David Anes
Shared posts
31 Mar 21:08
Debut podium “feels like a win” – Magnussen | 2014 Australian Grand Prix
by Keith Collantine
Kevin Magnussen said he was thrilled to finish on the podium in his first race for McLaren - and give the team its first top-three finish since 2012.







30 Mar 23:39

KlayGE Announces DXBC2GLSL, a HLSL bytecode to GLSL compiler
We are glad to announce the DXBC2GLSL, an open source library that convert the HLSL bytecode (DXBC) to GLSL. The inputs of DXBC2GLSL is SM5 bytecodes (also compatible to SM4). After parsing, input variables, output variables, texture declaration and shader instructions can be retrieved. The output GLSL can be VS/PS/GS in OpenGL 2.0 to 4.4. HS/DS/CS support, and an OpenGL ES version is currently under development. Theoretically, this framework can even convert compute shader to OpenCL.
30 Mar 07:37
Live: 2014 Malaysian Grand Prix | F1 Fanatic Live
by Keith Collantine
Follow the 2014 Malaysian Grand Prix on F1 Fanatic Live.




11 Dec 11:32

If you try to declare a variadic function with an incompatible calling convention, the compiler secretly converts it to cdecl
by Raymond Chen - MSFT
Consider the following function on an x86 system:
void __stdcall something(char *, ...);
The function declares itself as __stdcall,
which is a callee-clean convention.
But a variadic function cannot be callee-clean since the callee
does not know how many parameters were passed,
so it doesn't know how many it should clean.
The Microsoft Visual Studio C/C++ compiler resolves this conflict
by silently converting the calling convention to __cdecl,
which is the only supported variadic calling convention
for functions that do not take a hidden this parameter.
Why does this conversion take place silently rather than generating a warning or error?
My guess is that it's to make the compiler options
/Gr (set default calling convention to __fastcall)
and
/Gz (set default calling convention to __stdcall)
less annoying.
Automatic conversion of variadic functions to __cdecl
means that you can just add the /Gr or /Gz
command line switch to your compiler options, and everything will
still compile and run (just with the new calling convention).
Another way of looking at this is not by thinking of the compiler
as converting variadic __stdcall to __cdecl
but rather by simply saying
"for variadic functions, __stdcall is caller-clean."
Exercise:
How can you determine which interpretation is what the compiler actually does?
In other words, is it the case that the compiler converts
__stdcall to __cdecl for variadic functions,
or is it the case that the calling convention for variadic
__stdcall functions is caller-clean?
01 Oct 08:49
Call for a new Post-Processing Pipeline - KGC 2013 talk
by noreply@blogger.com (Wolfgang Engel)
David AnesSólo por las referencias está de PM
This is the text version of my talk at KGC 2013.

The main motivation for the talk was the idea of looking for fundamental changes that can bring a modern Post-Processing Pipeline to the next level.
Let's look first into the short history of Post-Processing Pipelines, where we are in the moment and where we might be going in the near future.




Let's look first into the short history of Post-Processing Pipelines, where we are in the moment and where we might be going in the near future.
History
Probably one of the first Post-Processing Pipelines appeared in the DirectX SDK around 2004. It was a first attempt to implement HDR rendering. I believe from there on we called a collection of image space effects at the end of the rendering pipeline Post-Processing pipeline.
The idea was to re-use resources like render targets and data with as many image space effects as possible in a Post-Processing Pipeline.
A typical collection of screen-space effects were
- Tone-mapping + HDR rendering: the tone-mapper can be considered a dynamic contrast operator
- Camera effects like Depth of Field with shaped Bokeh, Motion Blur, lens flare etc..
- Full-screen color filters like contrast, saturation, color additions and multiplications etc..
One of the first coverages of a whole collection of effects in a Post-Processing Pipeline running on XBOX 360 / PS3 was done in [Engel2007].
Since then numerous new tone mapping operators were introduced [Day2012], new more advanced Depth of Field algorithms with shaped Bokeh were covered but there was no fundamental change to the concept of the pipeline.
Call for a new Post-Processing Pipeline
Let's start with the color space: RGB is not a good color space for a post-processing pipeline. It is well known that luminance variety is more important than color variety, so it makes sense to pick a color space that has luminance in one of the channels. With the 11:11:10 render targets it would be cool to store luminance in one of the 11 bit channels. Having luminance available in the pipeline without having to go through color conversions opens up many new possibilities, from which we will cover a few below.
Global tone mapping operators didn't work out well in practice. We looked at numerous engines in the last four years and a common decision by artists was to limit the luminance values by clamping them. The reasons for this were partially in the fact that the textures didn't provide enough quality to survive a "light adaptation" without blowing out or sometimes most of their resolution was in the low-end greyscale values and there wasn't just enough resolution to mimic light adaptations.
Another reason for this limitation was that the available resolution in the rendering pipeline with the RGB color space was not enough. Another reason for this limitation is the fact that we limited ourselves to Global tone mapping operators, because local tone mapping operators are considered too expensive.
A fixed global gamma adjustment at the end of the pipeline is partially doing "the same thing" as the tone mapping operator. It applies a contrast and might counteract the activities that the tone-mapper already does.
So the combination of a tone-mapping operator and then the commonly used hardware gamma correction, which are both global is odd.
On a lighter note, a new Post-Processing Pipeline can add more stages. In the last couple of years, screen-space ambient occlusion, screen-space skin and screen-space reflections for dynamic objects became popular. Adding those to the Post-Processing Pipeline by trying to re-use existing resources need to be considered in the architecture of the pipeline.
Last, one of the best targets for the new compute capabilities of GPUs is the Post-Processing Pipeline. Saving memory bandwidth by merging "render target blits" and re-factoring blur kernels for thread group shared memory or GSM are considerations not further covered in the following text; but most obvious design decisions.
Let's start by looking at the an old Post-Processing Pipeline design. This is an overview I used in 2007:

A Post-Processing Pipeline Overview from 2007
A few notes on this pipeline. The tone mapping operation happens at two places. At the "final" stage for tone-mapping the final result and in the bright-pass filter for tone mapping the values before they can be considered "bright".
The "right" way to apply tone mapping independent of the tone mapping operator you choose is to convert into a color space that exposes luminance, apply the tone mapper to luminance and then convert back to RGB. In other words: you had to convert between RGB and a different color space back and forth twice.
In some pipelines, it was decided that this is a bit much and the tone mapper was applied to the RGB value directly. Tone mapping a RGB value with a luminance contrast operator led to "interesting" results.
Obviously this overview doesn't cover the latest Depth of Field effects with shaped Bokeh and separated near and far field Center of Confusion calculations, nevertheless it shows already a large amount of render-target to render-target blits that can be merged with compute support.
All modern rendering pipelines calculate color values in linear space; meaning every texture that is loaded is converted into linear space by the hardware, then all the color operations are applied like lighting and shadowing, post-processing and then at the end the color values are converted back by applying the gamma curve.
This separate Gamma Control is located at the end of the pipeline, situated after tone mapping and color filters. This is because the GPU hardware can apply a global gamma correction to the image after everything is rendered.
The following paragraphs will cover some of the ideas we had to improve a Post-Processing Pipeline on a fundamental level. We implemented them into our Post-Processing Pipeline PixelPuzzle. Some of the research activities like finally replacing the "global tone mapping concept" with a better way of calculating contrast and color will have to wait for a future column.
Yxy Color Space
The first step to change a Post-Processing Pipeline in a fundamental way is to switch it to a different color space. Instead of running it in RGB we decided to use CIE Yxy through the whole pipeline. That means we convert RGB into Yxy at the beginning of the pipeline and convert back to RGB at the end. In-between all operations run on Yxy.
With CIE Yxy, the Y channel holds the luminance value. With a 11:11:10 render target, the Y channel will have 11 bits of resolution.
Instead of converting RGB to Yxy and back each time for the final tone mapping and the bright-pass stage, running the whole pipeline in Yxy means that this conversion might be only done once to Yxy and once or twice back to RGB.
Tone mapping then still happens with the Y channel in the same way it happened before. Confetti's PostFX pipeline offers eight different tone mapping operators and each of them works well in this setup.
Now one side effect of using Yxy is also that you can run the bright-pass filter as a one channel operation, which saves on modern scalar GPUs some cycles.
One other thing that Yxy allows to do is to consider the occlusion term in Screen-Space Ambient Occlusion as a member of the Y channel. So you can mix in this term and use it in interesting ways. Similar ideas apply to any other occlusion term that your pipeline might be able to use.
The choice of using CIE Yxy as the color space of choice was arbitrary. In 2007 I evaluated several different color spaces and we ended up with Yxy at the time. Here is my old table:

Pick a Color Space Table from 2007
Compared to CIE Yxy, HSV doesn't allow easily to run a blur filter kernel. The target was to leave the pipeline as unchanged as possible when picking a color space. So with Yxy, all the common Depth of Field algorithms and any other blur kernel runs unchanged in Yxy. HSV conversions also seem to be more expensive compared to RGB -> CIE XYZ -> CIE Yxy and vice versa.
There might be other color spaces similar tailored to the task.
Dynamic Local Gamma
As mentioned above, the fact that we apply a tone mapping operator and then later on a global gamma operator appears to be a bit odd. Here is what the hardware is supposed to do when it applies the gamma "correction".

