Jean-Philippe Encausse
Shared posts
An AI approach for single-image-based 3D character animation with preserved proportions
'Worst in Show' CES products include AI refrigerators, AI companions and AI doorbells
Gemini 3 change radicalement l’expérience Gmail

La messagerie Gmail de Google dévoile sa plus grande évolution depuis deux décennies, en intégrant cinq nouvelles fonctionnalités basées sur l’intelligence artificielle. Ces innovations promettent de transformer durablement l’expérience des utilisateurs et la manière dont les e-mails sont gérés au quotidien.
Les innovations technologiques les plus insolites déjà dévoilées au CES 2026

Le salon CES 2026, rendez-vous incontournable de l'innovation à Las Vegas, dévoile cette année une série d’inventions technologiques surprenantes et inattendues, repoussant les limites de l’imagination dans des domaines allant du quotidien aux loisirs connectés.
La Marine allemande passe aux armes laser pour détruire les drones

Face à la prolifération des drones, la marine allemande prépare sa révolution technologique. Les géants Rheinmetall et MBDA ont officialisé leur alliance pour développer des armes laser de haute puissance « Made in Germany ».
CES 2026 : voici les innovations qui vont rendre votre quotidien… plus cool
CES 2026 was all about ‘physical AI’ and robots, robots, robots
Le Pire du CES : ces anti-awards récompensent la technologie qui « rend la vie moins bien qu’avant »

Des associations de consommateurs ont récompensé des produits dévoilés au CES avec des anti-awards, mettant en avant les problèmes de société qu'elles ont relevés. On a listé les gagnants et analysé les résultats.
XIAO ePaper DIY Kit – EE02 – An ESP32-S3 board designed for 13.3-inch Spectra 6 color E-Ink display


Seeed Studio’s XIAO ePaper DIY Kit EE02 is an ESP32-S3 WiFi and Bluetooth board designed specifically for the 13.3-inch Spectra 6 color E-Ink display provided by the company.
It’s based on a similar design as the XIAO ePaper DIY Kit-EE04 (ESP32-S3) and XIAO ePaper DIY Kit-EN04 (nRF52480) introduced last December, which are suitable for smaller 1.54 to 7.15-inch ePaper displays. Like the previous models, the new EE02 model also includes a battery connector with a power switch, a built-in charging IC, and comes with one reset and three user buttons. With support for a larger 13.3-inch color ePaper display, it’s especially well-suited for digital frames and information boards.
XIAO ePart DIY kit – EE02 specifications:
- Wireless board – XIAO ESP32S3 Plus
- SoC – Espressif ESP32-S3R8
- CPU – Dual-core Tensilica LX7 microcontroller up to 240 MHz with vector instructions for AI acceleration
- Memory – 8MB PSRAM
- Wireless – WiFi 4 and Bluetooth 5.0 LE + Mesh connectivity
- Storage – 16MB SPI flash, MicroSD card socket
- Antennas – IPEX1 antenna for Wi-Fi and Bluetooth
- USB – USB 2.0 Type-C for power supply and firmware flashing
- SoC – Espressif ESP32-S3R8
- Display
- 60-pin 0.5mm pitch FPC ePaper connector
- Optional 13.3-inch Spectra 6 color E-Ink display
- Dot matrix type
- 1600 x 1200 resolution
- Pixel Pitch(mm) – 0.169 x 0.169
- Display Color – Black, White, Yellow, Red, Green, and Blue
- Interface – SPI
- Misc
- Reset button, 3x user buttons (Refresh, Previous page, Next page), Boot button
- Battery power ON/OFF switch
- LED indicators for battery detection and charging
- Power Supply
- 5V via USB-C port
- Optional 3.7V Li-Ion battery via 2.0mm pitch JST connector
- Dimensions
- Board – 80 x 43 x 7 mm
- Display – About 315 x 210 mm including FPC cable; thickness of display: 0.85mm

Since it’s based on the XIAO ESP32S3 Plus board, Arduino and MicroPython should be supported, but Seeed Studio does not provide any specific instructions for these, and instead the company highlights support for its SenseCraft HMI no-code solution, which enables drag-and-drop canvas design, AI generation of images and canvas, and more.
Suthinee tried it when reviewing the reTerminal E1001/E1002 ePaper displays last month, and she found it easy to use to generate a canvas for a calendar, generate images, and create a weather and currency exchange rate dashboard using live data from the Internet.

The XIAO ePart DIY kit – EE02 board itself sells for just $14.90 with an antenna and FPC cable, but a full kit with the 13.3-inch display goes for $163.90 before taxes and shipping on the same page.
The post XIAO ePaper DIY Kit – EE02 – An ESP32-S3 board designed for 13.3-inch Spectra 6 color E-Ink display appeared first on CNX Software - Embedded Systems News.
L'IA dope le processus d'innovation chez NAB


Elo – Quand une IA écrit un langage de programmation complet sans intervention humaine
Vous connaissez probablement les prouesses de Claude Code pour décompiler du code , ou encore son utilisation pour automatiser la création d'outils , mais là, on a passé un cap.
Bernard Lambeau, un développeur belge avec plus de 25 ans d'expérience et un doctorat en informatique, a décidé de pousser le concept jusqu'au bout à savoir utiliser Claude Code non pas pour écrire quelques scripts, mais pour générer un langage de programmation complet.
Carrément ! Il est chaud Bernard, car quand je dis complet, je parle d'un compilateur entier avec analyseur lexical, un parseur, un système de typage, des backends multiples...etc. Voilà, comme ça, en full pair-programming avec une IA.
Ça s'appelle Elo et l'idée, c'est de proposer un langage tellement sécurisé by design qu'on peut le confier à des non-développeurs… ou à des IA. Pas de variables mutables, pas d'effets de bord, pas de références qui traînent dans tous les sens. Bref, un langage où il est quasi impossible de faire une bêtise, même en essayant très fort.
Alors pourquoi créer un énième langage alors qu'on en a déjà des centaines ?
Hé bien le truc, c'est que la plupart des langages existants partent du principe que vous savez ce que vous faites. JavaScript, Python, Ruby… Ils vous font confiance. Trop, parfois.
Elo, lui, adopte l'approche inverse... le "zero-trust". Le langage ne fait confiance à personne, ni au développeur, ni à l'IA qui pourrait l'utiliser. Ainsi, chaque expression est pure, chaque fonction est déterministe, et le compilateur vérifie tout avant d'exécuter quoi que ce soit.
Et surtout Elo est un langage d'expressions portables, ce qui veut dire que vous écrivez votre logique une fois, et vous pouvez la compiler vers JavaScript, Ruby ou même du SQL PostgreSQL natif. Oui, oui, le même code peut tourner dans votre navigateur, sur votre serveur Ruby, ou directement dans votre base de données. Et là, y'a de quoi faire des trucs sympas pour peu qu'on ait besoin de partager de la logique métier entre différents environnements.
Le typage est volontairement minimaliste mais costaud et se compose de 10 types de base : Int, Float, Bool, String, DateTime, Duration, Tuple, List, Null et Function. Pas de classes, pas d'héritage, pas d'objets au sens classique mais juste des valeurs et des fonctions, ce qui peut paraître limité dit comme ça, mais c'est justement cette contrainte qui rend le langage sûr.
Moins de features, c'est moins de façons de se planter !

