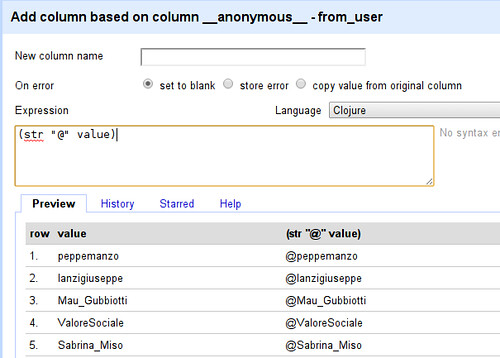
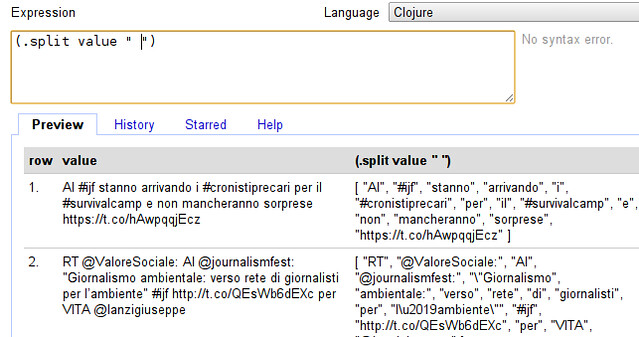
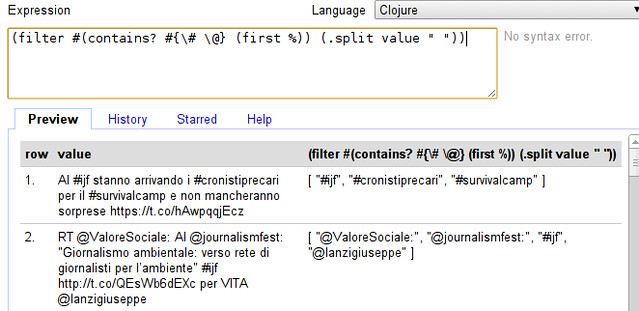
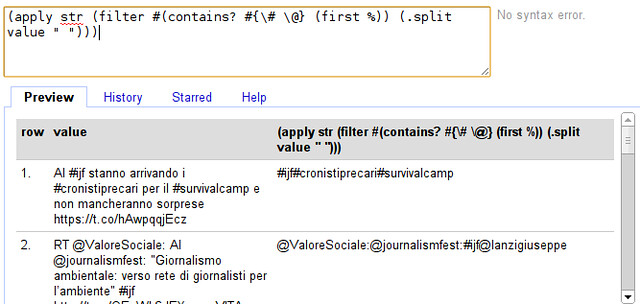
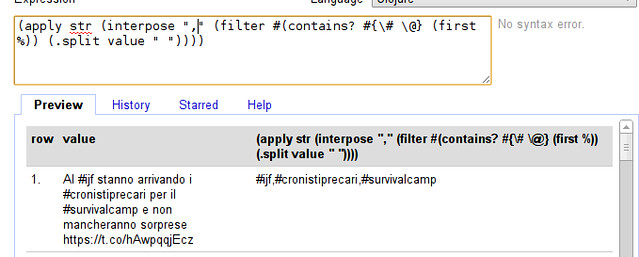
Why do we have fewer kids today, even though we are rich? In ancient societies, richer folks usually had more kids than poorer folks. Important clues should be found in the first place where fertility fell lots, France from 1750 to 1850. The fall in fertility seems unrelated to contraception and the fall in infant mortality. England at the time was richer, less agrarian and more urban, yet its fertility didn’t decline until a century later. The French were mostly rural, their farming was primitive, and they had high food prices.
A new history paper offers new clues about this early rural French decline. Within that region, the villages where fertility fell first tended to have less wealth inequality, less correlation of wealth across generations, and wealth more in the form of property relative to cash. Fertility fell first among the rich, and only in those villages; in other villages richer folks still had more kids. The French revolution aided this process by reducing wealth inequality and increasing social mobility.
It seems that in some poor rural French villages, increasing social mobility went with a revolution-aided cultural change in the status game, encouraging families to focus their social ambitions on raising a fewer higher quality kids. High status folks focused their resources on fewer kids, and your kids had a big chance to grow up high status too if only you would also focus your energies on a few of them.
It seems to me this roughly fits with the fertility hypothesis I put forward. See also my many posts on fertility. Here are many quotes from that history paper:
This analysis links fertility life histories to wealth at death data for four rural villages in France, 1750–1850. … Where fertility is declining, wealth is a powerful predictor of smaller family size. … [and] economic inequality is lower than where fertility is high. … The major difference in the wealth–fertility relationship at the individual level. Where fertility is high and non-declining, this relationship is positive. Where fertility is declining, this relationship is negative. It is the richest terciles who reduce their fertility first. … Social mobility, as proxied by the level of inequality in the villages and the perseverance of wealth within families, is associated with fertility decline. …
The exceptional fertility decline of France is a … spectacular break from the past has never been satisfactorily explained. … The decline of marital fertility during the late nineteenth century was almost completely unrelated to infant mortality decline. … Time was the best indicator for the onset of sustained fertility decline: excluding France, 59 per cent of the provinces of Europe began their fertility transition during the decades of 1890–1920. …
Any socio-economic explanation for early French fertility decline must consider that England, with a higher level of GDP per capita, a smaller agrarian sector, and a larger urbanization rate, lagged behind French fertility trends by over 100 years. … almost 80 per cent of the French population were rural, and nearly 70 per cent lived off farming at the time of the decline. … ‘farming remained primitive’ and that there were numerous indicators of overpopulation (such as increases in wheat prices from the 1760s to the 1820s). … It is widely accepted that many localities began their fertility transition long before [the Revolution of] 1789. …
Weir … states ‘evidence on fertility by social class is scarce, but tends to support the idea that fertility control was adopted by an ascendant “bourgeois” class of (often small) landowners’. … Children became ‘superfluous as labourers and costly as consumers’. The decline of fertility in France in the early-to-mid-nineteenth century was primarily due [he said] to the decline of the demand for children by this new class. … The results of this analysis support Weir’s hypothesis. … Compared to cash wealth alone, property wealth is a better predictor of the total negative wealth effect in the decline villages. …
The old social stratifications under the Ancien Régime, where hereditary rights had determined social status, were weakened by the Revolution. All of this served to facilitate individuals’ social ambition, and the limitation of family size was a tool in achieving upward social mobility. … For the villages where fertility is declining, the Gini coefficient is significantly lower than where it is not. …
Where the environment for social mobility is more open, father’s wealth should have less importance in the determination of son’s wealth than would be the case where social mobility is limited. … Where fertility is high and not declining, father’s wealth is a highly significant predictor of son’s wealth.This relationship appears to be far weaker where fertility is declining. …
Wrigley’s proposition of a neo-Malthusian response cannot be valid as it was the richest terciles who reduced their fertility, and Weir’s explanation, again, does not uniquely identify France. What was unique to France was the pattern of landholding and relatively low level of economic inequality.