Gamma Correction
The main take-away from this curve is that the same curve is applied to every pixel on screen. In other words: this curve shows an emphasis on dark areas independently of the pixel being very bright or very dark.
Whatever curve the tone-mapper will apply, the gamma correction might be counteracting it.
It appears to be a better idea to move the gamma correction closer to the tone mapper, making it part of the tone mapper and at the same time apply gamma locally per pixel.
In fact gamma correction is considered depending on the light adaptation level of the human visual system. The "gamma correction" that is applied by the eye changes the perceived luminance based on the eye's adapatation level [Bartleson 1967] [Kwon 2011].
When the eye is adapted to dark lighting conditions, the exponent for the gamma correction is supposed to increase. If the eye is adapted to bright lighting conditions, the exponent for the gamma correction is supposed to decrease. This is shown in the following image taken from [Bartleson 1967]:
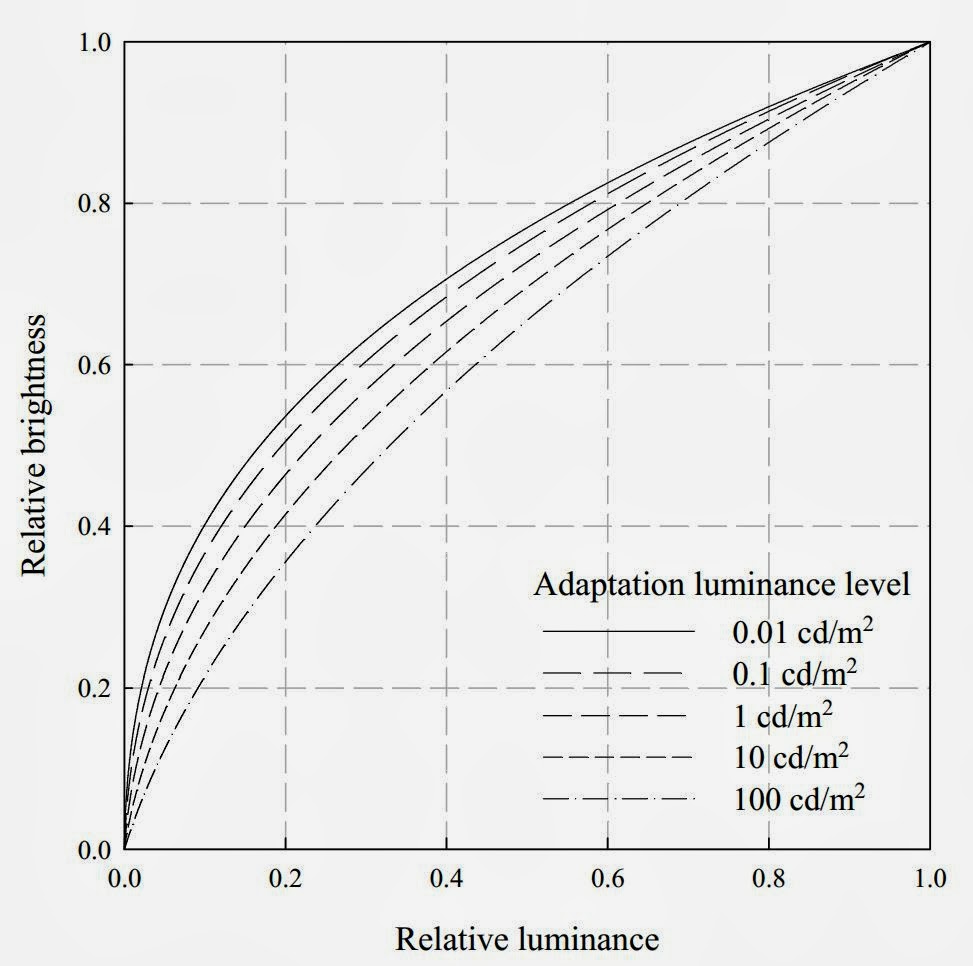
Changes in Relative Brightness Contrast [Bartleson 1967]
A local gamma value can vary with the eye's adaptation level. The equation that adjusts the gamma correction following the current adaptation level of the eye can be found in [Kwon 2011].
γv=0.444+0.045 ln(Lan+0.6034)
For this presentation, this equation was taken from the paper by Kwon et all. Depending on the type of game there is an opportunity to build your own local gamma operator.
The input luminance value is generated by the tone mapping operator and then stored in the Y channel of the Yxy color space:
YYxy=Lγv
γv changes based on the luminance value of the current pixel. That means each pixels luminance value might be gamma corrected with a different exponent. For the equation above, the exponent value is in the range of 0.421 to 0.465.

Applied
Gamma Curve per-pixel based on luminance of pixel
•Eye’s adaptation == low - >blue
curve
•Eye’s adaptation value == high
-> green curve
Lγv
works with any tone mapping operator. L is the luminance value coming from the tone mapping operator.
works with any tone mapping operator. L is the luminance value coming from the tone mapping operator.
With a dynamic local gamma value, the dynamic lighting and shadowing information that is introduced in the pipeline will be considered for the gamma correction. The changes when going from bright areas to dark areas appear more natural. Textures are holding up better the challenges of light adaptation. Overall lights and shadows look better.
Depth of Field
Depth of Field
As a proof-of-concept of the usage of Yxy color space and the local dynamic gamma correction, this section is showing screen-shots of a modern Depth of Field implementation with separated near and far field calculations and a shaped Bokeh, implemented in compute.
Producing an image through a lens leads to a "spot" that will vary in size depending on the position of the original point in the scene:


Producing an image through a lens leads to a "spot" that will vary in size depending on the position of the original point in the scene:
Circle of Confusion (image taken from Wikipedia)
The Depth of Field is the region, where the CoC is less than the resolution of the human eye (or in our case the resolution of our display medium). The equation on how to calculate the CoC [Potmesil1981] is:

Following the variables in this equation, Confetti demonstrated in a demo at GDC 2011 [Alling2011] the following controls:
- F-stop - ratio of focal length to aperture size
- Focal length – distance from lens to image in focus
- Focus distance – distance to plane in focus
Because the CoC is negative for far field and positive for near field calculations, separate results are commonly generated for the near field and far field of the effect [Sousa13].
Usually the calculation of the CoC is done for each pixel in a down-sampled buffer or texture. Then the near and far field results are generated. Then, first, the far and focus field results are combined and then this result is combined with the near field, based on a near field coverage value. The following screenshots show the result of those steps, with the first screenshot showing the near and far field calculations:




[Day2012] Mike Day, “An efficient and user-friendly tone mapping operator”, http://www.insomniacgames.com/mike-day-an-efficient-and-user-friendly-tone-mapping-operator/
[Engel2007] Wolfgang Engel, “Post-Processing Pipeline”, GDC 2007 http://www.coretechniques.info/index_2007.html
[Kwon 2011] Hyuk-Ju Kwon, Sung-Hak Lee, Seok-Min Chae, Kyu-Ik Sohng, “Tone Mapping Algorithm for Luminance Separated HDR Rendering Based on Visual Brightness Function”, online at http://world-comp.org/p2012/IPC3874.pdf
[Potmesil1981] Potmesil M., Chakravarty I. “Synthetic Image Generation with a Lens and Aperture Camera Model”, 1981
[Reinhard] Erik Reinhard, Michael Stark, Peter Shirley, James Ferwerda, "Photographic Tone Reproduction for Digital Images", http://www.cs.utah.edu/~reinhard/cdrom/
[Sousa13] Tiago Sousa, "CryEngine 3 Graphics Gems", SIGGRAPH 2013, http://www.crytek.com/cryengine/presentations/cryengine-3-graphic-gems
Usually the calculation of the CoC is done for each pixel in a down-sampled buffer or texture. Then the near and far field results are generated. Then, first, the far and focus field results are combined and then this result is combined with the near field, based on a near field coverage value. The following screenshots show the result of those steps, with the first screenshot showing the near and far field calculations:

Red = max CoC(near field CoC)
Green = min CoC(far field CoC)
Here is a screenshot of the far field result in Yxy:

Far field result in Yxy
Here is a screenshot of the near field result in Yxy:

Near field result in Yxy
Here is a screenshot of resulting image after it was converted back to RGB:

Resulting Image in RGB
Conclusion
A modern Post-Processing Pipeline can benefit greatly from being run in a color space that offers a separable luminance channel. This opens up new opportunities for an efficient implementation of many new effects.
With the long-term goal of removing any global tone mapping from the pipeline, a dynamic local gamma control can offer more intelligent gamma control that is per-pixel and offers a stronger contrast of bright and dark areas, considering all the dynamic additions in the pipeline.
Any future development in the area of Post-Processing Pipelines can be focused on a more intelligent luminance and color harmonization.
References
[Alling2011] Michael Alling, "Post-Processing Pipeline", http://www.conffx.com/GDC2011.zip
[Bartleson 1967] C. J. Bartleson and E. J. Breneman, “Brightness function: Effects of adaptation,” J. Opt. Soc. Am., vol. 57, pp. 953-957, 1967.[Alling2011] Michael Alling, "Post-Processing Pipeline", http://www.conffx.com/GDC2011.zip
[Day2012] Mike Day, “An efficient and user-friendly tone mapping operator”, http://www.insomniacgames.com/mike-day-an-efficient-and-user-friendly-tone-mapping-operator/
[Engel2007] Wolfgang Engel, “Post-Processing Pipeline”, GDC 2007 http://www.coretechniques.info/index_2007.html
[Kwon 2011] Hyuk-Ju Kwon, Sung-Hak Lee, Seok-Min Chae, Kyu-Ik Sohng, “Tone Mapping Algorithm for Luminance Separated HDR Rendering Based on Visual Brightness Function”, online at http://world-comp.org/p2012/IPC3874.pdf
[Potmesil1981] Potmesil M., Chakravarty I. “Synthetic Image Generation with a Lens and Aperture Camera Model”, 1981
[Reinhard] Erik Reinhard, Michael Stark, Peter Shirley, James Ferwerda, "Photographic Tone Reproduction for Digital Images", http://www.cs.utah.edu/~reinhard/cdrom/
[Sousa13] Tiago Sousa, "CryEngine 3 Graphics Gems", SIGGRAPH 2013, http://www.crytek.com/cryengine/presentations/cryengine-3-graphic-gems
Rafa.gaitan, David Anes likes this
22 Sep 18:56

Russia in 15 seconds Best comment: “Im glad they filmed...
Russia in 15 seconds
Best comment: “Im glad they filmed this during the summer, in the winter it gets depressing sometimes.”
13 Sep 00:09














Terraria llega a Android: tala, cava y modifica el mundo para sobrevivir
by Adrian Raya

Con el lanzamiento de Minecraft nació una moda entre los videojuegos centrada en la posibilidad de poder crear nuestros propios mundos, además de un aumento de popularidad del estilo “retro”, o inspirado en los gráficos de sprites aunque fuese en un entorno tridimensional. De todos los clones y copias de Minecraft, salieron algunos juegos que supieron encontrar su propia identidad y que aún hoy en día son buenos. Por ejemplo Terraria.