L'opérateur pipe |> est le cœur du langage car au lieu d'imbriquer des appels de fonctions comme des poupées russes, vous chaînez les transformations de gauche à droite. Par exemple, pour récupérer tous les clients actifs et compter combien il y en a, vous écrivez quelque chose comme customers |> filter(active: true) |> size. C'est lisible, c'est fluide, et même quelqu'un qui n'a jamais codé comprend ce qui se passe.
Et il y a aussi l'opérateur alternative |. Comme ça, si une expression peut retourner null, vous pouvez prévoir un fallback avec ce simple pipe. Genre user.nickname | user.firstname | "Anonymous". Ça essaie dans l'ordre et ça prend la première valeur non-nulle.
Comme ça, fini les cascades de if/else pour gérer les cas où une donnée manque ! Youpi !
Voilà pour le langage...
Maintenant parlons un peu du bonhomme car Bernard Lambeau n'est pas un inconnu dans le monde du développement. Il est derrière Bmg (une implémentation de l'algèbre relationnelle), Finitio (un langage de schémas de données), Webspicy (pour tester des APIs), et Klaro Cards (une app no-code). Tout cet écosystème partageait déjà une certaine philosophie, et Elo vient unifier le tout. Son langage est d'ailleurs utilisé en production dans Klaro Cards pour exprimer des règles métier que les utilisateurs non-techniques peuvent modifier.
Ce qui m'a intéressé dans toute cette histoire, c'est surtout la méthode de développement de Bernard qui a travaillé en pair-programming avec Claude Code pendant des semaines, voire des mois. L'IA générait du code, et lui relisait, corrigeait, guidait, et l'IA apprenait de ces corrections pour les itérations suivantes. Sur l'ensemble du projet, chaque ligne de code, chaque test, chaque doc a été écrit par Claude et croyez le ou non, le code est clean car Bernard est un pro !
D'ailleurs, il a enregistré une démo de 30 minutes où il montre le processus en live .
En regardant cette démo, on découvre une vraie méthodologie de travail avec l'IA car il n'a pas juste balancé des prompts au hasard en espérant que ça marche. Au contraire, il a mis en place tout un système pour que la collaboration soit efficace et sécurisée.
Premier truc : le "safe setup". Bernard a configuré un environnement Docker sandboxé dans un dossier .claude/safe-setup afin de laisser Claude Code exécuter du code dans un conteneur Alpine isolé, sans risquer de faire des bêtises sur la machine hôte. En entreprise, c'est exactement le genre de garde-fou qu'on veut quand on laisse une IA bidouiller du code. Le conteneur a ainsi accès aux fichiers du projet, mais pas au reste du système.
Ensuite, il y a la documentation projet via un fichier CLAUDE.md à la racine. Ce fichier décrit l'architecture du langage avec le parser, l'AST, le système de typage, les différents backends, comme ça, quand Claude démarre une session, il lit ce fichier et comprend la structure du projet.
La gestion des tâches est aussi bien pensée puisqu'il utilise un système de dossiers façon Kanban : to-do, hold-on, done, et analyze. Chaque tâche est un fichier Markdown qui ressemble à une user story.
Ainsi, quand il veut ajouter une feature, il crée un fichier dans to-do avec la description de ce qu'il veut. Claude lit le fichier, implémente, et Bernard déplace le fichier dans done une fois que c'est validé. Le dossier analyze sert pour les trucs à creuser plus tard, et hold-on pour ce qui attend des décisions.
Ce qui est bien trouvé aussi, c'est qu'il utilise trois modes d'interaction selon les situations. Le mode "accept-it" pour les trucs simples où Claude propose et Bernard dispose. Le "plan mode" quand la tâche est complexe avec Claude qui pose des questions de design avant d'écrire du code. Et le mode autonome avec --dangerously-skip-permissions quand il a parfaitement confiance pour une série de modifications.
Bernard a aussi créé plusieurs personas spécialisés (des agents) que Claude peut invoquer. Un agent "security" qui analyse le code du point de vue sécurité. Un agent "DDD" (Domain-Driven Design) qui vérifie la cohérence du vocabulaire métier. Un agent "skeptic" qui cherche les cas limites et les bugs potentiels. Et un agent "Einstein" qui détecte quand le code devient trop complexe et suggère des simplifications.
En gros, 4 cerveaux virtuels qui relisent chaque modification.
Et là où ça devient vraiment ouf, c'est que Elo se teste lui-même. Les tests d'acceptance sont écrits en Elo, avec une syntaxe d'assertions qui se compile vers JavaScript, Ruby et SQL. Comme ça quand Bernard ajoute une feature, il écrit d'abord le test en Elo, puis Claude implémente jusqu'à ce que le test passe. Le langage valide sa propre implémentation.
Comme je vous l'avais dit, c'est propre !
Bernard n'a fait que valider et refuser et ne retouche jamais le code lui-même. C'est Claude qui fait tout le reste et ça c'est un sacré changement dans la façon de développer.
Il évoque aussi l'idée que quand on délègue une compétence à quelqu'un (ou quelque chose) qui la maîtrise, on peut se concentrer sur le reste. Comme ça, Bernard ne s'occupe donc plus d'écrire du code mais s'occupe plutôt de définir ce que le code doit faire, de valider les résultats, et de guider l'architecture.
C'est vraiment le métier de développeur nouvelle génération et c'est très inspirant si vous cherchez votre place de dev dans ce nouveau monde.
En tout cas, même si ce n'est pas la première fois qu'on voit Claude Code produire des résultats impressionnants là c'est carrément autre chose.
Maintenant si vous voulez tester, l'installation est simple. Un petit
`npm install -g @enspirit/elo`
Et vous aurez ensuite accès à deux outils :
-
elopour évaluer des expressions à la volée, et -
elocpour compiler vers la cible de votre choix.
Et si vous voulez du JavaScript ?
eloc -t js votre_fichier.elo.
Du Ruby ?
eloc -t ruby.
Du SQL ?
eloc -t sql.
Le site officiel propose également un tutoriel interactif plutôt bien fichu pour découvrir la syntaxe. On commence par les bases (les types, les opérateurs), on passe aux fonctions, aux gardes, et on finit par les trucs plus avancés comme les closures et les comparaisons structurelles. En une heure ou deux, vous avez fait le tour.
Alors bien sûr, Elo n'est pas fait pour remplacer votre langage préféré car ce n'est pas un langage généraliste. Vous n'allez pas écrire une app mobile ou un jeu vidéo avec... Par contre, pour exprimer des règles métier, des validations, des transformations de données… C'est pile poil ce qu'il faut.
Peut-être qu'un jour on verra une équipe où les product managers écrivent directement les règles de pricing ou d'éligibilité en Elo , (j'ai le droit de rêver) et où ce code est automatiquement validé par le compilateur avant d'être déployé.
Plus de traduction approximative entre le métier et les devs, plus de bugs parce que quelqu'un a mal interprété une spec.
Le dépôt GitHub est ouvert , la documentation est dispo, et le langage est sous licence MIT donc vous avez de quoi explorer, tester, et pourquoi pas contribuer si le cœur vous en dit.
Voilà, avec Claude Code (ou d'autres comme Gemini CLI, Codex CLI...etc) on n'est clairement plus sur des outils qui complètent du code ou qui génèrent des snippets. On est carrément sur un système IA capable de créer des outils complets et des langages entiers, avec son humain préféré qui joue le rôle de chef d'orchestre.
Steve Klabnik a d'ailleurs fait quelque chose de similaire avec son langage Rue, lui aussi développé avec Claude, si vous voulez jeter un œil !
Voilà les amis ! La tendance est claire j'crois... les développeurs expérimentés commencent à utiliser l'IA comme un multiplicateur de force, et pas comme un remplaçant et je pense vraiment que vous devriez vous y mettre aussi pour ne pas vous retrouver à la ramasse dans quelque années...
Amusez-vous bien et un grand merci à Marc d'avoir attiré mon attention là dessus !

