Shared posts
19 Jan 00:57
系统管理员资源大全
by cucr
kahun 在 Github 发起系统管理员相关的开源资源整理。内容包括:备份/克隆软件、云计算/云存储、协作软件、配置管理、日志管理、监控、项目管理…… 当然也有系统管理员相关书籍。
另外推荐一篇文章:《10本适合于系统管理员的最佳书籍》,目前比 kahun 他们整理的列表更丰富。
伯乐在线已在 GitHub 上发起「系统管理员资源大全中文版」的整理。欢迎扩散、欢迎加入。
备份
备份软件
- Amanda -客户端-服务器模型备份工具
- Bacula – 另一个客户端-服务器模型备份工具
- Backupninja -轻量级,可扩展的元数据备份系统
- Backuppc -客户端-服务器模型备份工具和文件共享方案。
- Burp -网络备份和还原程序
- Duplicity -使用rsync算法加密的带宽-效率备份
- Lsyncd -监控一个本地目录树的变化,然后产生一个进程去同步变化。默认使用rsync。
- Rsnapshot -文件系统快照工具
- SafeKeep -使用rdiff-backup,集中的,基于pull的备份
- TarSnap – 具有一个开源客户端的安全备份服务
- UrBackup -另一个客户端-服务器备份系统
- DREBS – AWS EBS支持策略的备份脚本
克隆
克隆软件
- Clonezilla -分区和磁盘镜像/克隆程序
- Fog – 另一个计算机克隆解决方案
- Redo Backup -简单的备份,恢复和还原
云计算
- AppScale – 兼容Google App引擎的开源云计算软件.
- Archipel -使用Libvirt管理和监视虚拟机
- CloudStack -创建,管理和部署基础云服务的云计算软件
- Cobbler -Cobbler是一个Linux安装服务器,允许快速地构建网络安装环境
- Eucalyptus -兼容AWS的开源私有云软件
- Mesos -开发和运行能效高的分布式系统。
- OpenNebula -一个用于系统管理员和研发运维的用户驱动的云管理平台
- OpenStack -构建私有和开放云的开源软件
- The Foreman -Foreman是一个用于物理和虚拟服务器的全生命周期管理工具.FOSS.
云业务流程
- BOSH -IaaS业务流程平台,最初用于部署和管理云计算平台PaaS,但也用于通用的分布式系统。
- Cloudify -使用Python和YAML编写的开源TOSCA-based云业务流程软件平台。
- Juju -云业务流程工具用于管理服务,比如charms,YAML配置和部署脚本集
- MCollective -来自Puppet实验室的管理服务器业务流程和开发的Ruby框架
- Overcast -在不同的云提供商上部署VMs,并在任何或所有(VM)上通过SSH并行运行命令行和脚本
- Rundeck – 简单的业务流程工具
- Salt -Python编写
云存储
- git-annex assistant -在你的每一个OSX和Linux电脑,Android设备,可移动驱动,NAS电器和云服务上一个同步文件夹
- ownCloud -提供你的文件的统一访问,通过web,你的电脑和你的移动设备
- Seafile -另一个开源的云存储解决方案
- SparkleShare -提供云存储和文件同步服务。它默认使用Git作为存储后端
- Swift -一个高可用,分布式,最终一致的对象/大数据存储
- Syncthing -一个用于私有,加密和身份认证数据的开源系统
代码审查
基于Web的协作式代码审查系统
- Gerrit -基于Git版本控制,它促进软件开发人员审查源代码修改和批准或拒绝这些变更。
- Review Board – 基于MIT License的可用自由软件
协作软件
协作软件和群件套件
- Citadel/UX -协同套件(消息和群件)继承于Citadel家族程序
- EGroupware -PHP编写的群件软件
- Horde Groupware -基于PHP的协作软件套件,包括邮件,日历,wiki,时间跟踪和文件管理
- Kolab – 另一个群件套件
- SOGo – 协作软件服务器,专注简单性和可伸缩性
- Zimbra -协作软件套件,包括邮件服务和web客户端
配置管理数据库
配置管理数据库(CMDB)软件
- i-doit – 开源的IT文档管理和CMDB
- iTop -一个完全开源的,ITIL,基于web的服务管理工具
- Ralph -用于大型数据中心或较小本地网络的资产管理,DICM和CMDB系统
- Clusto -帮助跟踪你的库存,在哪,如何连接,同时提供一个和基础架构元素交互的抽象接口
配置管理
配置管理工具
- Ansible -Python编写的,通过SSH管理节点
- CFEngine -轻量级代理系统。通过申明语言配置状态。
- Chef -Rbuy和Erlang编写,使用纯RubyDSL
- Fabric – Python库和cli工具,为应用程序部署或系统管理任务简化使用SSH。
- Pallet -通过Clojure DSL进行架构定义,配置和管理
- Puppet – Ruby编写,使用Puppet声明语言或Rbuy DSL
- Salt – Python编写
- Slaughter – Perl编写
持续继承和持续部署
持续集成/部署软件
- Buildbot – 基于Python的持续集成工具
- Drone – 构建在Docker,使用YAML文件配置的的持续集成服务器
- GitLab CI -基于rbuy。他们也提供GitLab用于管理git存储库
- Go – 开源的持续交付服务器
- Jenkins – 一个可扩展的开源持续集成服务器
- Vlad the Deployer -自动化部署
分布式文件系统
网络分布式文件系统
- GlusterFS – 可扩展,网络附加存储文件系统。
- HDFS – Java编写的,用于Hadoop框架的分布式、可伸缩、可移植文件系统
- Lustre -一种并行分布式文件系统,一般用于大规模集群计算。
- MooseFS – 容错、网络分布式文件系统。
- MogileFS -应用程序级别、网络分布式文件系统。
- OpenAFS -只读副本和多操作系统支持的分布式网络文件系统
DNS
DNS服务器
- Bind -最广泛使用的域名服务软件
- djbdns -DNS应用集合,包括tinydns
- Designate – DNS REST API,支持多种DNS服务器的后端
- dnsmasq -为小规模网络提供DNS,DHCP和TFTP服务的轻量级服务
- Knot – 高性能,权威的DNS服务器