Originalmente lanzado en PC, por fin podemos disfrutar de una versión adaptada a nuestros dispositivos Android, y la verdad es que tenía muchos miedos ante esta versión. Y es que en su entorno original, el PC, Terraria es un juego diseñado para el teclado y el ratón, con el que controlar a nuestro personaje al mismo tiempo que vamos cambiando de utensilios y organizando nuestro inventario. El resultado final puede que no sea tan completo como la versión de ordenadores, pero la verdad es que es un buen trabajo, gracias al cual Terraria puede controlarse perfectamente con una pantalla táctil.

Pero, ¿qué es Terraria? En este juego controlamos a un personaje en medio de un enorme mundo en 2D. Con las herramientas apropiadas podemos conseguir recursos de prácticamente todo lo que se encuentra a nuestro alrededor. Podemos coger un hacha y talar árboles para conseguir madera, podemos coger un pico y obtener valiosos minerales. Y por supuesto, no faltan las armas para enfrentarnos a los enemigos, monstruos de tendencias nocturnas que nos pondrán las cosas difíciles pero que también sueltan elementos interesantes.

Como podéis ver, este es un juego con muchas similitudes con Minecraft, pero sobre todo la mayor es esa sensación de que todo es posible con el inventario adecuado. Se trata de un juego de exploración, construcción y descubrimientos que puede llegar a enganchar bastante si no tenemos cuidado. El mayor punto negativo del juego es que uno de los mejores apartados del original, su modo multijugador, se ha quedado por el camino.
Terraria es gratuito, pero recibiremos mensajes constantes para obtener la versión de pago, que cuesta 3.76€.
El artículo Terraria llega a Android: tala, cava y modifica el mundo para sobrevivir se publicó en El Androide Libre (El Blog Android de referencia. Aplicaciones, noticias, Juegos y smartphones Android Libres)
    
|
03 Sep 08:59

—Señoras, señores, la situación es la siguiente. Dentro de veintiocho días, el asteroide Seymour impactará con la Tierra. Dentro de veinticuatro horas, una nave con una tripulación especialmente capacitada despegará con la misión de interceptar este asteroide y hacerle entrega del Premio Nobel de la Paz que se le ha concedido.
Asteroide
by Andrés Diplotti
—Señoras, señores, la situación es la siguiente. Dentro de veintiocho días, el asteroide Seymour impactará con la Tierra. Dentro de veinticuatro horas, una nave con una tripulación especialmente capacitada despegará con la misión de interceptar este asteroide y hacerle entrega del Premio Nobel de la Paz que se le ha concedido.
Sergio Vernis likes this

19 Jul 17:07
Frank Krueger: Calca OS X Now Available & Code Reuse
by Frank_x0020_Krueger@monologue.go-mono.com
Calca is my latest app - a text editor and computer algebra system happily married together. The reaction to Calca has been overwhelmingly positive. I am very excited that people are finding it useful. Make sure to leave reviews and tell your friends. :-)
Anyway, I’m please to announce today that the OS X version of Calca is available. In this form, Calca really shines. It’s the same powerful engine as before, but it’s much easier to manipulate text documents on Mac and it can handle much larger documents.
I was even able to put in some convenience features from IDEs: matching parenthesis highlighting, matching identifier highlighting, and indent and commenting keys. The app is also iCloud enabled so all your Calca for iOS work is available. I hope you enjoy it!
Following the tradition of iCircuit, I want to take a few minutes to report how much code reuse I was able to attain between the iOS version and the Mac version. To do so, I simply ran the Code Share Measurement Script. It produced the following raw data:
app t u s u% s% Mac 12253 916 11337 7.48 % 92.52 % iOS 14227 2890 11337 20.31 % 79.69 %
We can see that Calca’s engine - the shared code - is 11,337 lines of code. One could say it’s an elite engine.
Here is a picture showing that same data. The code in green is shared, while the code in red had to be written specifically for that platform.
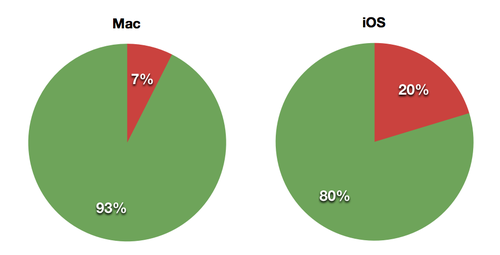
This is showing that the UI code of the iOS version is nearly 3,000 lines of code compared to 1,000 lines for the Mac version. The iOS version’s UI is 3 times as big as the Mac’s.
Why is the iOS code so much bigger than the Mac’s? One answer: file management.
iOS human interface guidelines ask developers to minimize the use of the file system in normal interactions with our apps. To that end, there are no UI controls specifically designed for file management. There are no directory browsers, no file open or save dialog boxes, no UI to simply rename files. All of this has to be coded per application by the developer.
On iOS, Apple stands over your shoulder commenting “look how much effort it takes to write a document based application, are you sure you want to do it this way?"
On OS X, Apple wants you to make document based applications and gives you a fully working one with essentially no code. Honestly, I’m surprised that it took 916 lines of code to write the Mac UI - the UI is very simple with all the smarts hidden behind a text editor. There are a lot of “tricks" in that code to make the editing experience pleasant - most of which involves tricking the text editor into behaving itself.
This is the general lesson I’ve learned over the years: writing iOS apps is a hell of a lot more work than writing Mac apps. Enlightening? No. Honest? Yeah.
I wrote this app, as I do all my apps, using C# and Xamarin tools. I want to take a moment to thank them for their awesome product. Calca was a labor of love and it was wonderful to use my favorite tools to create it.
Jose L. Hidalgo, David Anes likes this
19 Jul 16:37

Duetto (C++ for the Web): CMake integration, Bullet and WebGL demo
by Alessandro Pignotti
At LeaningTech we have been working hard and it’s time for some news and updates on the development of duetto, our tool for programming the Web in C++.
Thanks to some key developments that we are about to describe, we managed to compile our first real-world test case in Javascript, the bullet physics library — and a small demo in webGL that takes advantage of it.
The compilation of bullet in JS with duetto requires very minimal adaptation to the vanilla code, and can be easily performed in full integration with CMake infrastructure. We built a minimal demo to show the result of our tool in action: a triangle falling on the ground attracted by gravity. Please note that the demo is completely not optimized, not even by minimizing the JS. Any performance must be considered preliminary and there is vast room for improvement that we plan to fully exploit
http://leaningtech.com/duettodemo/HelloWorld.html
This was our first trial at compiling a complex codebase, and it went surprisingly smoothly!
The following features are now fully supported in duetto:
- A fully working libc and libc++
Our current beta features a full implementation of the standard C library (based on the newlib implementation) and of the standard C++ library (based on the LLVM/libc++). Both libraries are standard implementations, support for duetto was included using the same infrastructure used for other, native, targets.
- Integration in the CMake/autotool toolchain as a target
Duetto is now fully integrated with the CMake, using the infrastructure normally used for cross compiling (i.e toolchain definition files). This means you can compile complex projects that use CMake with little effort. We also plan to integrate with autotools in the future.
- Full support of the DOM and HTML5 APIs (such as WebGL)
Our latest beta features an improved support for using the DOM and WebGL API from C++. This is done by defining a set of headers which allows to transparently access all the browser DOM and libraries. It is also very easy to add support for any JS libraries, following the same approach.
Four months have passed since our initial post about duetto. At that time we promised what we would have released our brainchild in a six months time frame. Well, I’m very happy to say that we are fully in schedule and we will be able to release duetto in the fall, under a dual licensing scheme: open-source for open-source and non-commercial use, and a paid license for commercial use.
We have already started sharing a limited private beta with a few developers and are interested in expanding its release to some more, if interested please contact us at info@leaningtech.com
26 Jun 22:25
 [written by Seth Robinson]
[written by Seth Robinson]
Two guys made an MMO: The Growtopia postmortem
by Staff
[written by Seth Robinson]So, being the master of game marketing that I am, I've carefully been totally silent here on my blog about my latest game, despite being released five months ago.
The game now regularly hits 3,000 players online at once and has been financially a huge success. (At least by my humble standards!) It's been a top 1000 grossing US App Store game for the past four months and doing similarly well on Android - all without being featured and zero paid advertising.
Today I'm finally sitting down to document how this project took shape as well as the trials and tribulations.
September 8th, 2012: Six pictures
After my highly competitive multiplayer online game Tanked was more or less finished, I began thinking aboutduct a new game. Something that would capitalize on the networking client/server experience I'd gained but apply it to a fresh idea with simpler controls that would be more accessible.
Despite Tanked being 3D, I decided to do the game in 2D - faster development and we could target even very crappy mobile devices.
With Tanked, I felt my fatigue in "doing it all, alone" was the cause of my non-existent marketing efforts (I've STILL never done a youtube video for Tanked? REALLY?!?!), as well as reluctance to add the final layers of polish. I needed a partner, someone to provide a mutual motivation as well as handle the artistic needs of the project.
So with that in mind, I presented six mock-up screenshots to long-time IRC pal and fellow indie, Mike Hommel, aka Hamumu to entice him to come aboard.
Here are the original shots (created using stolen sprite rips mostly) for your viewing displeasure (I'm no artist!):