NRF 2026 : le retail à l’épreuve du “Next Now”
Dans quelques heures NRF: Retail’s Big Show ouvrira ses portes au Jacob K. Javits Convention Center, à New York. Comme chaque mois de janvier, l’événement réunira des dizaines de milliers de dirigeants, de distributeurs, de marques et d’acteurs technologiques. Mais l’édition 2026 s’inscrit dans un contexte particulier, après une succession de crises ponctuelles, il évolue …
L’article NRF 2026 : le retail à l’épreuve du “Next Now” est apparu en premier sur FW.MEDIA.
Un père et son fils ont créé un drone plus rapide que tout ce qui existait avant : ils ont dû en construire un 2e pour le filmer !
CES 2026 health & wellness wearables focus on everyday wellbeing

I train regularly, but not because I am trying to become an athlete. I work out to feel better, sleep better, and stay consistent, not to chase podiums or personal records. I care about progress, but I care just as much about recovery, balance, and not burning myself out in the process.
For a long time, health wearables felt like they were built for people who treat their bodies like optimization projects. Everything was about pushing harder, going faster, and doing more. CES 2026 is where that mindset finally softened.
This year’s health and wellness wearables feel calmer, more supportive, and far more human. Instead of constantly demanding improvement, they focus on helping you understand how your body is actually doing day to day.
And that shift makes all the difference.
Even Realities R1 Smart Ring

What it does:
Tracks core health metrics while also acting as a control interface for Even Realities smart glasses, blending wellness data with contextual, hands-free interaction.
Why I’d choose it:
Because it hints at where wearables are going next. Less about staring at stats, more about health fitting naturally into daily moments.
Amazfit Active Max

Amazfit Active Max
Large-display smartwatch with long battery life and broad fitness tracking.
What it does:
Features a 1.5-inch ultra-bright AMOLED display, supports over 170 workout modes, offline maps and music storage, and delivers up to 25 days of battery life.
Why I’d choose it:
Because I want visibility without compromise. Big screen when I need it, and battery life that does not make charging part of my routine.
Garmin Venu 4

Venu 4
Lifestyle focused smartwatch with deep health tracking and strong battery life.
What it does:
Combines a bright AMOLED display with comprehensive health and fitness tracking, including heart rate, heart rate variability, sleep, stress, respiration, blood oxygen, and multi sport activity tracking. It balances daily wellness insights with reliable workout support and long battery life.
Why I’d choose it:
Because it sits comfortably between fitness and lifestyle. It gives me serious health data without feeling like a hardcore training tool I have to constantly manage.
NuraLogix Longevity Mirror

NuraLogix Longevity Mirror
AI powered smart mirror that delivers health insights through a quick facial scan.
What it does:
Uses advanced camera based analysis to assess cardiovascular indicators, stress levels, metabolic signals, and overall longevity trends in under a minute. It provides a clear wellness snapshot without wearing or charging any device.
Why I’d choose it:
Because it reframes health as a daily check in, not a constant measurement. Standing in front of a mirror feels far more natural than strapping on yet another wearable.
Motorola Moto Watch

Motorola Moto Watch (US Sale Starts at January 22)
Motorola smartwatch with wellness tracking and extended battery life.
What it does:
Tracks activity, heart rate, sleep, and general health metrics in a clean, approachable smartwatch designed for everyday wear.
Why I’d choose it:
Because not every wearable needs to feel intense. This feels like a watch you wear because it fits your life, not because you are chasing metrics.
RingConn Gen 3
Third-generation smart ring focused on recovery and health trends.
What it does:
Tracks sleep, heart rate, activity, and recovery with improvements in accuracy and comfort, designed for all-day and overnight wear without distraction.
Why I’d choose it:
Because rings fit into training life effortlessly. I can lift, run, sleep, and recover without ever thinking about the device.
The Takeaway From CES 2026 Health & Wellness Wearables
What CES 2026 makes clear is that health tech is finally learning how to stay in its lane.
These wearables are not trying to turn everyone into an athlete or quantify every moment of the day. They are designed for people who train regularly, want to feel good, and also have lives that extend far beyond workouts. Devices like smart rings, screenless bands, approachable watches, and even wellness mirrors all share the same underlying idea: support consistency, not perfection.
There is a noticeable softness to this year’s lineup. More focus on recovery. More respect for rest. More understanding that wellbeing is something you build slowly, not something you optimize overnight.
The CES 2026 health and wellness wearables lineup feels less like a scoreboard and more like a set of tools you can choose from depending on where you are in your routine. And that flexibility is what makes it exciting.
For the first time in a while, health tech feels like it is meeting people where they are, instead of asking them to become someone else.
And honestly, that feels like real progress.
The post CES 2026 health & wellness wearables focus on everyday wellbeing appeared first on Gadget Flow.
Ce que le CES 2026 révèle vraiment : l’IA est en train de sacrifier l’électronique grand public !
De la différence entre information et conseil