- NSD – 权威的、高性能的、简单的域名服务器。
- PowerDNS -具有各种数据存储后端和负载平衡功能的DNS服务器。
- Unbound – 验证、递归和缓存DNS解析器。
- Yadifa – 具有DNSSEC兼容的轻量级的权威域名服务器,支持.eu的顶级域名。
主机控制面板
Web主机控制面板
- Ajenti -Linux和BSD控制面板
- Feathur – VPS供应和管理软件
- ISPConfig -Linux主机控制面板
- VestaCP -用于Linux和Nginx的主机面板
- Virtualmin -基于webmin的Linux控制面板
- ZPanel -Linux BSD和Windows控制面板
IMAP/POP3
IMAP/POP3邮件服务器
- Courier IMAP/POP3 -快速,可伸缩,企业级IMAP和POP3服务器
- Cyrus IMAP/POP3 -运行在密封服务器上,普通用户不允许登录。
- Dovecot -主要考虑安全而编写的IMAP和POP3服务器
- Qpopper – 一个古老且流行的POP3服务器实现
IT资产管理
IT资产管理软件
- GLPI -带有额外管理接口的信息资源管理器
- OCS Inventory NG -允许用户清算IT资产
- RackTables -数据中心和服务器房间资产,比如将硬件资产,网络地址,在货架空间,网络配置文档化。
- Ralph – 针对大型数据中心系统以及小型局域网网络的资产管理、DCIM和CMDB。
- Snipe IT -资产和许可证管理软件
LDAP
LDAP服务器
- 389 Directory Server – 通过Red Hat部署
- Apache Directory Server -用Java编写的Apache软件基金会项目
- Fusion Directory -基于OpenLDAP改善服务和公司目录的管理
- OpenDJ – OpenDS分支
- OpenDS -另一个用Java编写的目录服务器
- OpenLDAP -由OpenLDAP项目开发
日志管理
日志管理工具:收集,解析,可视化
- Elasticsearch – 一个基于Lucene的文档存储,主要用于日志索引、存储和分析。
- Fluentd – 日志收集和发出
- Flume -分布式日志收集和聚合系统
- Graylog2 -具有报警选项的可插入日志和事件分析服务器
- Heka -流处理系统,可用于日志聚合
- Kibana – 可视化日志和时间戳数据
- Logstash -管理事件和日志的工具
- Octopussy -日志管理解决方案(可视化/报警/报告)
监控
监控软件
- Cacti -基于Web的网络监控和图形工具
- Cabot – 监控和报警,类似PagerDuty
- check_mk -Nagios的扩展集合
- Dash -一个用于GNU/Linux机器的低开销web仪表板监控。
- Icinga – Nagios分支
- LibreNMS – Observium分支
- Monit – 管理和监控Unix系统的小型开源工具
- Munin -网络资源监控工具
- Naemon -基于Nagios4内核的网络监控工具,具有性能加强和新功能
- Nagios -计算机系统,网络和基础架构监控软件
- Observium -服务器和网络设备的SNMP监控,运行在linux
- OMD -开放的监控分布
- Opsview -基于Nagios4,Opsview核心,用于小型IT和测试环境
- Riemann -灵活和快速的事件处理器,允许负责时间和度量分析
- Sensu -开源的监控框架
- Sentry – 应用监控,事件记录和聚合
- Shinken – 另一个监控框架
- Thruk – 多后台监控的web接口,支持Naemon,Nagios,Icinga和Shinken
- Xymon -灵感来自Big Brother的网络监控
- Zabbix – Enterprise-class software for monitoring of networks and applications.
- Zabbix – 监控网络和应用的企业级软件
- Zenoss -基于Zope的应用,服务器和网络管理平台
度量和度量收集
度量收集和显示软件
- Collectd -系统统计收集守护进程
- Collectl -高精度系统性能指标收集工具。
- Dashing -Ruby gem,允许快速统计仪表板的开发。基于HTML5,允许在数据中心或会议室进行大屏幕显示。
- Diamond -基于Python的统计收集守护进程
- Ganglia – 基于RRD用于网格和/或集群的服务器的高性能、可伸缩监控设备。兼容Graphite,使用一个单一的收集进程。
- Grafana -一个Graphite或InfluxDB仪表盘和图形编辑器
- 开源的可伸缩绘图服务器
- InfluxDB -开源的分布式时间序列数据库,没有外部依赖。
- KairosDB -快速分布式可扩展的时间序列数据库,OpenTSDB 1. x的分支。
- OpenTSDB -存储和服务大量的时间序列数据,不丢失粒度。
- RRDtool – 开源企业标准,用于时间序列数据的高性能数据记录和绘图系统
- Statsd -应用统计监听
网络配置管理
网络配置管理工具
时事通讯
时事通讯软件
NOSQL
NOSQL数据库
- 列族
- Apache HBase – Hadoop数据库,一个分布式的大数据存储
- Cassandra -分布式数据库管理系统,设计用于处理大量数据跨多个服务器。
- Hypertable -基于c++的bigtable DBMS,节省通信,可独立或在Hadoop类似的分布式FS上运行。
- 文档存储
- CouchDB -易于使用,多主机复制的面向文档的数据库系统。
- ElasticSearch – 基于Java的数据库,受欢迎的日志聚合,和电子邮件归档项目。
- MongoDB – 另一个面向文档的数据库系统
- RavenDB – 具有ACID/事物功能的基于文档的数据库
- RethinkDB -开源分布式文档存储数据库,关注JSON
- 图
- 键值
NoSQL服务器比较: http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
打包
- fpm – 万能的多格式包创建器
- omnibus-ruby – 全栈,跨发行版的包管理软件(Ruby)
- packman -全栈,跨发行版的包管理软件(Python)
- tito – 为git项目构建RPM
队列
- BeanstalkD – A simple, fast work queue.