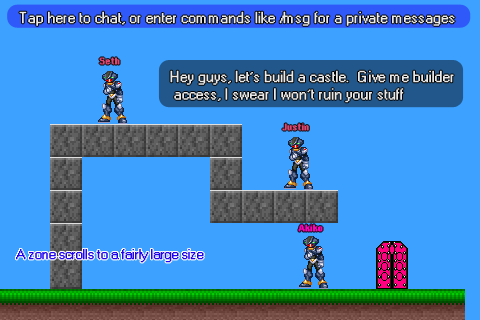
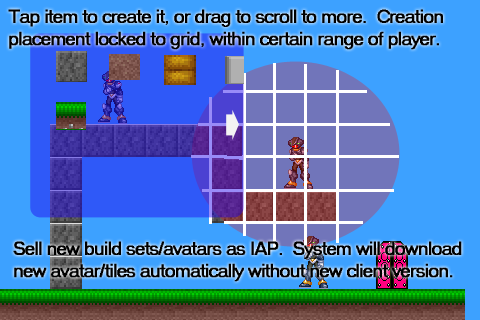

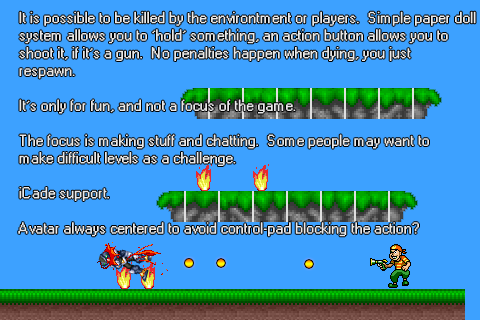
We changed and improved the ideas represented in these mockups over time, but stayed focused on the general goals.
He agreed to give it a shot. Like so many indie collaborations, I suspect he was worried we'd never reach beta. Hell, me too!
I think I predicted 4-6 months to finish it. This is usually where I would chuckle at my foolish naivety and admit it took years longer than expected but... not this time?!
The reason things went so smoothly? Well, I guess probably because we had very few "unknowns".
In the past, we'd both already made 2d tile based platformers, collision code, networked games, mysql based projects and websites, and done cross platform development. Using my Proton SDK insured we could run on eight platforms (nearly) out of the box.
We figured the only real unknown was what our max player limit would be and how things would scale up. I had guessed conservatively, 600 players online would be our max. Luckily, I was wrong, the original server actually was able to handle much more.
September 15th, 2012: Networking and collision are functional
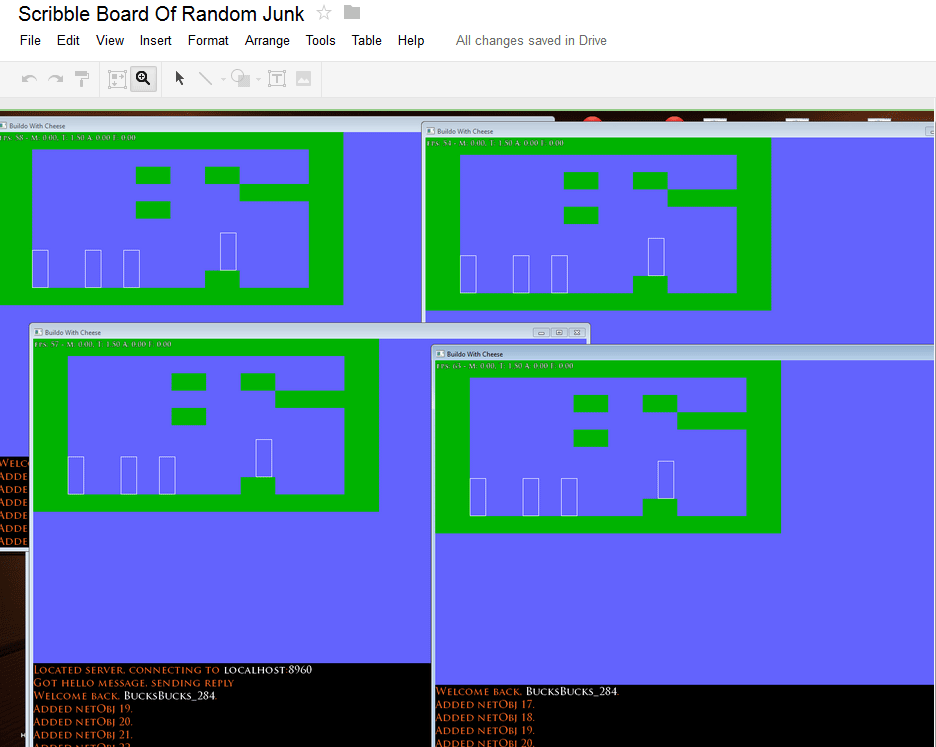
The above shot shows four instances running around in the same world. All graphics are just DrawRects for now. The collision is incredibly simple and as a result gives us very few problems later as we tweak it for special tiles and items later. The game is written in C++ with GL/GLES.
I think one reason this project went so fast is I was able to fight the urge to go overboard on everything like I usually do. There are no fancy 2d physics. I mean hey, we're not making Limbo here. It would be overkill. I think it helps that I had already done the box2d physics platformer thing in a previous project so I didn't really feel like I had something to prove, if that makes sense.
I've never actually met Mike in person, he's in California and I'm in Japan. But if anything, that probably helped - we work on the code base (he programs too!) in (roughly) day/night shifts which help avoid svn code conflicts.
We use IRC and Google Docs to communicate - spreadsheets for tracking hours and financial stuff, and the drawing board to share screenshots and ideas. The best part is we have a full history of everything we've done, that's where I'm getting most of the screenshots for this article!
September 21st, 2012: GUI designs

The GUI starts to take shape via Hamumu's mockups.
October 18th, 2012: Doors, signs, chat, inventory, and one kind of lock working
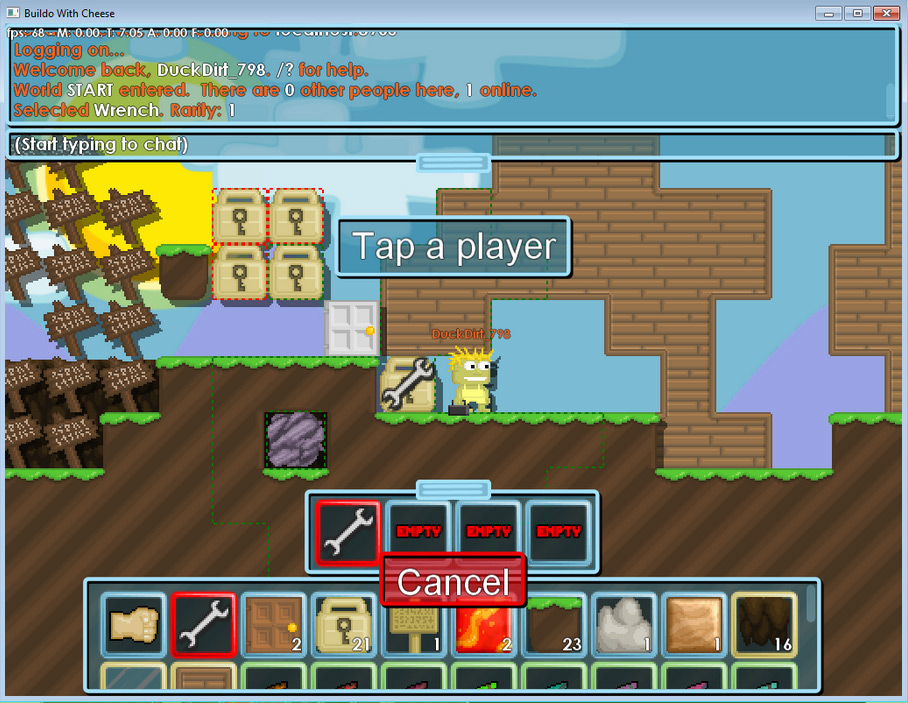
In roughly five weeks, the game looks pretty similar to its current form.
November 30th, 2012: The game is stealth-released on Android as a free beta after three months of development
We were unable to use the original name we wanted (Buildo) as someone else was sort of already using it. After a VERY painful few days we finally agree on Growtopia. I really couldn't get anything done during that period, strange that stress of finding a game name could grind everything to a halt like that. I was never totally satisfied with the name, but it's very searchable so that's a perk. The domain name was taken so we had to live with growtopiagame.com.

