriate processing used or you are hearing a difference because you expect a difference.
G
1 = Actually these days the process of AD conversion is a little more complex, using oversampling (very high sampling frequencies) and only a handful of bits. Later in the conversion process this initial sampling is 'decimated' back to the required bit depth and sample rate.
2 = The concept of the perfect measurement or of recreating a waveform perfectly may seem like marketing hype. However, in this case it is not. It is in fact the fundamental tenet of the Nyquist-Shannon Sampling Theorem on which the very existence and invention of digital audio is based. From WIKI: “In essence the theorem shows that an analog signal that has been sampled can be
perfectlyreconstructed from the samples”. I know there will be some who will disagree with this idea, unfortunately, disagreement is NOT an option. This theorem hasn't been invented to explain how digital audio works, it's the other way around. Digital Audio was invented from the theorem, if you don't believe the theorem then you can't believe in digital audio either!!
3 = In actual fact these days there are a number of different types of dither used during the creation of a music product. Most are still based on the original TPDFs (triangular probability density function) but some are a little more 'intelligent' and re-distribute the resulting noise to less noticeable areas of the hearing spectrum. This is called noise-shaped dither.
4 = Dynamic range, is the range of volume between the noise floor and the maximum volume.
Microsoft brengt .Net naar Linux en OS X en maakt .Net Server Core opensource
The Ebola epidemic: Is there a way out?
Partners AMD gaan R9 290X met 8 GB geheugen uitbrengen

YouTube rolt ondersteuning voor video met 60fps uit - update
Why plants don't get sunburn
Conspicuous tRNA lookalikes riddle the human genome

Nageslacht bij vliegen beïnvloed door eerdere sekspartners

A tiny group of people can see ‘invisible’ colours that no-one else can perceive (bbc.com)
DNA in 'gene deserts' linked with breast cancer
Bètaversie Counter-Strike: Global Offensive verkrijgbaar voor Linux - update
Counter-Strike: Global Offensive to Finally Arrive on Linux
softpedia: The Linux version of Counter-Strike: Global Offensive seems to have been in the works for ages, but now there is finally some news about it, although it's nothing definitive.
Oxford Nanopore MinION Data from E.Coli K-12 Genome is here