CES 2026: Why OLLO made me rethink what home robots are for

Home robots are leveling up, and CES 2026 showed amazing prototypes. In Las Vegas, some robots worked on their own instead of following preset routines or being controlled from afar—no “long leash” here, Tesla’s Optimus! Robots folded laundry, poured coffee, but one stood out. Ollobot’s OLLO wasn’t just about doing chores; it focused on spreading good vibes and, if you’re open to it, becoming part of your family.
The other day, I wrote about Tombot and its robot puppy, Jennie, which aims to boost quality of life for older people. Now, OLLO, a quirky, alien-like robot, is ready pick up your routines and capture key moments on its own—no commands needed.
Design

OLLO comes in two versions—OlloNi S1 (650 × 434 × 343 mm) with a short neck and OlloNi L1 (1200–660 × 434 × 343 mm) with a long neck. Each one feels like a fuzzy cyber pet with real charm. Both have fur, and the S1 can stretch his neck to hunt for your keys or play giraffe. I see the L1 as a Scrat twin from Ice Age. On top of that, OLLO develops a personality over time, which adds extra charm (more on that below).
Pick the L1 or the S1 and you get a small cyber pet that rolls on wheels, not legs. It rolls on wheels instead of legs. That detail feels like the main catch for me. I miss legs, since they could add more fun and boost the Scrat vibe.
Features
LG brought a humanoid robot on wheels to the floor with CLOiD, a machine that can make breakfast. But at CES 2026, I found myself drawn to ideas that felt stranger. OLLO pulled me in because it doesn’t behave like an appliance at all. Instead, it acts more like a pet, aiming for emotional connection through eye contact and playful sounds rather than task lists.
That emotional focus shapes how OLLO communicates. Rather than relying on full sentences, it expresses itself through body language—small neck movements, subtle facial cues, and a nonverbal sound set. Speech appears only when a moment truly calls for it, a choice that keeps the experience far from that of a talking appliance. OLLO also reads voice tone, motion, and interaction patterns to sense mood and energy, then shifts its behavior to match. It may stay close and move slowly, or burst with excitement when the moment feels right.
Memory is what gives OLLO its spark. The robot identifies moments it considers high value—birthdays, group gatherings, and big wins—and begins capturing photos and video on its own. I enjoy the lack of manual control, since the best shots often come from chance. Over time, OLLO recognizes each family member, picks up on habits, and develops a personality.
Inside, OLLO runs as a self-contained AI computer with cameras, microphones, and built-in memory. That memory is embodied as a “heart” beneath its soft, furry wings, placing privacy front and center at a moment when many AI products depend on the cloud. If the robot’s body breaks, the family cyber-pet keeps its past. A new body can inherit the old heart and carry on.
Price and availability
From what multiple sources say, OLLO should cost $1,200 to $2,000 based on size, with accessories and outfits bringing in extra revenue. An international Kickstarter campaign might pop up around summer.
Before you go
CES 2026 made it clear that home robots are no longer just about efficiency—they’re starting to explore emotion, presence, and companionship. OLLO isn’t trying to replace your routines so much as slip into them, learning who you are and how your days unfold.
I can see myself warming up to a robot like OLLO, not because of what it does, but because of how it makes you feel when it’s around. If you’re open to that kind of relationship, OLLO suggests a future where robots aren’t tools you command, but characters you live with. And that shift may be the strangest—and most interesting—upgrade of all.
The post CES 2026: Why OLLO made me rethink what home robots are for appeared first on Gadget Flow.
The RAM shortage’s silver lining: Less talk about “AI PCs”
RAM prices have soared, which is bad news for people interested in buying, building, or upgrading a computer this year, but it's likely good news for people exasperated by talk of so-called AI PCs.
As Ars Technica has reported, the growing demands of data centers, fueled by the AI boom, have led to a shortage of RAM and flash memory chips, driving prices to skyrocket.
In an announcement today, Ben Yeh, principal analyst at technology research firm Omdia, said that in 2025, “mainstream PC memory and storage costs rose by 40 percent to 70 percent, resulting in cost increases being passed through to customers.”

faytech booth tour at CES 2026 Transparent OLED kiosk + Looking Glass HLD, optical bonding, IP69K
faytech’s booth tour is a good snapshot of where “display as interface” is going: not just a panel on a wall, but a complete front end for AI agents, payments, and wayfinding. The standout is a concierge-style station built with partners like Napster and Edo, blending audio (including a dedicated subwoofer/speaker) with showpiece visuals like lenticular-style depth effects and transparent display concepts meant for high-traffic public spaces. https://faytech.com/ces-highlights/
A practical thread running through the demos is how these kiosks are engineered for real deployments, not just show-floor gloss. The China rollout example focuses on self-service ordering plus card payment and voucher printing, which is a useful reminder that UX, peripherals, and compliance matter as much as pixels. Seen in context later at CES Las Vegas 2026, the pitch is that interactive signage is becoming an AI-enabled “counter” that can talk, guide, and transact.
On the core product side, faytech leans hard on industrial display fundamentals: optical bonding to improve contrast and readability, plus rugged mechanics for touch reliability and long uptimes. A new USB touchscreen series is shown running from a Mac mini without driver drama, targeting machine-control and shop-floor HMI use where “one cable for signal + touch (and often power)” reduces integration friction. They also show a movable button accessory for haptic feedback, aiming to bring back tactile control where flat glass alone can feel vague.
Ruggedization gets specific with stainless steel outdoor and washdown designs rated up to IP69K, positioned for food processing, healthcare, and other environments that demand high-pressure cleaning and sealed I/O. The same approach extends to semi-outdoor and outdoor signage formats (strip displays for transit, kiosk enclosures, and modular housings), where brightness, sealing, and serviceability tend to decide whether a screen becomes a long-term asset. In other words, the “nice look” is backed by mechanical and environmental detail that helps it survive real work.
The other big theme is 3D and volumetric-style presentation without headsets: faytech pairs transparent OLED kiosk form factors with Looking Glass Hololuminescent Display tech to create a perceived depth volume behind the front surface, tuned for retail, signage, and character-driven content. That plugs neatly into the booth’s AI-avatar ecosystem, including large-format “holo box” builds (like an 86-inch class unit) where animated agents run all day—bandwidth permitting. It’s a coherent stack: durable enclosures + bonded touch + novel optics, built to make AI interfaces feel present in a physical space, not just on a flat screen.
I’m publishing about 100+ videos from CES 2026, I upload about 4 videos per day at 5AM/11AM/5PM/11PM CET/EST. Check out all my CES 2026 videos in my playlist here: https://www.youtube.com/playlist?list=PL7xXqJFxvYvjaMwKMgLb6ja_yZuano19e
This video was filmed using the DJI Pocket 3 ($669 at https://amzn.to/4aMpKIC using the dual wireless DJI Mic 2 microphones with the DJI lapel microphone https://amzn.to/3XIj3l8 ), watch all my DJI Pocket 3 videos here https://www.youtube.com/playlist?list=PL7xXqJFxvYvhDlWIAxm_pR9dp7ArSkhKK
Click the “Super Thanks” button below the video to send a highlighted comment under the video! Brands I film are welcome to support my work in this way 
Check out my video with Daylight Computer about their revolutionary Sunlight Readable Transflective LCD Display for Healthy Learning: https://www.youtube.com/watch?v=U98RuxkFDYY
How The North Face, Vans and Timberland are trying to transform their businesses in 2026
Apparel and outdoors giant VF Corp is revealing more details of its growth playbooks for three of its core brands: The North Face, Vans and Timberland.
The company, which recently reported a 2% rise in revenue for its second fiscal quarter, knows it’s at a crossroads as 2026 gets underway. Two of its brands — The North Face and Timberland — have managed to hold onto gains. Meanwhile, Vans — once VF Corp’s top-performing brand — has struggled with muted demand. This last quarter, Vans reported a 9% drop in year-over-year revenue — progress over other quarters, but still not where the company would like to be. Meanwhile, VF Corp just sold Dickies for $600 million, a decision it hopes will help drive shareholder returns.
It’s a critical moment for the company, which will celebrate the 60th birthdays of both Vans and The North Face in 2026. “Looking ahead, we will continue to focus on generating value across our brands and returning the company to sustainable and profitable growth,” Bracken Darrell, VF Corp’s president and CEO, said in a statement in October.
Continue reading this article on modernretail.co. Sign up for Modern Retail newsletters to get the latest on the shifting dynamics between retail’s old and new guards.
CES 2026: Sci-Fi meets beauty in L’Oréal’s new hair straightener and LED face mask