IAP is disabled initially as we expected to reset the universe a few times. (We ended up never having to do that)
There were no "World Locks" yet, so people tended to clump together in little towns, locking their areas with the smaller lock types.
Despite the total stealth release (I didn't even mention the beta on my website) the player base quickly grows. It's the perfect design for PR slackers like us, very viral in nature due to the social aspects.
January 9th, 2013: The game is released on iOS, and the word beta is removed from the Google Play description
The release! We get a boost from Touch Arcade, Pocket Gamer and IndieGames who all post our teaser video. (we sent it to them and a few other sites, that was pretty much it for our marketing campaign)
We stress out as we watch the users online grow. 200 users, 300 users.. 600 users online at once! Will the server die? We upgrade our server three times in two weeks to handle the increase, wondering if after the initial surge we'll need to go back to the cheaper one. Servint, our data center, did a great job of quickly migrating us from server to server as needed.
Life after release, where we are now
Like a newborn, we found the game screaming for our non-stop attention. We find ourselves constantly putting out fires and dealing with issues. 600 hundred forum posts a day to read, hundreds of daily support emails.
There is no finish line, there is no "done" - we've basically worked full time on the game since its release.
Our game has an extremely sensitive virtual economy that could be decimated in only hours by a rampant bug.
A single server crash can cause an hour of lost work per player online. A single day roll-back on a busy day now would mean instantly vaporizing SEVEN HUMAN YEARS worth of effort.
These things weighed very heavily on me in the beginning. I had trouble sleeping and would check the server throughout the night to make sure it was still running correctly. After a while though, you sort of reach a certain level of numbness/comfort with it all.
I guess I'll forgo the usual "what went right/wrong" and just illuminate the most important/damaging events and how we dealt with them.
Our first penis
Well, we knew it had to happen. I appeared in their world and gave them five minutes to remove it, but secretly I was sort of proud, it's sort of a developer achievement to have someone miss-use your creative tools like this.

As our player count grew, we found our player discipline tools inadequate. Over time we beefed them up.
The problem with tape

Instead of simply muting people, we thought it would be much cooler to visually duct-tape their mouth shut. When they attempt to speak, only muffled noises come out.
The end result wasn't what we expected. Being duct-taped quickly became the goal. When players saw us, they'd mob us yelling obscenities, hoping to be taped. We had to make a new rule: "If you try to get taped on purpose, we'll just ban you" to keep it under control.
The item duping
Due to a bug a patch introduced, it became possible to log on with two instances of the same player for a short while if you did it at EXACTLY the perfect time. Within hours a group of Asian players had figured it out and were duping like mad. I remember using google translate on Growtopia related Korean message boards trying to figure out the method used.

Knowing it was happening, but not understanding the modus operandi was VERY stressful, we had to spy and watch them doing it. We figured it out and patched the server. We hand deleted the ill-gotten gains as best we could (we didn't want to roll back!), but it quickly becomes impossible to track as items are traded. For a while, we had the server report anyone with > 100 world locks and we'd just assume they were holding duped items and punish the account. Nowadays that wouldn't work because many legitimate players have earned that much wealth through normal gameplay.
The bedrock bug
One day fairly early in Growtopia's lifetime (I think it was still in the wide beta on android) we made a horrible mistake with user security levels which let anybody destroy bedrock and white doors. (Normally a player can't destroy these tiles, as means player can fall out of the world at the bottom, and can't enter worlds the normal way)
Twenty minutes had passed before I'd noticed the frenzied broadcasts that excitedly shared the bug - not only were people destroying normally impenetrable blocks, those blocks were giving seeds, which would grow into trees that would eventually yield more of the forbidden blocks, letting the user place them!
This bug really didn't cause too much damage, but we were running around fixing holes in levels and replacing missing entrance doors for weeks. We also added a filter that would remove those items from peoples inventories.. but I wouldn't be surprised if there is still a bedrock tree growing somewhere out there and you do still see the occasional bedrock piece missing from older worlds.
The IAP hackers - "Someone is giving away world locks"
Like most developers, I've grown used to the idea knowing that people are pirating my games. I don't stress too much, it doesn't ruin the experience of others for the most part.
But if thousands of dollars worth of gems are stolen via fraudulent means, it has a real impact on us as it is pumped into the game economy.
We'd watch would-be thieves dump their contraband in remote locations. We'd wait (invisibly) and see who came to pick it up, track down the persons main hideout and ban them all. Eventually we upgraded our server to do full IAP receipt checking, but life had a certain cops 'n robbers taste to it for a while.
We still have issues with stolen credit cards and chargebacks, but it's now at manageable levels for the most part.
The Tapjoy hack
Tapjoy is a great way to let players watch a 20 second commercial, to buy gems using their time, and only if they choose to. (They get 90 gems, we get 5 cents, or whatever) However, due to me using it wrong (similar to IAP, I was using my code from previous single player games I worked on rather than custom stuff with full server verification) it was very vulnerable to client hacks, as illustrated in the image.
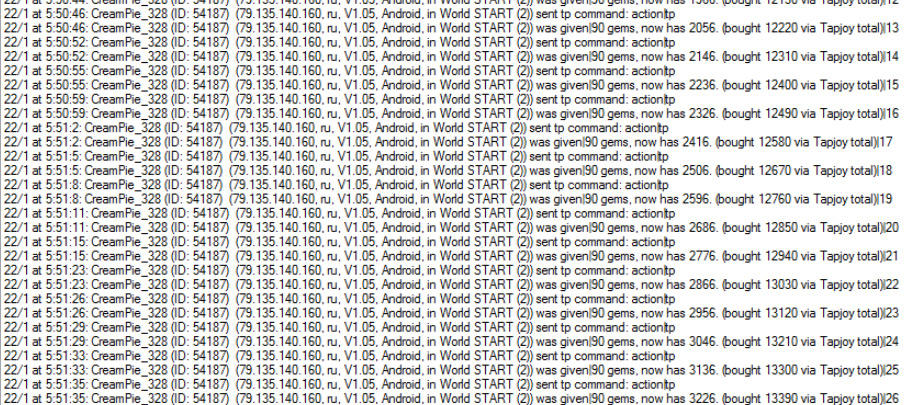
I wasted a lot of time writing code to detect hacks and such, when I should have just re-implemented Tapjoy the correct way, which I eventually did anyway. It now runs flawlessly.
Scamtopia
The virtual economy made item trading and bartering very important. The original release had no secure way to trade, only "drop trading". Naturally scamming was prevalent. We told people "Never drop trade with people you don't know!"
We introduced a robust trading system as quick as we could.
The blueberry hack
Due to a server vulnerability, it was possible to hack a client to give you unlimited blueberries. (Basically, when using it to eat, a special case happened where it didn't check if you actually had any left)
We were perplexed why a certain group of players had so many blueberries, it didn't make sense... someone eventually emailed us and explained the trick and we quickly patched it. Thanks, sir.
The wall hack
It turns out the first thing that people do in a game like this is use a memory scanning utility (a "trainer") to locate important memory addresses (speed, X/Y position, etc) and modify them. We realized wall hacking would be possible, but didn't think it was a big deal due to our lock/ownership systems. (If someone gets into your locked area, it doesn't really matter, the server wouldn't let them take anything)
However, players liked to drop items around their worlds, which presented juicy targets for wall hackers. We quickly combated this with clever server + client hacks which worked pretty well, but in the end we removed all doubt by adding full A* path finding on every single player movement. (this wasn't possible for speed reasons until the V2 server upgrade.. more on that later)
The black day - the rollback
But it wasn't the hackers or credit card fraud that did the worst damage. It was us!
On February 23th our worst nightmare became a reality. We'd inadvertently made some changes that caused certain very cheap items to give out a high number of gems when "recycled", this created an infinite money loop. As soon as it was noticed, someone "broadcasted" it which meant every single person online knew how to earn unlimited gems. The entire economy was trashed in only minutes.
We had to roll back almost 24 hours worth. (We do automated backups daily.. and sometimes I do extra backups before a serious patch, but today I didn't for some reason)
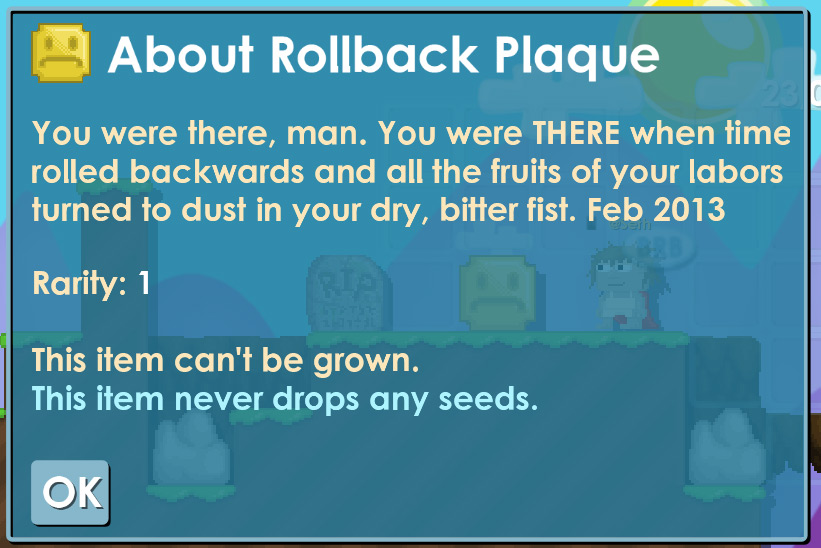
That weekend was dubbed "Apology Weekend" and we worked quickly to add perks and gems bonuses to try to make it up to the players. If you ever see a "Rollback Plaque", it was earned by someone on that weekend. We wrote a program to restore all gem purchases that had been wiped, with double the gems.
This was a wake-up call to more seriously test things before patching. It's tough trying to surprise your audience with something new (we're very secretive) and yet wanting to properly test it. We now do have a fully functional beta test server that we can route normal players into.
That day was easily the absolute worst for me personally. I'm happy to say we haven't had another roll-back yet.
Too many users
In mid April we hit 2,000 concurrent users on weekends and our server began to buckle. Round trip to punch something could take a full second and people were constantly being disconnected. We added live profiling support and narrowed down the slow down to world creation and enet packet sorting.
We decided I would write a "V2 server" upgrade in a separate svn branch that would take advantage of multiple cores; it made no sense that our hardware had 16 cores and 32 threads but our entire Growtopia server process was run in a single thread.
Meanwhile, Mike would handle running active game and adding items and preparing to move them over to the new server.
We had a lot riding on the V2 server, would it really solve our problems or fail miserably? It's very difficult to fake 2,000 users, so we released a client upgrade that could smoothly switch between the old server and the new beta one.
When things looked good, we just pushed a button and switched the real database over to the new server, if it died, we could just switch them back. Anyway, it worked beautifully and we haven't outgrown it yet.
Here's how I explained it to users on our Facebook page: (it was actually only a software change, we didn't change hardware. But this was the result as far as latency and gameplay)