Oxford Nanopore MinION (Image: Nick Loman)
The wait is over. The long sought after data from Oxford Nanopore is here. Almost three months ago, we got a glimpse of a single read from Nick Loman. Now, Nick Loman organizing the really awesome Nanopore themed Google Hangout and announced that Oxford Nanopore MinION data from E.Coli K 12 substrain.
The E. coli genome data from Nanopore MinION data is available from GigaDB. In addition to directly downloading the data from Gigadb, one can also download using Aspera.
The raw data is about 80 Gb in size, while processed data in fasta format is about 180Mb and easy to download..
Bacterial whole-genome read data from the Oxford Nanopore Technologies MinION™ nanopore sequencer.
Quick, J; Loman N.J (2014): Bacterial whole-genome read data from the Oxford Nanopore Technologies MinION™ nanopore sequencer. GigaScience Database. http://dx.doi.org/10.5524/100102
The MinION is a new, portable single-molecule sequencer developed by Oxford Nanopore Technologies. It measures four inches in length and is powered from the USB 3.0 port of a laptop computer. By measuring the change in resistance produced when DNA strands translocate through and interact with a protein nanopore the device is able to deduce the underlying nucleotide sequence.
Here we present a read dataset from whole-genome shotgun sequencing of the model organism Escherichia coli K-12 substr. MG1655 generated on a MinION device with R7 chemistry during the early-access MinION Access Program (MAP).
Three sequencing runs of the MinION were performed using R7 chemistry. The first run produced 43,656 forward reads (272Mb), 23,338 (125Mb) reverse reads, 20,087 two-direction (2D) reads (131Mb), of which 8% (10Mb) were full 2D. Full 2D reads means that the complementary strand was successfully slowed through the pore.
The R7 protocol has a modification to increase the relative number of full 2D reads (NONI). To exploit this, two new libraries were produced which included an overnight incubation stage (ONI-1 and ONI-2). Each library was run on an individual flow cell. This resulted in 6,534 & 8,260 forward reads, 2,171 & 2,945 reads and 1,740 & 2,394 2D reads (27%, 29%). In this case, 50% and 41.8% of reads were full 2D respectively. The mean fragment lengths for 2D reads from the three libraries were 6,543 (NONI) 6,907 (ONI-1) and 6,434 (ONI-2).
Raw and assembled sequence data is provided to demonstrate the nature of data produced by the MinION™ platform and to encourage the development of customised methods for alignment and variant calling, de novo assembly and scaffolding. FAST5 files containing event data within the HDF5 container format are provided to assist with the development of improved base-calling methods.
Building a deeper understanding of images
The ImageNet large-scale visual recognition challenge (ILSVRC) is the largest academic challenge in computer vision, held annually to test state-of-the-art technology in image understanding, both in the sense of recognizing objects in images and locating where they are. Participants in the competition include leading academic institutions and industry labs. In 2012 it was won by DNNResearch using the convolutional neural network approach described in the now-seminal paper by Krizhevsky et al.[4]
In this year’s challenge, team GoogLeNet (named in homage to LeNet, Yann LeCun's influential convolutional network) placed first in the classification and detection (with extra training data) tasks, doubling the quality on both tasks over last year's results. The team participated with an open submission, meaning that the exact details of its approach are shared with the wider computer vision community to foster collaboration and accelerate progress in the field.
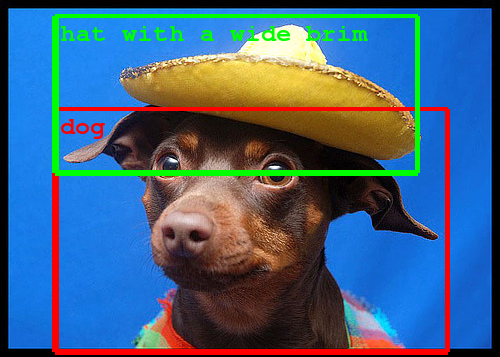
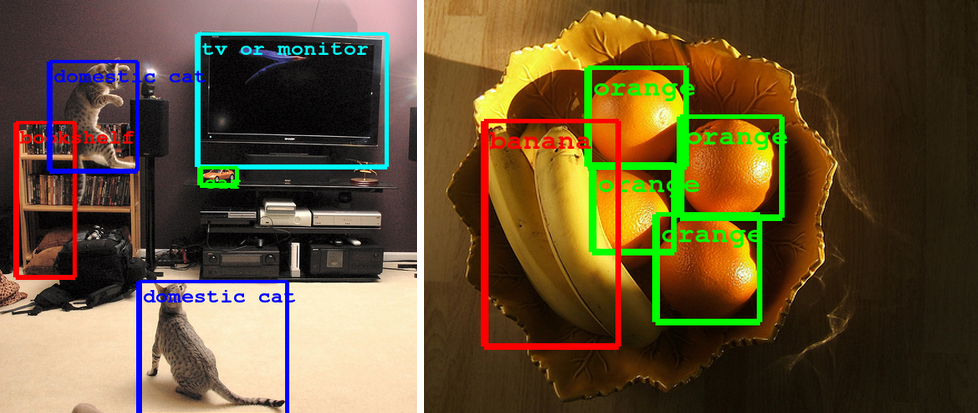
This effort was accomplished by using the DistBelief infrastructure, which makes it possible to train neural networks in a distributed manner and rapidly iterate. At the core of the approach is a radically redesigned convolutional network architecture. Its seemingly complex structure (typical incarnations of which consist of over 100 layers with a maximum depth of over 20 parameter layers), is based on two insights: the Hebbian principle and scale invariance. As the consequence of a careful balancing act, the depth and width of the network are both increased significantly at the cost of a modest growth in evaluation time. The resultant architecture leads to over 10x reduction in the number of parameters compared to most state of the art vision networks. This reduces overfitting during training and allows our system to perform inference with low memory footprint.