LED-equipped beauty products have been gaining momentum for the past decade. L’Oréal at CES 2026 was riding that wave with its new hair straightener and LED face mask. The mask uses LEDs to improve skin quality in a sci-fi-like, flexible design, while the straightener styles hair without damaging it.
As someone who’s tried her fair share of beauty gadgets, I appreciated L’Oréal’s emphasis on LEDs this year. Unlike some buzzwordier products, LED therapy is actually backed by science, so I know these devices aren’t just snake oil.
It’s also refreshing to see beauty tech that supports both health and practicality. I mean, have you seen what most LED face masks look like? Creepy…
Light Straight + Multi-styler: Style Without Sacrifice

I’ll admit it: I’m wary of most hair straighteners. Traditional irons can reach 400°F, which is way above the temperature where keratin starts to deteriorate. L’Oréal’s new straightener flips the script. Using patented infrared light technology, it never exceeds 320°F but still promises glossy, smooth results. According to L’Oréal, it works three times faster than leading premium stylers and leaves hair twice as smooth. Nice!
How does it work? The near-infrared light penetrates deeply to reshape internal hydrogen bonds—the microscopic structures that determine hair’s texture. It gives you sleek strands without damaging the hair’s natural strength.
Another cool touch? The Light Straight + Multi-Styler adapts to your gestures with built-in sensors and AI. Your styling is personalized without you having to think about it.
LED Face Mask: Science Meets Comfort

LED face masks are a complicated product category. I’ve seen plenty of bulky, uncomfortable masks that promise miracles and deliver…well, nothing. L’Oréal’s version takes cues from sheet masks: it’s flexible and sits directly on your skin. From that position, red and infrared light easily penetrate the dermal layers. You only need 5–10 minutes per session, which is far less than most masks on the market.
Even better, the mask uses two scientifically supported wavelengths—630nm and 830nm—backed by clinical research from L’Oréal’s partner, iSmart. That’s the kind of detail that makes me trust a beauty gadget. And while I haven’t tried it myself yet, the design suggests it could complement existing skincare routines, like boosting absorption of serums or moisturizers.
I also appreciate that L’Oréal is pursuing FDA 510(k) clearance, a rare move in the beauty world. It signals that they’re serious about safety and honesty with this wearable beauty gadget.
My Take: Practical, Futuristic, and Surprisingly Sensible
Both products feel futuristic, like we’re witnessing the next generation of beauty products. The straightener is fast, smart, and protective. The mask is flexible, science-driven, and user-friendly. Both make beauty tech usable and effective.
Pricing and global launch dates haven’t been revealed yet. The straightener won’t hit stores until 2027, and the mask is pending FDA clearance. But if L’Oréal’s R&D delivers, these could become must-haves for anyone who loves gadgets and cares about results.
Bottom Line
L’Oréal’s Light Straight + Multi-styler and LED Face Mask show that the future of beauty doesn’t have to be overcomplicated. It can be smart, safe, and practical. For anyone tired of sacrificing hair health or wearing clunky masks, these gadgets might just give your beauty routine a seriously high-tech glow-up.
The post CES 2026: Sci-Fi meets beauty in L’Oréal’s new hair straightener and LED face mask appeared first on Gadget Flow.
Google MedGemma 1.5 et MedASR - L'assistant ultime des toubibs
Il semblerait que l'intelligence artificielle ait fait suffisamment de progrès pour pourvoir assister à terme nos médecins débordés et en sous-nombre... C'est vrai que je vous parle souvent ici de comment les technos peuvent faire évoluer la médecine , mais là Google vient de passer un nouveau cap avec sa collection HAI-DEF (pour Health AI Developer Foundations, oui ils adorent les acronymes de barbares, je sais..).

Et là dedans, on trouve un gros morceau baptisé MedGemma 1.5 . Si la version précédente gérait déjà les radios 2D classiques, cette mise à jour s'attaque maintenant à la "haute dimension". En gros, le modèle peut maintenant analyser des volumes 3D issus de scanners (CT) ou d'IRM, et même des coupes d'histopathologie (l'étude des tissus biologiques).
Pas mal hein ?
L'idée n'est pas de remplacer le radiologue (pas encore... brrr), mais de lui servir d'assistant survitaminé pour repérer des anomalies ou localiser précisément des structures anatomiques. Ainsi, sur les tests de Google, MedGemma 1.5 améliore la précision de 14 % sur les IRM par rapport à la V1. C'est un sacré gain qui permet d'avoir des diagnostics plus justes et plus rapides.

Mais ce n'est pas tout puisque Google a aussi dégainé MedASR, un modèle de reconnaissance vocale (Speech-to-Text) spécialement entraîné pour la dictée médicale. Parce que bon, on sait tous que le vocabulaire d'un toubib, c'est un peu une langue étrangère pour une IA classique comme Whisper. Grâce à ça, MedASR affiche 58 % d'erreurs en moins sur les comptes-rendus de radios pulmonaires, soit de quoi faire gagner un temps précieux aux praticiens qui passent souvent des heures à saisir leurs notes.
D'ailleurs, si vous vous souvenez de mon article sur l'ordinateur plus efficace que les médecins , on y est presque ! Sauf que là, l'approche est plus collaborative. Les modèles sont d'ailleurs disponibles en "open" (enfin, avec les licences Google quoi) sur Hugging Face pour que les chercheurs et les boites de santé puissent bidouiller dessus.