The freemium dilemma
After railing against slimy abuses of the freemium model myself, I vowed to do it 'right'. Here is what we did:
- -Only one soft currency, that can be earned in the game.
- -No paywalls, you really can get every single thing in the game without buying stuff. But more than that, the game is fun and works fine without paying - no slogging along at a snail's pace and grinding required to do stuff.
- -$10 is the biggest IAP.
- -$30 limit per day limit to help situations like "my kid bought $500 of stuff accidentally", as far as I know, no major mobile freemium companies do this, but really, they all should! Actually, Apple should probably send a "ARE YOU SURE? Click OK to allow more IAP in this game" type email after anybody spends too much in a game to verify it wasn't a mistake or a kid.
- -No annoying push messages, spamming, email sharing, etc
- -No popups asking you to buy stuff. No pressure selling. Don't buy stuff, you really don't have to.
- -The expensive status/vanity items don't have any special powers as compared to the cheap items, they just look different, which in a situation with hundreds of thousands of players to compare items with, is a real value, of sorts. The rarity creates the value.
- -We don't want whales, we want schools of tiny fish who will pop in a few bucks now and then. If a customer ends up spending 5 cents an hour that would be great, and I think a decent value.
- -We want to make enough to continue working on the game and adding content/events instead of the normal "release and forget" model.
A few times we saw someone making daily purchases that seemed strangely high and emailed their Google purchasing account email directly to verify that everything was ok. (We thought it might be a kid using a parents' device) I don't think we ever got a reply. I think Apple and Google should be doing the emailing really, they have more and better information than we do. We will disable IAP on any account by request. (the option won't even show up in the store in that case)
I think overall we "did it fairly right", but I still have moral reservations about this model and know that we're exploiting certain kinds of vulnerable individuals due to the nature of open-ended purchases, even if you don't need them. In a single player game I don't think it would ever be justified to extract $100 in IAP, but in an MMO where we have players with 1,000+ hours logged and who purchase presents for others, I think it isn't totally unreasonable for an informed adult to spend that much.
But what is the line?
This is game where a kid can do a /broadcast and instantly be visited by fifty or more REAL people hanging on his every word because a prize is going to be given away. He or she can run any kind of game within Growtopia and have complete control over these guests, ordering them around and banning at will. I'm proud we created mechanics that allow something this amazing but also humbled by the damage this power could do to someone vulnerable. My own son (he's nine) has spent $40 of his own money in Growtopia over the 200+ hours he's played. He's given most of it away to his "friends".
If he's learned a real friend doesn't require a World Lock, maybe it was a worthy investment.
Giving away too much
A problem with our single currency is you can make around $3 of IAP per hour farming in the game. Our richest player has never spent a dime, and has $1000 usd worth of gems. I'm sort of proud of that on one hand, it illustrates our game is REALLY free and not a trick. But on the other hand, I don't know what he should spend his 1,000,000+ gems on. If we add a 100,000 gem "Vanity item" in the store, eight year olds are also going to be pressured to use IAP to buy that essentially worthless item to keep up with the Jones'. (Worthless as far as functionality, but .. well, the value as trading power due to the rarity and cost is very real in a multiplayer society like this one)
It will be a challenge to figure all this out.
Email support system woes
Originally we handled support emails by replying and bcc'ing eachother. This .. doesn't scale up very well. Eventually we setup with desk.com and now we can give much better service. When a customer forgets to tell us his GrowID, we can just look through his history and grab it.

The future
It's not yet written, John!
All I know for sure is I chose the perfect person to collaborate with and our combined efforts have definitely resulted in superpowers. Llike when spandex wearing heroes stand close together they can shoot larger balls of lightning. It's like that but totally different.
In the five months since Growtopia's release we've had 3.5 million+ worlds created by nearly 400,000 users. Last Saturday we set the record with 65,000+ hours logged in a single day.
I don't see any shortage of ways to improve the heart of Growtopia, which is about giving useful tools to the player to let him or her be creative with both strangers and friends; but each addition and tweak is now taking increasingly long to test and safely deploy due to the size and scope of the existing user base. We can't make any mistakes now, especially with huge additions going in this weekend. No rollbacks.
-Seth
Growtopia was created by Seth A. Robinson and Mike Hommel.
David Anes, Toni and 2 others like this
16 Jun 07:14
La Unión Europea eliminará el roaming en 2014
by rwx
La Comisión Europea ha decidido eliminar el roaming a partir de 2014. Se cumple así la petición de Neelie Kroes, vicepresidenta de la Comisión Europea y responsable de Telecomunicaciones, y los europeos no tendrán coste adicional en su tarifa mientras se encuentren en un país de la Unión Europea. El 1 de julio de 2014 entrará en vigor la medida.
Las llamadas, los mensajes de texto o el acceso a Internet no supondrán ningún coste adicional al usuario. La Comisión sin embargo no ha dejado claro cómo gestionará el coste de estos servicios, o cómo aplicará la reforma a los diferentes servicios móviles
Julio.campos.alvarez, likes this

14 Jun 21:21
Garbage Can That Looks Like the Mac Pro Is a Hot Item in Japan
by Brian Ashcraft

You know how people are comparing the new Mac Pro to a garbage can? Turns out one Japanese garbage can is already reaping the rewards.
Below, you can see the Mac Pro. No, strike that. Below, you can see a garbage bin by Osaka-based design firm Ideaco. It really, really looks like the new Mac Pro!

Dubbed the Ideaco New Tubelor, it looks so much like the Mac Pro that the bin, which was first launched in 2006, apparently just shot up the Amazon Japan rankings.
Amazon Japan's official Twitter account even jokingly tweeted that the Ideaco garbage can "was not the new Mac Pro".
The gag worked. That tweet was retweeted over thirteen thousand times and favorited nearly three thousand times. And currently, this garbage can is ranked number deux in the online retailer's interior furniture best sellers. It's also Amazon Japan's best selling garbage can.
There are also the inevitable funny Amazon reviews, with people "warning" that this was in fact a garbage can and pointing out that it could not run Thunderbolt 2. There was even a wry worry about how the black cylinder could show dust.
But as one Amazon Japan reviewer noted, "It does have the innovative ability to hide the plastic bag by a concealing cover." Shame it can't run Thunderbolt, though!
ゴミ箱 ブラック [Amazon Japan via まとめまとめ]
Kotaku East is your slice of Asian internet culture, bringing you the latest talking points from Japan, Korea, China and beyond. Tune in every morning from 4am to 8am.
To contact the author of this post, write to bashcraftATkotaku.com or find him on Twitter @Brian_Ashcraft.
12 Jun 16:12





Hyperkin Retron 5, la consola ideal para los jugadores mas nostálgicos que emula consolas clásicas
by Adrian Raya

Hasta ahora ya habíamos visto muchas consolas basadas en Android, todas ellas aproximadamente con las mismas características: bajo precio, hardware modesto, y acceso a al menos parte del catálogo de juegos de Google Play. La consola de la que hablamos hoy, sin embargo, es muy diferente, y es que no tiene como objetivo simplemente jugar en pantalla grande a los mismos títulos que podemos en nuestros smartphones, sino que está basada completamente en la nostalgia.
La Hyperkin Retron 5 no solo tiene un nombre que parece salido directamente de los años 90: su catálogo de juegos también es de esa época. Y es que, ejecutando una ROM modificada de Android, este modelo es capaz de emular cinco consolas clásicas. Para ello, en la parte superior cuenta con ranuras de cartuchos en las que podemos introducir nuestros clásicos. Aunque la Retron 5 no es la primera consola retro que permite usar los juegos originales, la novedad de ésta es la inteligente mezcla entre emulación por hardware y por software.

Y es que aunque permite cartuchos originales y parte de la placa base simula aquellas de las consolas originales, la mayor parte del trabajo se hace por el software incluido en la ROM basada en Android. Esto tiene muchas ventajas, la principal que es fácilmente actualizable a a través de Internet, por lo que cada vez mas títulos serán compatibles conforme pase el tiempo. Otras ventajas incluyen los filtros de vídeo para suavizar la imagen, o para mejorar la relación de aspecto en pantallas panorámicas.