These technological advances will enable even better image understanding on our side and the progress is directly transferable to Google products such as photo search, image search, YouTube, self-driving cars, and any place where it is useful to understand what is in an image as well as where things are.
References:
[1] Erhan D., Szegedy C., Toshev, A., and Anguelov, D., "Scalable Object Detection using Deep Neural Networks", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 2147-2154.
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J., "Rich feature hierarchies for accurate object detection and semantic segmentation", arXiv preprint arXiv:1311.2524, 2013.
[3] Howard, A. G., "Some Improvements on Deep Convolutional Neural Network Based Image Classification", arXiv preprint arXiv:1312.5402, 2013.
[4] Krizhevsky, A., Sutskever I., and Hinton, G., "Imagenet classification with deep convolutional neural networks", Advances in neural information processing systems, 2012.
'Topuniversiteit leidt tot extreme ongelijkheid'
Gratis tram groot succes voor arme ouderen
DNA nets could be 'ancient defence weapon'
Robb Calum T., Robert D. Gray, Adriano G. Rossi, & Valerie J. Smith. (2014) Invertebrate extracellular phagocyte traps show that chromatin is an ancient defence weapon. Nature Communications. DOI: http://dx.doi.org/10.1038/ncomms5627
Invertebrate extracellular phagocyte traps show that chromatin is an ancient defence weaponUpdate: How Ebola Kills

Eman Gokpolu (with little Larry, named for my husband) is our African “son.” He sends frequent updates from Liberia.
UPDATE OCT. 7: Emmanuel (my “son”) and his family, in Liberia, are still all healthy! The post below is from mid-August, when much of the US still didn’t care about Ebola because it wasn’t here. It includes the immune system basics that rarely make it into media coverage.
Sunday, August 17:
Eman’s emails arrive hours ahead of the news here.
“An Ebola quarantine site was attacked and looted. News is that most of the patients have escaped. This is going to put more fear into the population. All this because people are denying the virus. More people might get exposed. I’m so weak I can’t wake up this morning. Its 6:00 pm and I am still in bed listening to the news. All this happened in a very populated area called West Point. Got pain all over my body. Keep me in your meditations.”

As a medical student Eman can’t treat people. Instead, he is a “sensitizer,” educating people on how to avoid infection.
Emmanuel is a medical student in Liberia whom my husband and I have been supporting since he contacted me after reading my human genetics textbook in 2007. Until the fever hit him last weekend, he dedicated himself to “sensitization,” educating the public about how to stay safe. But now he’s too sick and weak to venture out.
His email from Monday, August 18, said only “Need help!”
Eman is our son in the African sense, not based on his DNA. And our families have grown close. Some of the funds we sent to see him through medical school helped put his mother through nursing school. It costs a fraction of medical education here.
The emails and texts from Liberia are eerie in the face of the crumbling infrastructure, the abandoned hospitals and schools. Eman taps on a phone these days, too terrified to use an Internet cafe as he has in the past. We know he’s in trouble when his brother Joseph takes over — it means Eman is in the hospital. It’s happened for cholera, amoebiasis, and cerebral malaria more than once. Fighting infection is a way of life in Liberia.
I’m mortified when the news here focuses on the deaths of individuals — tragic as they may be — while the populations of African nations like Liberia, of the entire continent, are under threat. Eman wants to know why the US didn’t pay attention until the arrival here of two patients, who were treated. So do I.
JUST 7 GENES
The stark seeming-simplicity of the Ebola virus flashes across my mind whenever I receive an email from Eman.
Ebola virus has a mere 7 protein-encoding genes, but the RNA that is its genetic material holds hidden information. One key gene (GP, for glycoprotein) has an overlapping reading frame so that an alternate form harbors a stretch of added adenines. And the encoded protein is cut after translation, generating a mature secreted form that sits on the surfaces of viral particles, as well as a sugar-coated smaller part, like a moon carved from a planet.