Alors bien sûr, faut toujours rester prudent et Google précise bien que ce sont des outils de recherche et pas des dispositifs médicaux certifiés pour poser un diagnostic tout seuls. Je me souviens bien de Google Health et des questions sur la vie privée que ça soulevait à l'époque, mais techniquement, ça déchire.
Voilà, si ça vous intéresse, je vous laisse regarder leurs explications et vous faire votre propre avis sur la question... Maintenant, est-ce que vous seriez prêts à confier votre prochaine analyse à une IA (assistée par un humain, quand même) ?
Moi oui !

I finally found AI smart glasses that offer a true glimpse of the future
The RayNeo X3 Pro smart glasses are built atop Android foundations and heavily rely on Gemini, serving it all atop an invisible screen and "normal" form factor. It's only plagued by the curse of a first generation product.
The post I finally found AI smart glasses that offer a true glimpse of the future appeared first on Digital Trends.

AI Has Basically Killed Stack Overflow
Since 2008, Stack Overflow has been an immensely helpful resource for developers, allowing them to crowdsource answers to their coding questions — and resulting in a vast online repository of coding knowledge.
But as Dev Class reports, the advent of generative AI appears to have caused an extinction-level event for the platform, with the number of monthly questions plummeting significantly since around the time ChatGPT burst onto the scene in late 2022.
The data, as accessed through Stack Overflow’s own Data Explorer, tells a dramatic story. The number of questions per month fell from over 21,000 in January 2025 to a measly 3,607 by December. Back in the start of 2023, it was fielding 100,000 per month.
The issue? Large language model-based tools like OpenAI’s blockbuster chatbot have allowed programmers to get coding help with simple text prompts, foregoing the need to take their questions to Stack Overflow.
There’s a meta twist: Stack Overflow signed a partnership with OpenAI in 2024 in an effort to “strengthen the world’s most popular large language models” — either leaning into the inevitable or hastening its own demise, depending on your perspective.
It’s a confounding situation. The company introduced an “AI Assist” feature, described as a “new way for users to access our 17 years of expert knowledge,” last month. Yet, as Dev Class points out, using generative AI to answer questions on the platform is still banned.
Disillusioned users argued that the site’s often hostile and “toxic” community has contributed to its decline as well, criticizing the company for allowing moderators to mishandle duplicate queries, for instance. Many users have grown frustrated with being shut down for asking already-answered questions.
“Of course, one could point to 2022 and say ‘look, it’s because of AI,’ and yes, AI certainly accelerated the decline, but this is the result of consistently punishing users for trying to participate in your community,” one Reddit user argued. “People were just happy to finally have a tool that didn’t tell them their questions were stupid.”
Others pointed out that the most important questions simply may have already been asked.
“I very rarely find that I need to ask new questions on Stack Overflow,” another user wrote. “A problem is either trivial enough that I can find the answer myself, common enough that someone’s already asked before, or so difficult and so niche that asking other people for help is fruitless.”
Programmers are concerned about what comes next, especially considering the well-documented shortcomings of AI. Hallucinations are still a major issue, forcing developers to spend significant amounts of time fixing errors.
The more practical question: when new technologies are deployed, and Stack Overflow is a husk, where will the AIs get their coding info from?
Stack Overflow “was by far the leading source of high quality answers to technical questions,” one user argued on Hacker News. “What do LLMs train off of now?”
More on AI coding: AI Code Is a Bug-Filled Mess
The post AI Has Basically Killed Stack Overflow appeared first on Futurism.