- BeanstalkD – 一个简单快速的工作队列
- Gearman -快速的多语言队列或任务处理平台
- NSQ – 实时分发的消息平台
- RabbitMQ -健壮的,全功能,跨发行版的队列系统
- ZeroMQ -轻量级队列系统
RDBMS
关系数据库管理系统
- Firebird – 真正的全球开源数据库
- Galera -Galera MySQL集群是一个易于使用的高可用性解决方案,具有很高的系统正常运行时间,没有数据丢失,为未来的增长提供可伸缩性。
- MariaDB -MySQL的社区开发分支
- MySQL – 非常流行的RDBMS服务器
- Percona Server -增强的,可替换MySQL
- PostgreSQL – 对象关系数据库管理系统(ORDBMS)
- PostgreSQL-XL – 基于PostgreSQL的可伸缩开源数据库集群
- SQLite -自包容,弱服务器,零配置,支持事务的SQL DBS实现库
安全
安全工具
- Denyhosts -阻止SSH字典攻击和暴力攻击
- Fail2Ban – 扫描日志文件,并对具有恶意行为显示的IP采取措施
- SpamAssassin -一个强大的和受欢迎的垃圾邮件过滤器,它采用多种检测技术。
服务发现
- Consul – Consule是伊戈尔服务发现,监控和配置的工具
- Doozerd – Doozer是一个高可用,完全一致的存储,用于少量非常重要的数据
- ZooKeeper – ZooKeeper是一个集中的服务,用于维护配置信息,命名,提供分布式同步和组服务
SMTP
SMTP服务器
- Exim -由剑桥大学开发的消息传输代理(MTA)
- Haraka – 用JavaScirpt编写的高性能,可插入的SMTP服务器
- MailCatcher -Ruby gem部署一个简单的SMTP MTA网关,接收所有邮件并在web接口显示。对调试和开发有用。
- Maildrop -开源的一次性邮件服务器,对开发也很有用
- OpenSMTPD -从OpenBSD项目实现的安全的SMTP服务器
- Postfix – 快速,易于管理和安全的Sendmail替代品
- Qmail – 安全的Sendmail替代品
- Sendmail -消息传输代理(MTA)
软件容器
操作系统级别的虚拟化
- Bitnami -为web应用,开发栈和虚拟设备生产开源软件安装器或软件包
- Docker – 给开发者和系统管理员构建,发布和运行分布式应用程序的开放平台
- OpenVZ -Linux平台基于容器的虚拟化
SSH
SSH工具
- autossh -网络中断后自动复位ssh会话。
- Cluster SSH -通过一个图形化控制台控制多个xterm窗口。
- DSH -Dancer的shell/分布式shell-从一个命令行包装执行多个远程shell命令。
- Mosh – 移动shell
- parallel-ssh -提供并行的OpenSSH版本和相关工具
- SSH Power Tool -不使用pre-shared钥匙的情况下对多个服务器同时执行命令和上传文件
统计
分析软件
- Analog – 世界上最流行的日志分析工具
- GoAccess -在终端运行的开源的实时web日志分析和交互视图
- Piwik -免费和开源的web分析应用
- Webalizer – F快速免费的web服务器日志文件分析程序
工单系统
基于web的工单系统
- Bugzilla -由Mozilla项目开发和使用过的通用缺陷跟踪和测试工具
- Cerb – 基于商业开源许可的基于组的邮件管理项目
- Flyspray – 使用PHP编写的缺陷跟踪系统
- MantisBT -另一个基于web的缺陷跟踪系统
- osTicket -开源的技术支持工单系统
- Otrs -免费和开源故障通知单系统软件包,公司,组织,或其他实体可以使用它来基于询问分配工单并跟踪进一步的沟通。
- Request Tracker -使用Perl编写的工单跟踪系统
- TheBugGenie -开源的工单系统,具有非常完备的用户权限分配
故障排除
故障排除工具
- mitmproxy -ython工具,用于拦截,查看和修改网络流量。在排除某些问题是非常重要的。
- Sysdig -从一个运行的linux实例上捕获系统状态和活动,之后保存,过滤和分析
- Wireshark -世界上著名的网络协议分析工具
项目管理
基于web的项目管理和缺陷跟踪系统
- ChiliProject – Redmine分支
- GitBucket 用Scala编写的GitHub的克隆,单独jar安装
- GitLab -用Rbuy编写的GitHub的克隆
- Gogs -用Go编写
- OpenProject -开源的项目协作项目
- Phabricator PHP编写
- Redmine – 基于rails在rbuy编写
- The Bug Genie -PHP编写
- Trac -python编写
版本控制
软件版本和版本控制
- Fossil -分布式版本控制,内建wiki和缺陷跟踪
- Git -速度很快的分布式版本控制和源代码管理
- GNU Bazaar -由Cannoicalzi赞助的分布式版本控制系统
- Mercurial -另一个版本控制
- Subversion -客户端-服务器版本控制系统
虚拟化
虚拟化软件
- Ganeti -在KVM和Xen上构建的集群虚拟服务器管理软件
- KVM -Linux内核虚拟化架构
- oVirt -管理虚拟机,存储和虚拟网络
- Packer – 从单个源配置为多个平台创建相同的机器镜像
- Vagrant – 创建完整开发环境的工具
- VirtualBox -来自Oracle公司的虚拟化产品
- Xen -用于32/64位Intel/AMD(IA 64)和PowerPC 970架构的虚拟机监控器
VPN
VPN软件
- OpenVPN -使用一个定制的安全密钥交换协议,利用SSL / TLS。
- Pritunl -基于OpenVPN的方案,易于设置
- SoftEther – 具有高级特性的多协议VPN软件
- sshuttle -穷人的VPN
- strongSwan – Linux下完整的IPsec实现
- tinc -分布式点对点VPN
XMPP
XMPP服务器
- ejabberd -用Erlang/OTP编写的XMPP短信服务器
- Metronome IM -Prosody IM分支
- MongooseIM -ejabberd分支
- Openfire -实时协作(RTC)服务器
- Prosody IM -Lua编写的XMPP服务器
- Tigase -java实现的XMPP服务器
Webmails
Webmail应用
- Mailpile – A modern, fast web-mail client with user-friendly encryption and privacy features.
- Mailpile – 一个先进,快速的web-mail客户端,具有用户友好的加密的私有个性
- Roundcube – Browser-based IMAP client with an application-like user interface.
