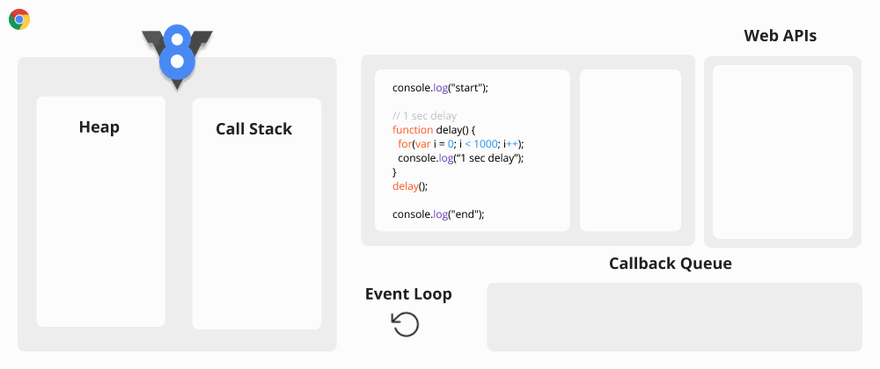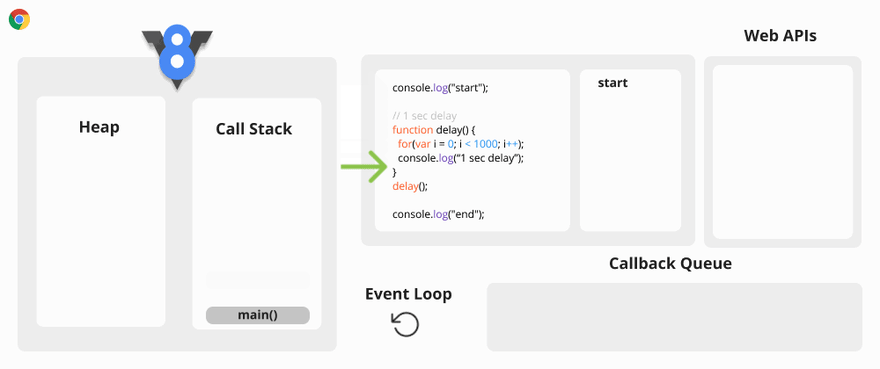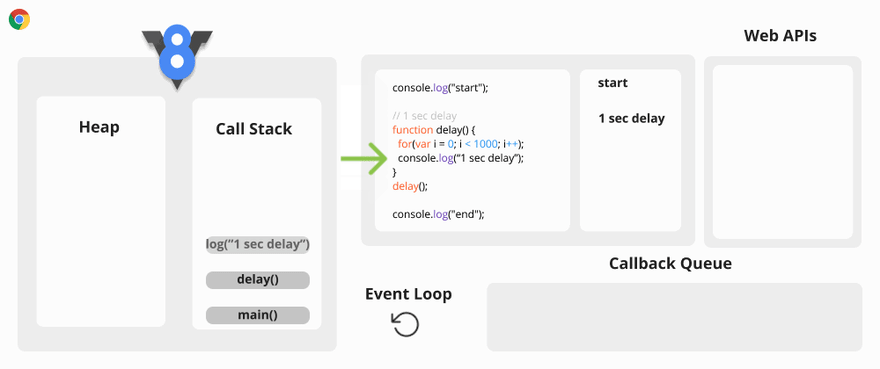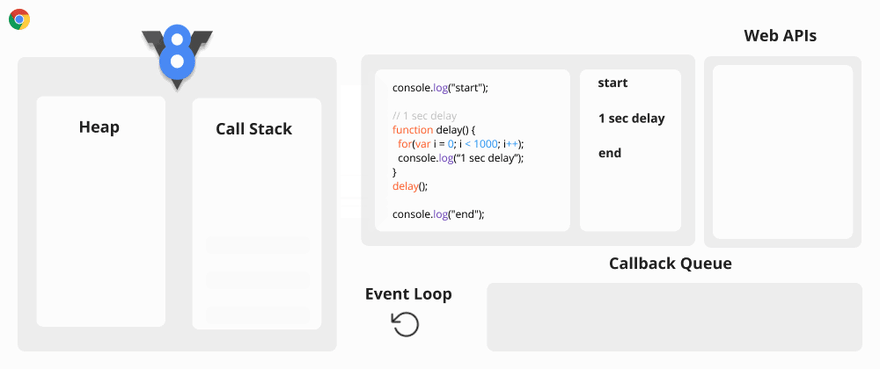
Building K-Nearest Neighbors (KNN) From Scratch
Let's be real: in a production machine learning environment, we all just import scikit-learn and call it a day. But treating algorithms like black boxes can come back to bite you when those abstractions leak. Building K-Nearest Neighbors (KNN) from scratch is a fantastic exercise to actually understand the mechanics working under the hood.