La Hyperkin Retron 5 cuenta con ranuras de cartuchos de la Nintendo (o NES), la Famicom (la versión japonesa de la NES), Super Nintendo, Sega Mega Drive, y Game Boy. Además, también podemos usar los mandos originales de la NES, la Super NES, y la Mega Drive gracias a sus puertos originales en uno de los lados, aunque si lo preferimos podemos conectar un mando por Bluetooth. La salida de vídeo es por HDMI y tiene ranura para tarjetas SD. Su lanzamiento está previsto para finales de verano por un precio menor de 100 dólares, aunque estos son datos provisionales y es de esperar que se concreten con el tiempo.
Fuente | Engadget
El artículo Hyperkin Retron 5, la consola ideal para los jugadores mas nostálgicos que emula consolas clásicas se publicó en El Androide Libre (El Blog Android de referencia. Aplicaciones, noticias, Juegos y smartphones Android Libres)
|
|
D.informaticabit, Joan Blasco likes this




{kind=link}
29 May 12:10


Duetto (C++ for the Web): comparison to asm.js and other clarifications
by Alessandro Pignotti
Around a month ago we posted a first overview of Duetto: our integrated LLVM-based solution for programming both the client and the server side of Web applications using C++. We have been completely overwhelmed by the interest generated by that post!
We tried to keep track of the many insightful comments and constructive criticism we received on this blog and on aggregators. Here are the most common questions that arose:
1) Why didn’t you compare Duetto with asm.js?
We believe that comparing to asm.js-enabled code is not an apples-to-apples comparison. In the current state the Firefox asm.js Ahead-Of-Time compiler can only be enabled on code which is generated using the emscripten approach to memory allocation, so code generated by Duetto has no way to benefit from it. We are open to discuss how the asm.js approach of validating typed-ness of code AOT can be extended so that Duetto, and potentially other solutions, may benefit from it as well.
Still, it is clearly very interesting to compare Duetto performance to asm.js, so we have made a new round of benchmarking that includes it. The results are pretty interesting. As you can see, although asm.js is always faster than emscripten, there are cases in which Duetto on V8 outperforms asm.js (on Spidermonkey) as well. We think that this is caused by the highly efficient handling of objects that V8 provides and shows that there is no clear winner. It is very hard to predict what approach will perform better, and by how much, on real world scenarios.
For each benchmark the best time in 10 runs has been selected. The V8 and Spidermonky JavaScript shells have been used. The respective commits are b13921fa78ce7d7a94ce74f6198db79e075a2e03 and afb7995ef276. Flags: Emscripten (emcc –O2), Asm.js (emcc –O2 –s ASM_JS=1), Duetto and native (clang –fno-math-errno –O2). –fno-math-errno has been added for coherency with internal emcc flags. *The fasta benchmark has been modified by removing a memory allocation in a tight loop.
2) Emscripten is efficient because it effectively disables the Garbage Collector. How does Duetto handle dynamic memory?
Duetto maps C++ objects to native JS objects. This of course means that, every now and then, the GC will run. Emscripten handles memory by pre-allocating all the needed memory and then assigning slices of it using a malloc implementation. So yes, since the memory is not really dynamic it can avoid all the performance impact of the garbage collector
But this advantage does not come for free when you include memory consumption into account. Memory is a resource shared will all the other applications on the system, both native ones and other web apps. Eagerly reserving memory can have a large effect on the performance of the system as a whole.
While the GC may cause a sizeable overhead in terms of CPU cycles, it also decreases memory usage by freeing unneeded memory. Generally speaking, even when programming on traditional platforms, such as x86, dynamic memory allocations and deallocations should be avoided in performance sensitive code. Pre-allocating the required memory directly in the application code is indeed possible with Duetto as well.
Since I do not expect native platforms (i.e. GLibc) to preallocate gigs of memory at application startup to make it faster when dynamic memory is actually used, I do not expect this from a compiler for the JavaScript target either.
3) Is Duetto code interoperable with existing JS code, libraries and vice-versa?
Yes, absolutely. Methods compiled by Duetto can be exported using the regular C++ mangling or even without the mangling if they are declared as “extern C”. In both cases the can be freely invoked from pure JavaScript code. At the same time Duetto compiled code will be able to seamlessly access all the HTML5/DOM APIs and any JS function. The only requirement is that the JS interface needs to be declared in a C++ header.
We currently automatically generate the header for all the HTML5/DOM APIs using headers originally written for TypeScript. We also plan to write headers for the most popular JS libraries, but we would like to stress that the needed headers are just plain C++ class declarations and no special additional support in the compiler is required to support new APIs or new libraries. So when the newest and greatest Web API comes out anyone will be able to write the header to use it with Duetto.
4) Why don’t you release immediately?
Because we want to make the developer experience sufficiently polished before giving it to users. Anyone how had the misfortune of using buggy compiler will probably appreciate this. We plan to release it in 6 months from the previous post (so around 5 months from now, time flies) under a dual licensing scheme: as Open Source for open source and non commercial projects, and with a paid license for commercial development.
5) Will Duetto make reverse engineering of original code easy?
In Duetto, C++ code passes through the regular Clang/LLVM pipeline before being converted to JavaScript. This is the same path used to compile assembly for any other architecture, like x86 or ARM. The generated JavaScript is no easier to understand than the corresponding machine code or assembly. Moreover, one of the typical optimization steps for JavaScript, which we can employ as well, is ‘minimization’ which destroys any residual information about variables and method names.
6) Will other languages will be supported?
We choose to start from C++ because it’s a language that has proven to be good enough for very large scale projects and also because it’s the one we know best and love. Currently we have no plans to expand the Duetto architecture to other languages, but it is definitely possible that in the future, based on user demand, we could bring our awesome integrated client/server development model to other languages as well.
22 May 21:08
Fast resource loading
by repi
bool Manager::loadResources()
{
if (m_resourcesLoaded)
return true;
m_resourcesLoaded = true;
return true;
}
(Thanks for the submission Graham)
14 May 20:46