- Roundcube – 基于浏览器的IMAP客户端,具有应用类似的用户界面
Web
Web服务器
- Apache -最流行的web服务器
- Cherokee -轻量级,高性能的web服务器/反向代理
- Lighttpd – speed-critical环境下更优化的web服务器
- Nginx -反向代理,负载均衡器,HTTP缓存和web服务器
- uWSGI -uWSGI项目,目标在开发一个构建主机服务的全栈
Web性能
Wikis
Wiki软件
- DokuWiki -使用简单和高度通用的wiki,这并不需要一个数据库。
- Gollum – 一个简单,Git-powered wiki,具有不错的API和本地前端。
- ikiwiki -一个wiki编译器
- Mediawiki -加强Wikipedia
-
MoinMoin -一个高级的易用的扩展性强的Wiki引擎,具有大量的社区用户TiddlyWiki – JavaScript的完整交互wiki
- Ōlelo Wiki – 在Git存储上保存页面的wiki
资源
各种资源,比如书籍,网站和文章,用于提升技能和知识
博客
- Code as Craft – Etsy的运维博客,大量的技术博客
- DevOpsGuys – Devops顾问,运维博客
- Rackspace Developers -具有大量Devops主题的博客
书籍
Sysadmin相关书籍
- The Linux Command Line – William Shotts的书,关于Linux命令行
- The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win -DevOps技术如何修复发生在IT组织的问题
- The Practice of System and Network Administration – 第一和第二版本描述系统和网络管理的最佳实践,独立于特定平台或技术。
- The Visible Ops Handbook: Implementing ITIL in 4 Practical and Auditable Steps -一个方法论,旨在启动实施控制和过程改进。
- UNIX and Linux System Administration Handbook – 从使用的角度走进系统管理
编辑器
开源的代码编辑器
- Atom -来自Github的文本编辑器
- Brackets – 用于web设计和前端开发的开源代码编辑器
- Eclipse – 用Java编写的IDE,具有可扩展的插件系统
- Geany -GTK2文本编辑器
- GNU Emacs -一个可扩展,自定义的文本编辑器
- Haroopad -Markdown编辑器,具有实时预览
- ICEcoder -非常棒的代码编辑器,内建常见的web语言
- jotgit -Git支持的实时协作代码编辑
- Light Table – 下一代代码编辑器
- Lime -旨在提供一个Sublime Text的开源替代方案
- TextMate -OS X下的图形文本编辑器
- Vim -一个高可配置的文本编辑器,用于高效编辑
时事通讯
- Servers for Hackers – 程序员的时事通讯,发现他们需要知道的服务器相关内容。
存储
软件包存储
网站
有用的系统管理员相关的网站
- Ops School – 全面的计划,将帮助你成为一名运维工程师。
- Digital Ocean Tutorials – 一个非常庞大资源,获得基本的应用程序,工具,甚至是系统管理主题。
伯乐在线已在 GitHub 上发起「系统管理员资源大全中文版」的整理。欢迎扩散、欢迎加入。
17 Jan 01:23
文章: Java多线程编程模式实战指南(二):Immutable Object模式
by 黄文海
多线程共享变量的情况下,为了保证数据一致性,往往需要对这些变量的访问进行加锁。而锁本身又会带来一些问题和开销。Immutable Object模式使得我们可以在不使用锁的情况下,既保证共享变量访问的线程安全,又能避免引入锁可能带来的问题和开销。
Immutable Object模式简介
多线程环境中,一个对象常常会被多个线程共享。这种情况下,如果存在多个线程并发地修改该对象的状态或者一个线程读取该对象的状态而另外一个线程试图修改该对象的状态,我们不得不做一些同步访问控制以保证数据一致性。而这些同步访问控制,如显式锁和CAS操作,会带来额外的开销和问题,如上下文切换、等待时间和ABA问题等。Immutable Object模式的意图是通过使用对外可见的状态不可变的对象(即Immutable Object),使得被共享对象“天生”具有线程安全性,而无需额外的同步访问控制。从而既保证了数据一致性,又避免了同步访问控制所产生的额外开销和问题,也简化了编程。
所谓状态不可变的对象,即对象一经创建其对外可见的状态就保持不变,例如Java中的String和Integer。这点固然容易理解,但这还不足以指导我们在实际工作中运用Immutable Object模式。下面我们看一个典型应用场景,这不仅有助于我们理解它,也有助于在实际的环境中运用它。

一个车辆管理系统要对车辆的位置信息进行跟踪,我们可以对车辆的位置信息建立如清单1所示的模型。
清单 1. 状态可变的位置信息模型(非线程安全)
public class Location {
private double x;
private double y;
public Location(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() {
return x;
}
public double getY() {
return y;
}
public void setXY(double x, double y) {
this.x = x;
this.y = y;
}
}
当系统接收到新的车辆坐标数据时,需要调用Location的setXY方法来更新位置信息。显然,清单1中setXY是非线程安全的,因为对坐标数据x和y的写操作不是一个原子操作。setXY被调用时,如果在x写入完毕,而y开始写之前有其它线程来读取位置信息,则该线程可能读到一个被追踪车辆根本不曾经过的位置。为了使setXY方法具备线程安全性,我们需要借助锁进行访问控制。虽然被追踪车辆的位置信息总是在变化,但是我们也可以将位置信息建模为状态不可变的对象,如清单2所示。
清单 2. 状态不可变的位置信息模型
public final class Location {
public final double x;
public final double y;
public Location(double x, double y) {
this.x = x;
this.y = y;
}
}
使用状态不可变的位置信息模型时,如果车辆的位置发生变动,则更新车辆的位置信息是通过替换整个表示位置信息的对象(即Location实例)来实现的。如清单3所示。
清单 3. 在使用不可变对象的情况下更新车辆的位置信息
public class VehicleTracker {
private Map<String, Location> locMap
= new ConcurrentHashMap();
public void updateLocation(String vehicleId, Location newLocation) {
locMap.put(vehicleId, newLocation);
}
}
因此,所谓状态不可变的对象并非指被建模的现实世界实体的状态不可变,而是我们在建模的时候的一种决策:现实世界实体的状态总是在变化的,但我们可以用状态不可变的对象来对这些实体进行建模。
Immutable Object模式的架构