Ce qui fonctionne aujourd’hui avec l’IA sans effort particulier

L’intelligence artificielle est présentée comme levier de performance mais à mesure que les annonces se succèdent, une question est rarement abordée, à savoir : qu’est-ce qui fonctionne vraiment aujourd’hui, sans effort particulier, dans des organisations sous pression et déjà saturées de projets de transformation.
Ici on est à l’opposé des discours orientés « IA First » et des transformations structurantes et on essaie de regarder le bas de l’échelle, ce qui fonctionne de manière naturelle, peut apporter quelque chose aux salariés à un niveau individuel mais sans avoir de véritable impact au niveau du collectif ou de l’entreprise autre que marginal (L’appropriation collective de l’IA seule condition d’impact tangible).
Quelle utilité ? Savoir comment construire un socle d’adoption même minimaliste pour, ensuite, pouvoir construire dessus mais aussi, parce qu’on parle beaucoup des trains qui arrivent en retard, de remettre un peu la lumière sur ceux qui arrivent à l’heure.
En bref :
- Les usages d’IA qui fonctionnent aujourd’hui sont ceux qui s’intègrent naturellement dans les pratiques existantes, sans nécessiter de transformation organisationnelle ou d’effort d’adoption significatif.
- Ces usages sont majoritairement individuels, liés à des tâches locales et répétitives, et ne redéfinissent pas les rôles ni les processus collectifs.
- Leur efficacité repose sur leur « invisibilisation » progressive : ils cessent d’être perçus comme de l’IA, s’intègrent dans les outils du quotidien et sont parfois utilisés de manière informelle ou cachée.
- L’adoption repose sur une pratique empirique, sans discours idéologique, qui permet aux utilisateurs de développer une confiance pragmatique dans ces outils.
- Ces usages ne constituent pas un modèle de transformation mais un indicateur de ce que les organisations peuvent absorber sans résistance, posant ainsi une base minimale pour une adoption plus large.
Quand l’IA n’est pas un sujet
Lorsqu’on observe les usages de l’intelligence artificielle en entreprise après quelques années de discours et d’expérimentations on remarque que si une grande partie de ce qui est lancé disparaît sans laisser de trace durable pour diverses raisons, certains usages persistent. Ils ne sont pas nécessairement identifiés comme stratégiques mais ils perdurent.
Ce qui fonctionne aujourd’hui correspond en effet rarement à ce qui a été le plus mis en avant. Des usages qui ont trouvé une place suffisamment compatible avec le fonctionnement existant, exigé un changement minimal qui fait qu’on ne les remarque même plus et ne les mentionne pas davantage.
Priorité à l’optimisation ultra locale
Les usages qui perdurent sans effort particulier s’insèrent presque toujours dans des processus déjà en place. L’IA n’y apparaît pas comme un principe organisateur ou une fin en soi mais comme un ajout à la marge, à un moment ou dans une tache pénible, répétitive, le plus souvent à l’échelle de l’utilisateur, pas du collectif. Elle n’entraîne pas de redéfinition immédiate des rôles ni de redistribution des responsabilités.
C’est précisément cette absence de rupture qui permet à l’usage de s’installer. Il n’y a pas besoin d’y croire, ni de défendre une vision. Le travail ne change pas, pas de redesign mais il devient simplement un peu moins contraignant. Un gain limité mais concret qui suffit à expliquer pourquoi l’usage persiste là où des dispositifs plus ambitieux s’épuisent rapidement..
Quand l’usage devient inconscient
Un trait récurrent de ces usages qui fonctionnent aujourd’hui est leur disparition progressive du discours. Ils cessent en effet d’être présentés comme de l’IA et deviennent un mécanisme parmi d’autres, intégré dans les habitudes de travail de certains. Cette forme d’invisibilisation s’explique de deux manières.
La première est qu’une initiative, même peu ambitieuse, est devenue une pratique.
La seconde, ne l’oublions pas, est le « shadow IA » et ces salariés qui ne veulent pas montrer qu’ils utilisent l’IA !
On a aussi l’évolution des outils avec des IA qui ne s’utilisent plus de manière intentionnelle mais sont intégrées dans les outils du quotidien. On passe de l' »art du prompt » à l’utilisation d’une fonctionnalité qui fait tomber une barrière à l’adoption et fait oublier qu’on utilise une technologie nouvelle (Personne ne veut prompter).
On dit souvent que la technologie est un mot qui décrit quelque chose qui ne fonctionne pas encore mais on pourrait tout aussi bien dire qu’elle décrit quelque chose dont l’utilisation demande un effort.
On ne parle plus de ce qui fonctionne, seulement de ce qui ne fonctionne pas ou pas encore.
La pratique règle le rapport humain/IA
Les usages qui persistent ne sont pas accompagnés de grands discours sur la place de l’humain et c’est peut être la raison pour laquelle ils ne font pas peur. Les choses sont réglées de manière pragmatique et-les équipes savent quand suivre une recommandation, quand s’en écarter, quand utiliser l’IA et quand reprendre la main. Cette compréhension est empirique, souvent imparfaite, n’est pas toujours formalisée mais elle vient de l’expérience donc est facteur de confiance plus que de peur.
Quand cette confiance tirée de l’expérience existe l’IA ne devient pas un sujet sensible. Elle est utilisée, discutée mais rarement rejetée. A l’inverse là où elle n’existe pas l’usage reste fragile, même lorsque la technologie est jugée pertinente.
Les leçons tirées des cas d’usages locaux
Ce qui fonctionne aujourd’hui avec l’IA ne dessine pas plus un modèle à reproduire qu’une une trajectoire à suivre. Cela ne fournit aucune méthode et n’enclenche aucune transformation mais montre simplement ce que des organisations acceptent sans effort supplémentaire.
Cela nous dit ce que l’entreprise tolère naturellement dans son fonctionnement quotidien. C’est imparfait, les gains sont limités mais c’est une base pour écrire la suite de l’histoire.
Conclusion
Ce qui fonctionne aujourd’hui ce sont des usages qui se sont imposés sans effort supplémentaire ni transformation, changement de l’existant. Ils ne sont pas porteurs d’une ambition mais nous disent ce qu’on peut faire a minima.
En ce sens ils constituent plutôt un révélateur car ils montrent les formes d’automatisation, de recommandation ou d’assistance que l’organisation est capable d’absorber sans se mettre en tension.
Pour répondre à vos questions…
Ce qui fonctionne repose sur des usages à la marge, intégrés à l’existant, sans transformation ni effort particulier. Il s’agit d’aides ponctuelles à l’échelle individuelle, sur des tâches répétitives ou pénibles. Ces usages n’ont rien de stratégique mais apportent un gain immédiat et concret. Leur force tient à l’absence de rupture : ils ne changent ni l’organisation ni les rôles, ce qui leur permet de s’installer durablement là où des initiatives plus ambitieuses échouent.
Les projets les plus visibles sont généralement porteurs d’ambitions fortes et exigent des changements profonds. Dans des organisations déjà sous pression, ces ruptures supplémentaires créent de la fatigue et des résistances. A l’inverse, les usages qui durent sont compatibles avec les pratiques existantes et ne demandent ni engagement idéologique ni réorganisation. Ce décalage explique pourquoi ce qui est le plus mis en avant n’est pas ce qui produit le plus d’impact durable.
L’optimisation ultra locale permet à l’IA d’intervenir comme un simple outil d’allègement du travail. Elle agit à un point précis du processus sans remettre en cause l’ensemble. Cette approche réduit les frictions, évite les débats et rend l’usage acceptable sans effort conscient. Le bénéfice est limité mais tangible, ce qui suffit à ancrer la pratique dans le quotidien, sans besoin de vision globale ou de discours mobilisateur.
Lorsqu’un usage fonctionne, il cesse d’être perçu comme de l’IA et devient une habitude. Cette invisibilisation vient aussi du « shadow IA », quand les salariés préfèrent ne pas afficher leurs pratiques. L’intégration de l’IA directement dans les outils du quotidien joue également un rôle : l’effort disparaît, notamment celui du prompt. Moins l’usage est prescrit, plus il devient naturel et durable.
Ces usages ne tracent ni une méthode ni un modèle, mais révèlent ce que l’organisation accepte sans se mettre en tension. Les gains sont modestes mais réels, et l’expérience crée une confiance pragmatique entre humains et outils. Cette base minimale montre les formes d’assistance ou d’automatisation absorbables naturellement. Pour un décideur, c’est un point d’appui pour construire progressivement, sans forcer une transformation déconnectée des usages réels.
Crédit visuel : Image générée par intelligence artificielle via ChatGPT (OpenAI)
L’article Ce qui fonctionne aujourd’hui avec l’IA sans effort particulier est apparu en premier sur Bloc-Notes de Bertrand Duperrin.
Chine vs USA - Le grand divorce de la cybersécurité est acté
La nouvelle est tombée hier soir et elle fait boum boum boum dans le monde feutré de la tech... En effet, Pékin a officiellement demandé aux entreprises chinoises de mettre à la porte les logiciels de cybersécurité américains et israéliens.
C'était prévisible et quand j'ai lu ça, je me suis dit, tant mieux pour eux !
Concrètement, cette annonce, ça veut dire que des géants comme Broadcom, VMware, Palo Alto Networks, Fortinet ou encore l'israélien Check Point sont désormais persona non grata dans les systèmes d'information de l'Empire du Milieu.
La raison officielle, c'est la sécurité nationale comme d'hab. Mais aussi parce que la Chine en a marre de dépendre de technologies qu'elle ne contrôle pas (et qui pourraient bien cacher deux-trois mouchards de la NSA, on ne sait jamais ^^).
Alors vous allez me dire "Oulala, les méchants chinois qui se ferment au monde". Sauf que non... en réalité, ils appliquent juste une stratégie de souveraineté technologique sans concession. Et en remplaçant le matos étranager par du matos local, ils commencent le grand ménage.
Et pendant ce temps là en Europe, on continue d'installer joyeusement des boîtes noires américaines au cœur de nos infrastructures critiques, en priant très fort pour que l'Oncle Sam soit gentil avec nous. Yoohoo !
J'en parlais déjà à l'époque de l'affaire Snowden ou plus récemment avec les backdoors découvertes un peu partout mais la dépendance technologique, c'est évidemment un risque de sécurité béant. Pire, si demain Washington décide de "couper le robinet" ou d'exploiter une porte dérobée, on est, passez-moi l'expression, dans la merde.
La Chine l'a compris et investit donc massivement dans ses propres solutions, comme avec l'architecture RISC-V pour s'affranchir d'Intel et AMD. C'est une démarche cohérente et c'est même assez fendard quand on connaît l'histoire des groupes comme APT1 qui ont pillé la propriété intellectuelle occidentale pendant des années.
Maintenant qu'ils ont un bon niveau, ils ferment la porte...
Du coup, sa fé réchéflir car est-ce qu'on ne devrait pas, nous aussi, arrêter de faire les vierges effarouchées et commencer à construire sérieusement notre autonomie ? Il parait que c'est en cours... moi j'attends de voir.
Bref, la Chine avance ses pions et sécurise son périmètre et nous, baaah, j'sais pas... On remue nos petits bras en l'air en disant des choses au pif.