(Wikimedia Commons)
The irony of it all is stunning. Genetics and genomics journals overflow with data. Always more exomes, more genomes, meta-analyses of meta-analyses that search for meaning among the nearly limitless combinations of variants of our 20,000 or so genes. And yet a 7-gene “infectious particle,” so streamlined it isn’t even a cell, isn’t even alive, can reduce a human body to a puddle, inner barriers dissolving into nothingness, within days.
How does Ebola virus, so much simpler than influenza, than HIV, do it?
AN EBOLA TIMELINE
Ebola virus homes to certain immune system cells as well as the boxy epithelial cells that aggregate into layers and the single bathroom-tile-like endothelial cells. Inside the body, the virus first tackles innate immunity – the immediate and generalized response to infection. Ebola commandeers monocytes and macrophages, the wandering cells that travel around the body, dividing, distributing its deadly cargo.
Meanwhile, the virus replicates like crazy.

(Wikimedia Commons)
In those who will not survive, the innate immune response goes on a tad too long. The virus also invades dendritic cells. These are the sentries that “present” the pathogen’s provoking antigens to the parts of the immune system that carry out the second phase, the slower and targeted adaptive response. And indirectly, mysteriously, lymphocytes die en masse, instead of producing antibodies.
Yet at the same time, a “cytokine storm” erupts, sending other arms of the immune response into overdrive. Levels of gamma interferon, interleukins 2 and 10, and tumor necrosis factor soar, triggering fever and flu-like symptoms. Yet it’s as if there’s no interferon at all. Viruses do not see it.
The bizarre immune response during Ebola infection is rightfully termed “paradoxical,” at once too slow, too little, too intense.
Then the body’s barriers begin to break down.
The endothelial cells that curl into the tiny tubes that are the capillaries, and also line the interiors of larger blood vessels, contort into blobs. Holes appear. Barriers melt away, and the fluids that they contained redistribute. The still-crazily-replicating virus now has direct access to organs, favoring the adrenal cortex (plunging blood pressure), the kidneys, gonads, spleen, and most dangerous, the liver.

(Wikimedia)
The final stage is the bleeding, as the liver’s output of clotting factors becomes unhinged. One protein in particular goes by various names: in the older literature it’s simply “tissue factor,” but is also known as thromboplastin, CD142, and factor III.
Whatever it’s called, this cell surface glycoprotein converts prothrombin into thrombin, the essential final step in blood clotting. The fact that no deficiency of thromboplastin is known – the others cause hemophilias and other clotting disorders – belies its importance.
In Ebola infection, thromboplastin is too active, ushering in disseminated intravascular coagulation. Tiny clots form in blood vessels everywhere. Organ necrosis sets in as the blood supply ebbs, and clotting factors needed to stanch greater breaches as the blood vessels come apart become depleted. Hemorrhaging begins as the biochemical balance so critical to appropriate clotting vanishes.

Nicotiana benthamiana, the tobacco plant in which ZMapp is made. Thanks, GMOs!
BACK TO THE GENES
A human body overwhelmed with Ebola virus is like a castle whose defenses fail, from the inside out, all orchestrated by that puzzling handful of genes.
GP targets the virus to certain cell types, deforms the endothelium, and destroys antigen presentation. ZMapp, the drug being given to a handful of infected people ahead of human testing because it worked in macaques, counters GP. It consists of three monoclonal antibodies produced in tobacco cells.