Immutable Object模式的主要参与者有以下几种。其类图如图1所示。
图 1. Immutable Object模式的类图

-
ImmutableClass:负责存储一组不可变状态的类。该类不对外暴露任何可以修改其状态的方法,其主要方法及职责如下:
getStateX,getStateN:这些getter方法返回该类所维护的状态相关变量的值。这些变量在对象实例化时通过其构造器的参数获得值。
getStateSnapshot:返回该类维护的一组状态的快照。
-
Manipulator:负责维护ImmutableClass所建模的现实世界实体状态的变更。当相应的现实世界实体状态变更时,该类负责生成新的ImmutableClass的实例,以反映新的状态。
changeStateTo:根据新的状态值生成新的ImmutableClass的实例。
不可变对象的使用主要包括以下几种类型:
获取单个状态的值:调用不可变对象的相关getter方法即可实现。
获取一组状态的快照:不可变对象可以提供一个getter方法,该方法需要对其返回值做防御性拷贝或者返回一个只读的对象,以避免其状态对外泄露而被改变。
生成新的不可变对象实例:当被建模对象的状态发生变化的时候,创建新的不可变对象实例来反映这种变化。
Immutable Object模式的典型交互场景如图2所示:
图 2. Immutable Object模式的序列图

1~4、客户端代码获取ImmutableClass的各个状态值。
5、客户端代码调用Manipulator的changeStateTo方法来更新应用的状态。
6、Manipulator创建新的ImmutableClass实例以反映应用的新状态。
7~9、客户端代码获取新的ImmutableClass实例的状态快照。
一个严格意义上不可变对象要满足以下所有条件:
1) 类本身使用final修饰:防止其子类改变其定义的行为;
2) 所有字段都是用final修饰的:使用final修饰不仅仅是从语义上说明被修饰字段的引用不可改变。更重要的是这个语义在多线程环境下由JMM(Java Memory Model)保证了被修饰字段的所引用对象的初始化安全,即final修饰的字段在其它线程可见时,它必定是初始化完成的。相反,非final修饰的字段由于缺少这种保证,可能导致一个线程“看到”一个字段的时候,它还未被初始化完成,从而可能导致一些不可预料的结果。
3) 在对象的创建过程中,this关键字没有泄露给其它类:防止其它类(如该类的匿名内部类)在对象创建过程中修改其状态。
4) 任何字段,若其引用了其它状态可变的对象(如集合、数组等),则这些字段必须是private修饰的,并且这些字段值不能对外暴露。若有相关方法要返回这些字段值,应该进行防御性拷贝(Defensive Copy)。
Immutable Object模式实战案例
某彩信网关系统在处理由增值业务提供商(VASP,Value-Added Service Provider)下发给手机终端用户的彩信消息时,需要根据彩信接收方号码的前缀(如1381234)选择对应的彩信中心(MMSC,Multimedia Messaging Service Center),然后转发消息给选中的彩信中心,由其负责对接电信网络将彩信消息下发给手机终端用户。彩信中心相对于彩信网关系统而言,它是一个独立的部件,二者通过网络进行交互。这个选择彩信中心的过程,我们称之为路由(Routing)。而手机号前缀和彩信中心的这种对应关系,被称为路由表。路由表在软件运维过程中可能发生变化。例如,业务扩容带来的新增彩信中心、为某个号码前缀指定新的彩信中心等。虽然路由表在该系统中是由多线程共享的数据,但是这些数据的变化频率并不高。因此,即使是为了保证线程安全,我们也不希望对这些数据的访问进行加锁等并发访问控制,以免产生不必要的开销和问题。这时,Immutable Object模式就派上用场了。
维护路由表可以被建模为一个不可变对象,如清单4所示。
清单 4. 使用不可变对象维护路由表
public final class MMSCRouter {
// 用volatile修饰,保证多线程环境下该变量的可见性
private static volatile MMSCRouter instance = new MMSCRouter();
//维护手机号码前缀到彩信中心之间的映射关系
private final Map<String, MMSCInfo> routeMap;
public MMSCRouter() {
// 将数据库表中的数据加载到内存,存为Map
this.routeMap = MMSCRouter.retrieveRouteMapFromDB();
}
private static Map<String, MMSCInfo> retrieveRouteMapFromDB() {
Map<String, MMSCInfo> map = new HashMap<String, MMSCInfo>();
// 省略其它代码
return map;
}
public static MMSCRouter getInstance() {
return instance;
}
/**
* 根据手机号码前缀获取对应的彩信中心信息
*
* @param msisdnPrefix
* 手机号码前缀
* @return 彩信中心信息
*/
public MMSCInfo getMMSC(String msisdnPrefix) {
return routeMap.get(msisdnPrefix);
}
/**
* 将当前MMSCRouter的实例更新为指定的新实例
*
* @param newInstance
* 新的MMSCRouter实例
*/
public static void setInstance(MMSCRouter newInstance) {
instance = newInstance;
}
private static Map<String, MMSCInfo> deepCopy(Map<String, MMSCInfo> m) {
Map<String, MMSCInfo> result = new HashMap<String, MMSCInfo>();
for (String key : m.keySet()) {
result.put(key, new MMSCInfo(m.get(key)));
}
return result;
}
public Map<String, MMSCInfo> getRouteMap() {
//做防御性拷贝
return Collections.unmodifiableMap(deepCopy(routeMap));
}
}
而彩信中心的相关数据,如彩信中心设备编号、URL、支持的最大附件尺寸也被建模为一个不可变对象。如清单5所示。
清单 5. 使用不可变对象表示彩信中心信息
public final class MMSCInfo {
/**
* 设备编号
*/
private final String deviceID;
/**
* 彩信中心URL
*/
private final String url;
/**
* 该彩信中心允许的最大附件大小
*/
private final int maxAttachmentSizeInBytes;
public MMSCInfo(String deviceID, String url, int maxAttachmentSizeInBytes) {
this.deviceID = deviceID;
this.url = url;
this.maxAttachmentSizeInBytes = maxAttachmentSizeInBytes;
}