At its core, KNN relies on a surprisingly simple geometric premise: a data point probably belongs to the same category as its closest spatial neighbors. Rebuilding this classifier from the ground up forces you to tackle some critical engineering challenges, such as:
- Computing spatial geometry efficiently
- Managing state during the voting process
- Handling edge cases and algorithmic ties deterministically
In this post, we'll walk through the architectural decisions behind a pure Python implementation of KNN, translating textbook math into functional code.
1. The Distance Metric
import math
def _check_length(x, y):
"""Ensure both vectors have the same length."""
if len(x) != len(y):
raise ValueError("Vectors must be of same length")
def euclidean_distance(x, y):
"""Compute Euclidean distance between two vectors."""
_check_length(x, y)
sum_of_sq = sum(
(i - j) ** 2
for i, j in zip(x, y)
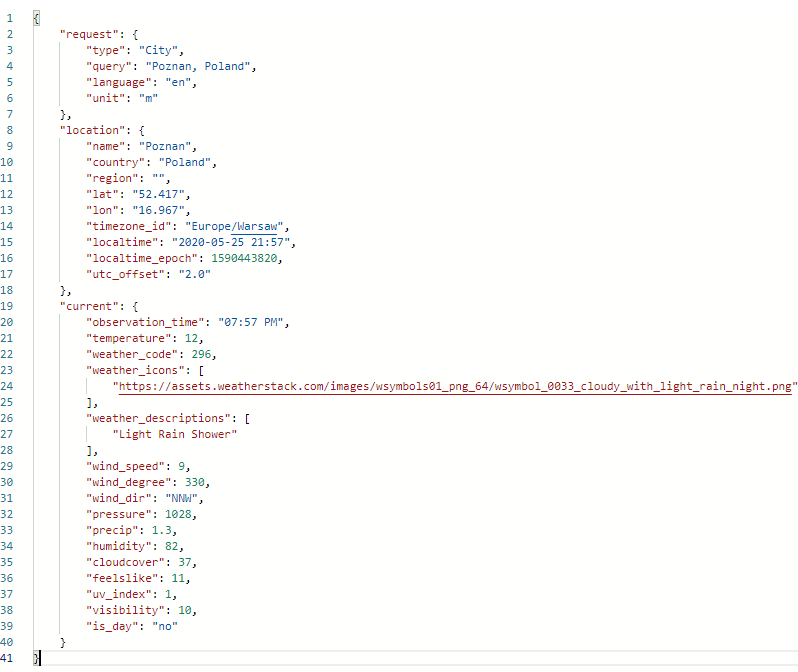
)
return math.sqrt(sum_of_sq)
The Goal
Calculate spatial similarity between vectors using Euclidean distance.
How It Works
KNN is fundamentally a geometry problem. The entire algorithm hinges on quantifying exactly how far apart points are in a given space.
If we're looking at a 2D plane, Euclidean distance comes straight from the Pythagorean theorem:
In machine learning, however, we're rarely dealing with just two dimensions. Fortunately, the formula generalizes neatly to an arbitrary number of dimensions:
Where:
- n is the total number of dimensions.
- xi and yi are the coordinates of vectors x and y along dimension i .
In the euclidean_distance() function above, notice the generator expression inside sum(). It evaluates lazily, meaning we avoid constructing an intermediate list of squared differences in memory. This is a deliberate design choice that scales well when working with high-dimensional data.
Also, don't overlook the _check_length() guard—it is structurally critical. Comparing vectors of different dimensions is mathematically invalid. Since Python's zip() function silently truncates to the shortest iterable, omitting this check could allow the function to fail silently and return incorrect results.