Integrating C++11 in your diet
by DEADC0DE
Even for a guy like me who despises C++ and is happy to escape from it as often as possible, the reality of daily work still involves mostly C++ programming.
Being "good" at C++ is mostly a matter of having a good diet. Of course you try to write "sane" C++, staying C as much as possible, using a "safe" subset of the language (1 2 3 etc...), using static code checkers (vs2012 analysis at least, even if I've found it to be quite lax) and so on, these things have been written over an over. The bottom line is, you find your subset of things that are usable and of rules that never should be broken.
Now, parts of the new C++11 standard are coming into mainstream compilers (read, Visual Studio 2012) and so I had to update my "diet" to incorporate a few new, useful features (mostly C++ trying to look like C#, which ain't bad).
This is my small list of things you should consider to start using (at least on PC, for tools etc...).
- Use today:
- Auto - Variable type inference. Really, makes a big difference in readability and it's essential for things like stl iterators and so on. It's "deeper" than just shorthand notation as well, as it infers type it always avoids nasty implicit conversions and forces you to write everything explicitly. Also, it propagates changes, so if you change a type (e.g. constness) of a function parameter, you don't have to waste time on all the local types. It also enables new things with templates (but who cares) and lambdas. Note: VaX now supports auto and it shows the inferred type!
- Lambdas - Simple, much better than function pointers, and also support closures which are the real deal, with a decent, explicit syntax. As C++ doesn't have garbage collection they have restrictions lambdas in other languages don't face, that's to say, you have to think of how you capture things and what are their lifetimes, but it's something we're used to by now (and made "easier" by the explicit capturing syntax, which forces you to think about what you're doing). Still you might want to fallback to regular functor objects when you need to make more explicit what you're doing in the "capturing" constructor/destructor but that's fine. Be sure to know what they really are (typeless objects on the stack... actually, their type can be captured locally by "auto", it avoids a conversion to function<>). Note that "auto" also works on lamba parameters, which is really great, and that you can pass "captureless" lambdas as function pointers too.
- Type traits are fundamental, now you can static_assert away all your hacks (e.g. memset to zero a type? assert is POD...). True, we had them in Boost already, so this could be seen as "minor", but not many companies in my line of work would like to depend on Boost (even if depending only on traits is reasonable), re-implementing them is not trivial (unlike say, static_assert) and so this being part of the official standard is great. Also, the availability of Boost's ones lowers the preoccupation about compatibility.
- Range based for - int array[5] = { 1, 2, 3, 4, 5 }; for (int& x : array)... Small, but saves some typing and every other language does have it...
- Override and Final for virtual functions. Maybe in then years we'll even have "out" for non-const reference/pointer parameters...
- Would use today, but not yet widespread (that to me, means non implemented by VS2012...):
- Non-static member initializer - The ability to initialize member variables at the point of declaration, instead of having to add code to your constructors
- Constexpr - Compile-time constant expressions. Could be nifty, i.e. can remove the need of hacks to do compiletime conversion of strings to hashes...
- Delegating constructors - (suported in VS2013) A small addition, calling constructors from initializer lists of other constructors, it's useful but we already have workarounds and anyhow, you should really initialize things outside your constructor and never use exceptions. Even less interesting is constructor inheritance.
- Raw string literals - (supported in VS2013) Another small addition, but important in some contexts, now you can have string literals that don't need escape codes, which is handy.
- Unrestricted unions - Will enable having unions of types with non-trivial constructors which are not allowed today. No new syntax == good
- Sizeof of member variables without an instance - The lack of this is really counter-intuitive and maddening
- Questionable/proceed with care/better to be avoided if possible:
- Tl;Dr; don't use anything that adds more rules/alternative syntax for things that can be done already. Don't use templates, especially if you think you really found a cool way to use them (i.e. for anything that does not have to do with collections). Don't read Alexandrescu. Don't be smart.
- Initializer lists - (suported in VS2013) These are nice, but they add more ways/rules to the resolution of constructors which is never great, function resolution rules in C++ are already way too complex. In some cases they're ok or even the only way to go (containers), but I would prefer to avoid them in custom classes and if there is another way around.
- Variadic templates - (supported in VS2013) more template hackery. The syntax is quite ugly as well (...... or ...,... or ... ..., yes, let's try everything), but to be fair there are certain uses that might be worth allowing them in your code. An example is std::tuple. For "library" code only.
- R-value references - They generated a lot of noise and you probably know about them (surely, you'll need to know about them), they do make a big difference in the STL (see this for an introduction) but the truth is, you probably already are careful to avoid temporaries (or objects!) and you don't do much work in your constructors... This is mostly good news for the STL and for the rare reasonable uses of templates (unfortunately, we didn't get concepts... so yes, C++ templates are still awful). They are complex. And that is NOT good, C++ is already obscure enough.
- Typed enums - This is actually nice, but it adds yet more things to remember to the language, I'm undecided. The main good part of it is that typed enums don't automatically cast to integers (remember that vice-versa is already not true)
- No_except. You shoulnd't use exceptions anyways.
- Extern templates - Could reduce code bloat due to templates by not having them instantiated in all translation units. It doesn't mean you don't have to have all your templates in your headers though, it's a bit of a mess to use. You shouldn't use many templates anyhow, right? It's better to use less templates than think "extern" will patch the issue
- Minor/Already doable with C++98 workarounds/Not often needed
- __FUNC__ - Officially added to the existing __FILE__ and __LINE__
- Minimal GC support - You're not likely going to use this, but it's good-to-know.
- Static_assert - Chances are that you already know what this is and have macros defined. This new one has a better output from the compiler than your own stuff. The standardization of type traits is what makes static_assert very useful though.
- Alignment - Chances are that you already have some compiler-dependent functions and macros etc defined (and also that you have aligned containers and aligned new, which C++11 still lacks... but hey, support for GC! no aligned new but support for GC... bah...). Chances are, they are clearer, more complete and easier to use than std::align, std::aligned_storage, std::max_align_t and all the crap. Also VS2012.2 std::align seems broken :|
- Decltype - "Grabs" a type from an expression, fixes some old problems with templates, chances are that you'll never run into this other than some questionable uses in typedef decltype(expression)
- Nullptr - Fairly minor, tl;dr NULL is now (also) called nullptr, which is a little bit better
- Foward declaration of enums - Fairly minor, does what it says
- Explicit conversion operator - (supported in VS2013) Patches an ugly hole in the language with implicit conversions. You should ban all the implicit conversions (don't implement custom cast operators and mark all constructors as explicit) anyways and always use member functions instead, so you shouldn't find yourself needing it often...It has some usefulness with templates (which you should mostly avoid anyhow...)
- Explicitly deleting or defaulting auto-generated class functions - Today, you should always remember to declare the functions C++ currently automatically implements for classes (private without implementation if you're not implementing them). This new extension will make that somewhat easier.
I've left out the new library features. C++11 introduced support for concurrency (atomics, threading support, fences, tasks, futures etc...) new smart pointers (unique/shared/weak with their corresponding "make" functions), containers (unordered_map, unordered_set, forward_list, array and std::optional) and so on.
Truth is, they are all nice enough and even needed, but they still fall short of what most people will need when crafting high performance applications (the domain of C++? surely, what we do in realtime rendering...) and chances are you already have rolled your own, optimized versions over these years which could still be even better than what the early compilers will provide on a given platform. E.G. over all these years we still don't have fundamental stuff like a fixed_vector, static_vector, and sorted/unsorted vector/list hybrid (buckets), concurrency is made of threads and not real tasks/jobs (thread pools), still no SIMD/instruction level parallelism etc.
C++ as a language is still so much behind on what matters for performance (regardless of Bjarne's wet dreams), we are and we will still be crafting our own stuff/relying on compiler extensions and intrinsics. We did well with that, we'll do well still.
Rant (can't be avoided when I write about C++): You'll be hearing (or already heard) a lot about "modern" C++, referring to C++11. It's a marketing lie, as most of what they did. Fundamentally, C++11 does not address any of the big issues C++ suffers from (bad defaults, pitfalls, half-arsed templates etc... basically the SIZE of the language and the quality of it), instead it's mostly concerned with "catching up" the back of the box feature list (and making an half-arsed attempt at that, as most things can't be done properly anyways...).
It doesn't even attempt to deprecate anything, it managed to kill the most useful features devoted at simplifying it (template concepts!), it adds a TON of new syntax while keeping the old defaults (no_except, the controls for automatic class functions...) thus hoping that you just remember to use it, and it adds a TON of features squarely aimed at crazy-template-metaprogramming users that most sane people will never allow anyways.
We don't do obfuscated C++ contests because it would be to easy already, with C++11, it would become really crazy...
Truth is, they are all nice enough and even needed, but they still fall short of what most people will need when crafting high performance applications (the domain of C++? surely, what we do in realtime rendering...) and chances are you already have rolled your own, optimized versions over these years which could still be even better than what the early compilers will provide on a given platform. E.G. over all these years we still don't have fundamental stuff like a fixed_vector, static_vector, and sorted/unsorted vector/list hybrid (buckets), concurrency is made of threads and not real tasks/jobs (thread pools), still no SIMD/instruction level parallelism etc.
C++ as a language is still so much behind on what matters for performance (regardless of Bjarne's wet dreams), we are and we will still be crafting our own stuff/relying on compiler extensions and intrinsics. We did well with that, we'll do well still.
Rant (can't be avoided when I write about C++): You'll be hearing (or already heard) a lot about "modern" C++, referring to C++11. It's a marketing lie, as most of what they did. Fundamentally, C++11 does not address any of the big issues C++ suffers from (bad defaults, pitfalls, half-arsed templates etc... basically the SIZE of the language and the quality of it), instead it's mostly concerned with "catching up" the back of the box feature list (and making an half-arsed attempt at that, as most things can't be done properly anyways...).
It doesn't even attempt to deprecate anything, it managed to kill the most useful features devoted at simplifying it (template concepts!), it adds a TON of new syntax while keeping the old defaults (no_except, the controls for automatic class functions...) thus hoping that you just remember to use it, and it adds a TON of features squarely aimed at crazy-template-metaprogramming users that most sane people will never allow anyways.
We don't do obfuscated C++ contests because it would be to easy already, with C++11, it would become really crazy...
If you want a full overview, see:
- http://en.wikipedia.org/wiki/C%2B%2B11
- http://www.cplusplus.com/articles/EzywvCM9/
- http://blog.smartbear.com/software-quality/bid/167271/The-Biggest-Changes-in-C-11-and-Why-You-Should-Care
- Compiler support:
- http://clang.llvm.org/cxx_status.html
- http://blogs.msdn.com/b/vcblog/archive/2013/06/27/what-s-new-for-visual-c-developers-in-vs2013-preview.aspx
- Bonus: How many ways there are to construct objects now?
- http://herbsutter.com/2013/05/09/gotw-1-solution/
- http://herbsutter.com/2013/05/13/gotw-2-solution-temporary-objects/
- http://herbsutter.com/2013/04/05/complex-initialization-for-a-const-variable/
Toni, Joan Blasco and one other like this
21 Apr 19:10
Sandbox adventure platformer Starbound pre-orders already passed $500,000
by John Polson
David AnesPara Joan. ¿Alguien se apunta?
 Chucklefish's story within a procedurally generated sandbox game Starbound has already passed $500,000 in pre-order sales, with almost 22,000 backers and and the Novakid race creation stretch goal secured. Starbound's beta launches later this year and will go to those who pay at least $15 during this pre-order. The game will be available for Windows, Mac, and Linux and will have Steam keys for all purchasers when applicable.
Chucklefish's story within a procedurally generated sandbox game Starbound has already passed $500,000 in pre-order sales, with almost 22,000 backers and and the Novakid race creation stretch goal secured. Starbound's beta launches later this year and will go to those who pay at least $15 during this pre-order. The game will be available for Windows, Mac, and Linux and will have Steam keys for all purchasers when applicable.
The next stretch goal will allow for fossils in the game, requiring special tools and careful precision, or else the fossils may crumble. While some fossils become trophies, others may allow for long-dead creatures to be revived.
Joan Blasco, Mkuipers76 likes this
16 Apr 09:36

OpenGL Space Combat and Strategy Game Programming
David AnesEstá en alemán, pero es interesante.
Learn by doing with a series of game prototypes to demonstrate the fundamentals of OpenGL-based space combat and realtime strategy game programming. Just released, prototype 4 is focusing on procedural planet, moon and asteroid rendering: A fully playable simple realtime strategy space game based on prototype 3; Procedural surface generation in realtime for solid planets, moons and gas giants; Screen space atmospheric light scattering (both Rayleigh and Mie); Planetary ring and cloud layer rendering (combined with light scattering); Visualisation of solar and planetary ring asteroid belts.
Leosamu, Joan Blasco and one other like this
No more posts. Check out what's trending.