public MMSCInfo(MMSCInfo prototype) {
this.deviceID = prototype.deviceID;
this.url = prototype.url;
this.maxAttachmentSizeInBytes = prototype.maxAttachmentSizeInBytes;
}
public String getDeviceID() {
return deviceID;
}
public String getUrl() {
return url;
}
public int getMaxAttachmentSizeInBytes() {
return maxAttachmentSizeInBytes;
}
}
彩信中心信息变更的频率也同样不高。因此,当彩信网关系统通过网络(Socket连接)被通知到这种彩信中心信息本身或者路由表变更时,网关系统会重新生成新的MMSCInfo和MMSCRouter来反映这种变更。如清单6所示。
清单 6. 处理彩信中心、路由表的变更
/**
* 与运维中心(Operation and Maintenance Center)对接的类
*
*/
public class OMCAgent extends Thread{
@Override
public void run() {
boolean isTableModificationMsg=false;
String updatedTableName=null;
while(true){
//省略其它代码
/*
* 从与OMC连接的Socket中读取消息并进行解析,
* 解析到数据表更新消息后,重置MMSCRouter实例。
*/
if(isTableModificationMsg){
if("MMSCInfo".equals(updatedTableName)){
MMSCRouter.setInstance(new MMSCRouter());
}
}
//省略其它代码
}
}
}
上述代码会调用MMSCRouter的setInstance方法来替换MMSCRouter的实例为新创建的实例。而新创建的MMSCRouter实例通过其构造器会生成多个新的MMSCInfo的实例。
本案例中,MMSCInfo是一个严格意义上的不可变对象。虽然MMSCRouter对外提供了setInstance方法用于改变其静态字段instance的值,但它仍然可视作一个等效的不可变对象。这是因为,setInstance方法仅仅是改变instance变量指向的对象,而instance变量采用volatile修饰保证了其在多线程之间的内存可见性,这意味着setInstance对instance变量的改变无需加锁也能保证线程安全。而其它代码在调用MMSCRouter的相关方法获取路由信息时也无需加锁。
从图1的类图上看,OMCAgent类(见清单6)是一个Manipulator参与者实例,而MMSCInfo、MMSCRouter是一个ImmutableClass参与者实例。通过使用不可变对象,我们既可以应对路由表、彩信中心这些不是非常频繁的变更,又可以使系统中使用路由表的代码免于并发访问控制的开销和问题。
Immutable Object模式的评价与实现考量
不可变对象具有天生的线程安全性,多个线程共享一个不可变对象的时候无需使用额外的并发访问控制,这使得我们可以避免显式锁(Explicit Lock)等并发访问控制的开销和问题,简化了多线程编程。
Immutable Object模式特别适用于以下场景。
被建模对象的状态变化不频繁:正如本文案例所展示的,这种场景下可以设置一个专门的线程(Manipulator参与者所在的线程)用于在被建模对象状态变化时创建新的不可变对象。而其它线程则只是读取不可变对象的状态。此场景下的一个小技巧是Manipulator对不可变对象的引用采用volatile关键字修饰,既可以避免使用显式锁(如synchronized),又可以保证多线程间的内存可见性。
同时对一组相关的数据进行写操作,因此需要保证原子性:此场景为了保证操作的原子性,通常的做法是使用显式锁。但若采用Immutable Object模式,将这一组相关的数据“组合”成一个不可变对象,则对这一组数据的操作就可以无需加显式锁也能保证原子性,既简化了编程,又提高了代码运行效率。本文开头所举的车辆位置跟踪的例子正是这种场景。
使用某个对象作为安全的HashMap的Key:我们知道,一个对象作为HashMap的Key被“放入”HashMap之后,若该对象状态变化导致了其Hash Code的变化,则会导致后面在用同样的对象作为Key去get的时候无法获取关联的值,尽管该HashMap中的确存在以该对象为Key的条目。相反,由于不可变对象的状态不变,因此其Hash Code也不变。这使得不可变对象非常适于用作HashMap的Key。
Immutable Object模式实现时需要注意以下几个问题:
被建模对象的状态变更比较频繁:此时也不见得不能使用Immutable Object模式。只是这意味着频繁创建新的不可变对象,因此会增加GC(Garbage Collection)的负担和CPU消耗,我们需要综合考虑:被建模对象的规模、代码目标运行环境的JVM内存分配情况、系统对吞吐率和响应性的要求。若这几个方面因素综合考虑都能满足要求,那么使用不可变对象建模也未尝不可。
使用等效或者近似的不可变对象:有时创建严格意义上的不可变对象比较难,但是尽量向严格意义上的不可变对象靠拢也有利于发挥不可变对象的好处。
防御性拷贝:如果不可变对象本身包含一些状态需要对外暴露,而相应的字段本身又是可变的(如HashMap),那么在返回这些字段的方法还是需要做防御性拷贝,以避免外部代码修改了其内部状态。正如清单4的代码中的getRouteMap方法所展示的那样。
总结
本文介绍了Immutable Object模式的意图及架构。并结合笔者工作经历提供了一个实际的案例用于展示使用该模式的典型场景,在此基础上对该模式进行了评价并分享在实际运用该模式时需要注意的事项。
参考资源
- 本文的源代码在线阅读:https://github.com/Viscent/JavaConcurrencyPattern/
- Brian Göetz,Java theory and practice: To mutate or not to mutate?:http://www.ibm.com/developerworks/java/library/j-jtp02183/index.html
- Brian Göetz et al.,Java Concurrency In Practice
- Mark Grand,Patterns in Java,Volume 1, 2nd Edition
- Java Language Specification,17.5. final Field Semantics:http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html
作者简介
黄文海,有多年敏捷项目管理经验和丰富的技术指导经验。关注敏捷开发、Java多线程编程和Web开发。在InfoQ中文站和IBM DeveloperWorks上发表过多篇文章。其博客:http://viscent.iteye.com/
感谢张龙对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ)或者腾讯微博(@InfoQ)关注我们,并与我们的编辑和其他读者朋友交流。
Ernest likes this
17 Jan 01:22
Docker周报:Docker公司是如何做社区的?
by 郭蕾
新闻