2. The Voting Mechanism and Tie-Breakers
def _get_majority_vote(neighbors):
# ... early-exit validation skipped ...
vote_count = {}
min_distance_per_label = {}
for neighbor in neighbors:
label = neighbor["label"]
distance = neighbor["distance"]
vote_count[label] = vote_count.get(label, 0) + 1
min_distance_per_label[label] = min(
distance,
min_distance_per_label.get(label, float("inf"))
)
best_label = None
best_vote = -1
best_distance = float("inf")
for label in vote_count:
votes = vote_count[label]
dist = min_distance_per_label[label]
if votes > best_vote or (
votes == best_vote and dist < best_distance
):
best_label = label
best_vote = votes
best_distance = dist
return best_label
The Goal
Tally the neighbors' labels to determine the final classification while using spatial proximity as a deterministic tie-breaker.
How It Works
Counting votes is straightforward with a hash map, but robust edge-case management is what separates a demo implementation from production-ready code.
Imagine a scenario where k=4 and your query point sits exactly halfway between two Class A neighbors and two Class B neighbors. A naive implementation might simply choose whichever label appears first. That makes the classifier non-deterministic and biased by data ordering.
To address this, the implementation maintains a secondary dictionary:
min_distance_per_label
As the algorithm iterates through the neighbors, it tracks the minimum distance observed for each class label. If a voting tie occurs,
the algorithm chooses the class whose nearest representative is closest to the query point.
Mathematically:
Where:
- c is a class label.
- q is the query point.
- d(x,q) is the distance between a training sample and the query point.
This approach anchors tie-breaking in actual spatial proximity rather than arbitrary ordering or randomness.
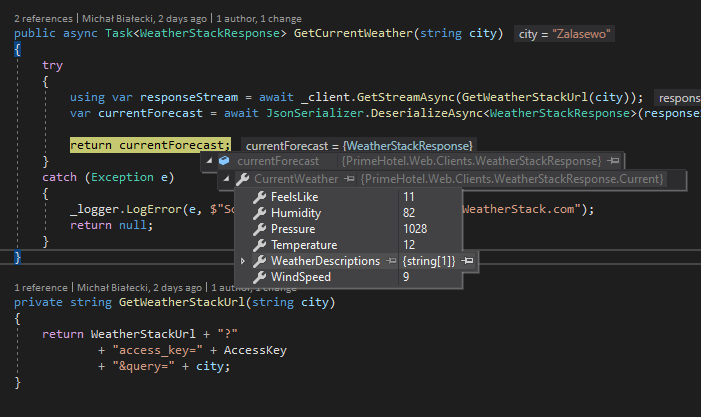
3. The Orchestrator
import numpy as np
def knn_predict(training_data, labels, query_point, k):
# ... input validation skipped ...
distances = [
euclidean_distance(sample, query_point)
for sample in training_data
]
nearest_idx = np.argsort(distances)[:k]
neighbors = [
{
"distance": distances[i],
"label": labels[i]
}
for i in nearest_idx
]
return _get_majority_vote(neighbors)
The Goal
Create a controller function that computes distances, isolates the top k candidates, and delegates classification to the voting logic.
How It Works
Although a production implementation would include comprehensive validation and optimization, the core algorithm relies on one key operation:
np.argsort(distances)[:k]
Keeping multiple arrays synchronized during sorting can quickly become messy. Rather than zipping distances and labels together, sorting them, and then unpacking them again, we sort only the distance values and retrieve the corresponding indices.
numpy.argsort() returns the indices that would sort an array. This allows us to select the nearest neighbors without mutating the original data structures.
Mathematically, we're selecting:
where D is the vector of computed distances.
This is a common scientific-computing pattern because it preserves the relationship between distances and labels while avoiding unnecessary data transformations.
After selecting the nearest indices, we package the neighbors into lightweight dictionaries and pass them directly to the voting mechanism.
Final Thoughts
K-Nearest Neighbors is a unique machine learning algorithm because it behaves less like a traditional parameter-learning model and more like a combination of geometric reasoning and voting heuristics.
Unlike algorithms such as linear regression or neural networks, KNN performs no explicit training. It simply stores the dataset and uses distance as a proxy for similarity during prediction.
Building algorithms from scratch is one of the fastest ways to demystify machine learning. You quickly discover that much of the perceived complexity comes from standard software engineering concerns:
- Performance optimization
- State management
- Data validation
- Numerical stability
The mathematics matters, but so does thoughtful implementation.
Further Reading
To explore more machine learning projects and software engineering content:
- GitHub: https://github.com/Pixie2468
- LinkedIn: https://www.linkedin.com/in/darsh-ayde/