Gamma interferon
VP24 cuts off the host transcription factor STAT1, which is required to use gamma interferon, according to a recent report in Cell Host & Microbe. And VP40 protein, because it forms the outside of the virus, should elicit an antibody response, only it usually doesn’t.
The power of a virus such as Ebola tends to evoke anthropomorphism. But the virus isn’t intentionally trying to kill people, as one prominent researcher told the New York Times, calling the virus “a survivor. It does what it can to avoid the human immune system.” It doesn’t think.
Another type of survivor might provide the clues necessary to stop the current epidemic: people whose immune systems can fight off the virus.
LEARNING FROM SURVIVORS
Just as HIV antivirals were developed using clues from people who never became infected despite repeated exposure, a solution to Ebola hemorrhagic fever might lie among individuals who recover.
Survivors have 10 million viruses per milliliter of blood serum; people who succumb have 10 billion. So far we know that the immune response in people who survive is subtly distinctive, the innate response turning off at a specific point and the adaptive response beginning in time to help, neither becoming overactive. Identifying biomarkers may reveal the specifics that drive resistance, such as an adhesion factor that re-attaches torn endothelium.
 Ebola hemorrhagic fever is the consequence of runaway viral replication against a backdrop of a strangely deranged immune response. We know the viral genome sequence, and I’m sure the genome sequences of survivors are being or will soon be sequenced. I hope it is only a matter of time until researchers deduce how variations of the 20,000-gene human genome or its expression resist the 7-gene genome of Ebola virus, and figure out how to replicate the response.
Ebola hemorrhagic fever is the consequence of runaway viral replication against a backdrop of a strangely deranged immune response. We know the viral genome sequence, and I’m sure the genome sequences of survivors are being or will soon be sequenced. I hope it is only a matter of time until researchers deduce how variations of the 20,000-gene human genome or its expression resist the 7-gene genome of Ebola virus, and figure out how to replicate the response.
Until they do, I’m petrified. I just got an email sent from Eman’s phone — from Joseph, August 20.
“Eman walked to the hospital today because according to him, he is not doing well. He called me up in pain. Luckily, its not Ebola. We were so scared. He’s admitted. No word yet. I will keep you informed. Joseph”
Update Sunday August 24: Eman is still in the hospital, but he “only” has hookworms and malaria (which he always seems to have). When he gets out tomorrow, he plans to volunteer with MSF to fight Ebola.
The post Update: How Ebola Kills appeared first on DNA Science Blog.
New material could enhance fast, accurate DNA sequencing
Dying To Make Us Laugh
C.R. Epstein, R.J. Epstein. (2013) Death in The New York Times: the price of fame is a faster flame . QJM: monthly journal of the Association of Physicians, 106(6), 517-521. info:/
Greengross G. (2013) Humor and aging - a mini-review. Gerontology, 59(5), 448-53. PMID: 23689078
Humor and aging - a mini-review.Ferner RE, & Aronson JK. (2013) Laughter and MIRTH (Methodical Investigation of Risibility, Therapeutic and Harmful): narrative synthesis. BMJ (Clinical research ed.). PMID: 24336308
Laughter and MIRTH (Methodical Investigation of Risibility, Therapeutic and Harmful): narrative synthesis.Bennett MP, & Lengacher C. (2009) Humor and Laughter May Influence Health IV. Humor and Immune Function. Evidence-based complementary and alternative medicine : eCAM, 6(2), 159-64. PMID: 18955287
Humor and Laughter May Influence Health IV. Humor and Immune Function.Who said beer is just for drinking?
Chen, W., Becker, T., Qian, F., & Ring, J. (2014) Beer and beer compounds: physiological effects on skin health. Journal of the European Academy of Dermatology and Venereology, 28(2), 142-150. DOI: 10.1111/jdv.12204
Beer and beer compounds: physiological effects on skin healthThe Story Behind Acquisition of MySQL by Sun Microsystem and the Rise of MariaDB
tecmint: A database is an information organized in such a fashion that a computer program can access the stored data or a part of it.