《Gartner表示Docker安全性“尚不成熟”,但却谈不上可怕》:近日,Gartner公司的分析师撰文《Docker管理下的容器安全性评估》指出,Linux容器在成熟程度方面已经足以应对私有以及公有PaaS的实际需求,但在安全性管理与控制方面的表现却令人失望。不过,文章也同时指出,由于Docker还是一项年轻的技术,因此目前尚未积累能够满足实际生产需求的生态系统完全可以理解。
《DockerCon欧洲大会第二天视频以及PPT》:目前Docker官方已经公布DockerCon欧洲第二天的视频以及PPT,内容依旧精彩,包括容器编排以及管理技术,比如Consul、Mesos、Clocker,同时,一些用户诸如Shopify、Weeby也分享了他们的使用经验。
《Docker公司是如何做社区的?》:Docker从发布之初就受到了开发者的关注,1.0版本发布的时候Docker就收到了超过460位贡献者的8741条改进建议,Docker也承认是社区帮助他们迅速达到了这一新的里程碑。近日,Docker社区经理分享了Docker在社区孕育方面的经验。
《微服务 + Docker + 云平台 =ESB的死亡》:在过去SOA中服务是一种粗粒度的服务,也就是与微服务相反,粗粒度的服务有两个好处:易于重用,减轻ESB的负载;而微服务催生,比如对事件总线的性能和可靠性要求提高,微服务之间的通讯几近类似于两个单个对象之间交互调用,性能称为至关重要。
教程
《Docker网络详解及pipework源码解读与实践》:本文首先介绍了Docker自身的四种网络工作方式,然后通过三个样例 —— 将Docker容器配置到本地网络环境中、单主机Docker容器的VLAN划分、多主机Docker容器的VLAN划分,演示了如何使用pipework帮助我们进行复杂的网络设置,以及pipework是如何工作的。
《从Docker Hub和docker-registry看优秀的后端服务设计实现》:本文通过研究Docker Hub和docker-registry的架构,介绍了在服务端Docker镜像的存储、管理、安全的架构设计,并给出了一次简单的Docker客户端服务端交互的过程。对于部署实现一个大规模、企业级的镜像库需要做的工作做了初步的探讨,汇总了需要准备的前期知识等。推荐想要搭建一个私有Docker镜像库的同学阅读。
《使用Docker镜像构建RPM包》:RPM是用于 Linux 分发版的最常见的软件包管理器。因为它允许分发已编译的软件,所以用户只用一个命令就可以安装软件。而RPM包的构建相当繁琐,并且对环境的要求比较高,本文作者介绍了如何借助Docker来构建可以适用多个平台的RPM包。
《CoreOS实践指南(四):集群的指挥所Fleet》:CoreOS 采用了高度精简的系统内核及外围定制,将许多原本需要复杂人工操作或者第三方软件支持的功能在操作系统级别进行了实现,同时剔除了其他对于服务器系统非核心的软件,比如GUI和包管理器。本文为基础第四篇:集群的指挥所Fleet,CoreOS中的Fleet服务通过Etcd获得集群的服务信息并通过DBus接口操作Systemd控制集群中任意节点的服务状态。
《从容器和Kubernetes技术看现代云计算的发展轨迹》:本文通过对容器技术和kubernetes的大致介绍,阐述了容器技术的优势以及Google对于容器技术的理解。基于单台服务器的容器虚拟化技术可以为测试和部署提供方便,但是在生产环境中,客户往往面对的是整个集群的资源。作者认为容器技术仅仅是当前计算模型演变的一个开端,而Google将会在这场新的技术革命中扮演重要的角色。
开源项目
- Dockersh:一个将用户隔离到各自Docker容器的Shell工具,当用户调用它时,用户将获得一个Docker容器,然后在容器名字空间里产生一个新的交互shell。
- Butterfly:一个基于Websocket和tornado的Web终端,非常漂亮,推荐。虽然与Docker无关,但是是在看Docker的一篇文章中看到的。
- Dokku:Dokku是一个迷你版的Heroku,基于Docker使用100行左右的Bash代码编写,简单的安装和配置后,即可使用Git命令将应用部署到本地的Dokku平台(当使用git push命令的时候,Dokku会使用buildpack检测应用,然后再部署)。
另外,为了更好的促进Docker在国内的发展以及传播,InfoQ开设了《深入浅出Docker》专栏,邀请Docker相关的布道师、开发人员、技术专家来讲述Docker的各方面内容。InfoQ希望Docker专栏能帮助读者迅速了解Docker,希望新的技术、新的理念能让更多的人受益。
Ernest likes this
16 Jan 10:59
Lua 5.3正式版发布,支持整数、位操作和UTF-8
by 李士窑
Lua是一个基于MIT开源协议、小巧、动态类型的可嵌入式脚本语言,该语言的设计目的是为了嵌入其他应用程序中并提供灵活的扩展和定制功能。在经过4个RC版本后,Lua终于迎来了5.3正式版,该版本主要实现了对整数、位操作、UTF-8 的支持以及打包和解包的功能。另外,Lua 5.3还在语言、功能库、C语言相关API等方面带来了如下改进:
1、 语言方面
Lua的基本类型userdata能够被赋予任何Lua支持的值;新增整数除法;为一些元方法新增了更加灵活的规则。
2、 功能库方面
改进了迭代器ipairs和table库对元方法的支持;为string.dump增加了截断选项;为table库新增了元方法;新增table.move、string.pack、string.unpack、string.packsize等函数。
3、 C语言相关API方面
增加了访问C语言中的continuation函数的API;lua_gettable 和类型函数能够返回结果值的类型;为lua_dump增加了截断选项;新增了lua_geti、lua_seti、lua_isyieldable、lua_numbertointeger、lua_rotate、lua_stringtonumber等函数。
4、 独立解释器方面
Lua的解释器可以用作计算器,且无需前缀‘=’;所有的代码都已支持参数列表。
Lua 5.3正式版现已提供下载,更多有关该版本的信息参见官方发布的ChangeLog。另外,Lua最著名的案例是暴雪公司在其网络游戏《魔兽世界》中的应用,目前非常流行的手游《愤怒的小鸟》也是用Lua编写的。
Lua 5.3正式版发布后,Hacker News上就有了相关讨论。用户sitkack提出了Lua的两个第三方UTF-8 lib库:luautf8和utf8.lua;用户justincormack认为Lua对整数的支持是一个巨大的改进。
这真是一个好消息,自己一直期待着将Lua应用到移动平台MOAI的最新客户端中,但是Lua对UTF-8支持的缺失一直影响着项目的进展,Lua 5.3对UTF-8的支持意味着其功能更加强大和完整。
Lua 5.3实现对整数、UTF-8和位操作的支持是一个巨大的改进。
用户feydius评论到:
真是太好了,Lua 5.3对64位整数的默认支持和对位操作的支持(5.3前是通过分割函数来实现)真是一个巨大的改进。垃圾收集器的进展现在是什么情况了?是否已经能够使用了。
感谢郭蕾对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ)或者腾讯微博(@InfoQ)关注我们,并与我们的编辑和其他读者朋友交流。
Ernest likes this
16 Jan 00:43
Java为什么会引入及如何使用Unsafe
by 范 忠瑞
综述
sun.misc.Unsafe至少从2004年Java1.4开始就存在于Java中了。在Java9中,为了提高JVM的可维护性,Unsafe和许多其他的东西一起都被作为内部使用类隐藏起来了。但是究竟是什么取代Unsafe不得而知,个人推测会有不止一样来取代它,那么问题来了,到底为什么要使用Unsafe?