Google est en train de braquer l'IA
J'sais pas si vous l'avez senti mais Google est peut-être bien en train de gagner la course à l'IA non pas par son génie technique pur, mais par un bon gros hold-up sur nos infrastructures et nos vies privées.
C'est vrai que d'après pas mal de spécialistes IA, Gemini serait désormais le modèle le plus performant du marché. Super. Mais est ce que vous savez pourquoi il est en train de gagner ?
Hé bien parce que Google possède "tout le reste". Contrairement à OpenAI qui doit quémander pour choper des utilisateurs sur son application, l'IA de Mountain View s'installe de force partout où vous êtes déjà. Dans Android, dans Chrome, et même bientôt au cœur de votre iPhone via une intégration avec Siri. C'est la stratégie Internet Explorer des années 90, mais version 2026. Brrrr…
Alors oui c'est pratique d'avoir une IA qui connaît déjà vos mails et vos photos... Sauf que non. Car Gemini utilise nos données pour absolument tout... Sous couvert de "Personal Intelligence", l'outil se connecte à vos recherches, votre historique YouTube, vos documents et vos photos. Mais pas d'inquiétude, c'est pour votre bien, évidemment. Ahahaha !
Après si vous croyez que ce pouvoir ne sera pas utilisé pour verrouiller encore plus le marché, c'est que vous avez loupé quelques épisodes. J'en parlais déjà avec l'intégration forcée de l'IA dans vos apps Android , Google change les règles du jeu en plein milieu de la partie. On se retrouve donc face à un monopole full-stack, des puces TPU maison jusqu'à l'écran de votre smartphone.
Et pendant que la Chine sécurise sa propre souveraineté cyber en virant le matos occidental, nous, on continue d'ouvrir grand la porte.... Les amis, si demain Google décide de changer ses CGU (encore) ou de monétiser votre "intelligence personnelle", vous ferez quoi ?
Bref, le géant de la recherche avance ses pions et étouffe peu à peu la concurrence avant même qu'elle puisse respirer. Notez vous ça sur un post-it afin de le relire régulièrement : Plus une IA est "intégrée", plus elle est intrusive. Donc si vous voulez vraiment garder le contrôle, il va falloir commencer à regarder du côté des modèles locaux et des alternatives qui ne demandent pas les clés de votre maison pour fonctionner.
A bon entendeur...

Google Meet now uses ultrasound to get you into meetings faster
Google Meet is rolling out a smart mobile feature that uses silent ultrasound signals to detect when you enter a conference room, automatically prompting your phone to join the right meeting in Companion mode.
The post Google Meet now uses ultrasound to get you into meetings faster appeared first on Digital Trends.

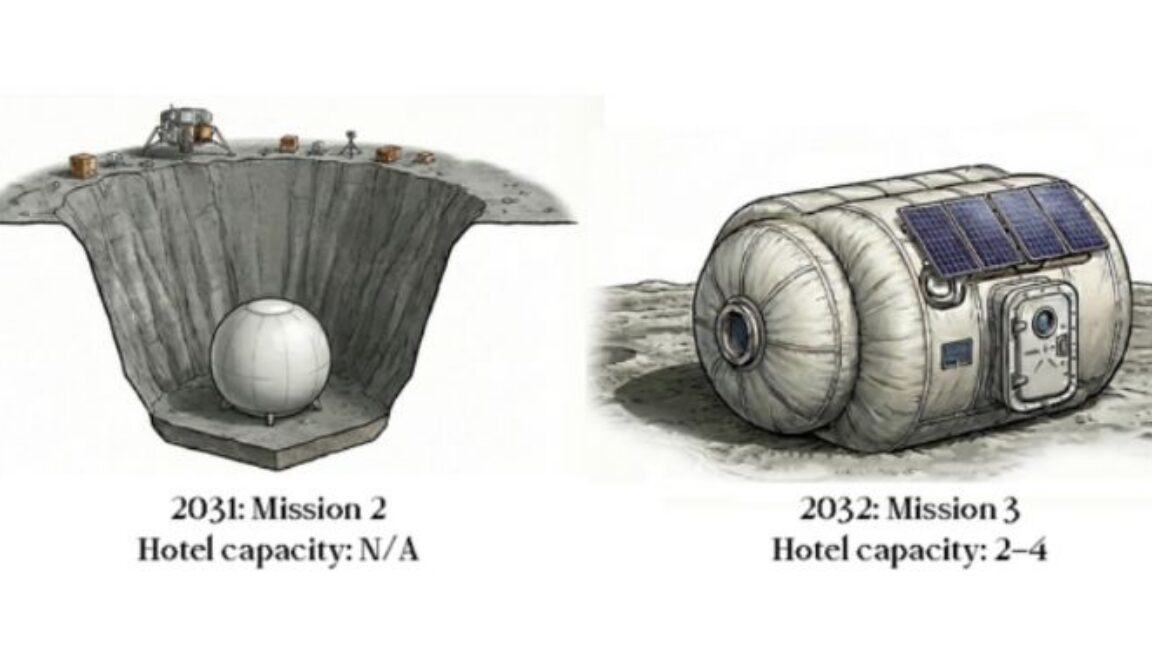
You can now reserve a hotel room on the Moon for $250,000
A company called GRU Space publicly announced its intent to construct a series of increasingly sophisticated habitats on the Moon, culminating in a hotel inspired by the Palace of the Fine Arts in San Francisco.
On Monday, the company invited those interested in a berth to plunk down a deposit between $250,000 and $1 million, qualifying them for a spot on one of its early lunar surface missions in as little as six years from now.
It sounds crazy, doesn't it? After all, GRU Space had, as of late December when I spoke to founder Skyler Chan, a single full-time employee aside from himself. And Chan, in fact, only recently graduated from the University of California, Berkeley.