做一些Java语言不允许但是又十分有用的事情
很多低级语言中可用的技巧在Java中都是不被允许的。对大多数开发者而言这是件好事,既可以拯救你,也可以拯救你的同事们。同样也使得导入开源代码更容易了,因为你能掌握它们可以造成的最大的灾难上限。或者至少明确你可以不小心失误的界限。如果你尝试地足够努力,你也能造成损害。
那你可能会奇怪,为什么还要去尝试呢?当建立库时,Unsafe中很多(但不是所有)方法都很有用,且有些情况下,除了使用JNI,没有其他方法做同样的事情,即使它可能会更加危险同时也会失去Java的“一次编译,永久运行”的跨平台特性。
对象的反序列化
当使用框架反序列化或者构建对象时,会假设从已存在的对象中重建,你期望使用反射来调用类的设置函数,或者更准确一点是能直接设置内部字段甚至是final字段的函数。问题是你想创建一个对象的实例,但你实际上又不需要构造函数,因为它可能会使问题更加困难而且会有副作用。
public class A implements Serializable {
private final int num;
public A(int num) {
System.out.println("Hello Mum");
this.num = num;
}
public int getNum() {
return num;
}
}
在这个类中,应该能够重建和设置final字段,但如果你不得不调用构造函数时,它就可能做一些和反序列化无关的事情。有了这些原因,很多库使用Unsafe创建实例而不是调用构造函数。
Unsafe unsafe = getUnsafe(); Class aClass = A.class; A a = (A) unsafe.allocateInstance(aClass);
调用allocateInstance函数避免了在我们不需要构造函数的时候却调用它。
线程安全的直接获取内存
Unsafe的另外一个用途是线程安全的获取非堆内存。ByteBuffer函数也能使你安全的获取非堆内存或是DirectMemory,但它不会提供任何线程安全的操作。你在进程间共享数据时使用Unsafe尤其有用。
import sun.misc.Unsafe;
import sun.nio.ch.DirectBuffer;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.lang.reflect.Field;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class PingPongMapMain {
public static void main(String... args) throws IOException {
boolean odd;
switch (args.length < 1 ? "usage" : args[0].toLowerCase()) {
case "odd":
odd = true;
break;
case "even":
odd = false;
break;
default:
System.err.println("Usage: java PingPongMain [odd|even]");
return;
}
int runs = 10000000;
long start = 0;
System.out.println("Waiting for the other odd/even");
File counters = new File(System.getProperty("java.io.tmpdir"), "counters.deleteme");
counters.deleteOnExit();
try (FileChannel fc = new RandomAccessFile(counters, "rw").getChannel()) {
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
long address = ((DirectBuffer) mbb).address();
for (int i = -1; i < runs; i++) {
for (; ; ) {
long value = UNSAFE.getLongVolatile(null, address);
boolean isOdd = (value & 1) != 0;
if (isOdd != odd)
// wait for the other side.
continue;
// make the change atomic, just in case there is more than one odd/even process
if (UNSAFE.compareAndSwapLong(null, address, value, value + 1))
break;
}
if (i == 0) {
System.out.println("Started");
start = System.nanoTime();
}
}
}
System.out.printf("... Finished, average ping/pong took %,d ns%n",
(System.nanoTime() - start) / runs);
}
static final Unsafe UNSAFE;
static {
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
} catch (Exception e) {
throw new AssertionError(e);
}
}
}
当你分别在两个程序,一个输入odd一个输入even,中运行时,可以看到两个进程都是通过持久化共享内存交换数据的。
在每个程序中,将相同的磁盘缓存映射到进程中。内存中实际上只有一份文件的副本存在。这意味着内存可以共享,前提是你使用线程安全的操作,比如volatile变量和CAS操作。(译注:CAS Compare and Swap 无锁算法)
在两个进程之间有83ns的往返时间。当考虑到System V IPC(进程间通信)大约需要2500ns,而且用IPC volatile替代persisted内存,算是相当快的了。
Unsafe适合在工作中使用吗?
个人不建议直接使用Unsafe。它远比原生的Java开发所需要的测试多。基于这个原因建议还是使用经过测试的库。如果你只是想自己用Unsafe,建议你最好在一个独立的类库中进行全面的测试。这限制了Unsafe在你的应用程序中的使用方式,但会给你一个更安全的Unsafe。
总结
Unsafe在Java中是很有趣的一个存在,你可以一个人在家里随便玩玩。它也有一些工作的应用程序特别是在写底层库的时候,但总的来说,使用经过测试的Unsafe库比直接用要好。
相关文章
Ernest likes this
15 Jan 09:26
伪随机的上位和真随机的逆袭
by zzr0427
(伯乐在线已征得转载许可,如需再次转载,必须经过作者同意。)
生活中到处都充满了“随机”的概念:抛硬币、抽签、彩票、游戏、歌曲随机播放等等,但事实上有许多所谓的“随机”只是“伪随机”,只是让人感觉起来像是随机。就像我们的眼睛很容易被视觉错觉欺骗,我们关于“随机”的直觉其实也挺不靠谱的。
- 一、游戏掉宝率和伪随机
- 二、iTunes的歌曲随机播放
- 三、抛硬币和教授的“读心术”
- 四、Benford法则和彩票(有致富信息哦~)
- 五、”Guardians of the Randomness”——“随机护卫队”
先来说说那些伪随机逼死真随机的故事吧,真是既悲伤又欢乐啊。
一、游戏掉宝率和伪随机:
几乎所有游戏都带有“随机性”,而游戏中最常见也最常被讨论的随机事件就是掉宝,也就是打完怪有一定几率爆出各种不同的宝物。而掉宝就是个很典型的随机事件,一般来说每个怪的掉宝率是固定的,比如一个怪有1/1000的几率掉A物品,1/100的几率掉B物品之类的。一般越稀有越值钱越有用的物品的爆率就越低。
虽说1/1000或1/100这样的爆率看似很简单,但实际上很多人是有认知盲区的。
大家可能都听到过有人这样抱怨:“妈的不是说1/100的掉宝率么,老子都刷了300次了还没掉,骗人的吧!我听说有人总共只打了两次就掉了两次,尼玛不科学啊!” 其实这太科学了。
一些人以为“百分之一的爆率”就意味着我打一百次就差不多该有一次能成功。但其实,打100次爆率为1/100的怪能够至少掉一次宝的概率只有1-(1-0.01)^100=0.634,也就是说36.6%的玩家打100次也没能掉一次。事实上,13.4%的玩家就算打满200次也没结果,4.9%的玩家打满了300次还是悲剧。
而另一方面,玩家们又经常会听说有某个人总共只打了两次,结果两次都掉。这概率有多少呢?如果从个体玩家角度看,这样的概率是1/10000,确实挺小的。但问题是我们“听说”这样的事件发生的概率是针对一个人群而言的,而不是个体。假设你在游戏里认识50个其他玩家朋友,而这50个玩家又各自认识50个玩家朋友,那么你所认识的朋友和朋友的朋友就有2500(假设你50个朋友的圈子没有重叠),而这2500人就构成了你最基本的小道消息网络。那么在你的朋友和朋友的朋友中出现一个“打两次掉两次”的神人的概率是多少呢?是0.222,也就是有超过20%的概率你的一级和二级朋友圈会出现一个1/10000的小概率事件。
如果这个游戏总共有10万玩家,那么就有99.995%的概率会出现至少一个“打两次掉两次”,9.5%概率出现至少一个“打三次掉三次”,而同时,如果每个玩家都打满1000次,那仍然会有64.9%的概率出现一个就算打满1000次也还是悲剧的衰神。总之,一个对于个体的小概率事件在人群中出现的概率往往是很大的。比如知乎去年的世界杯竞猜,好像有人连续十几场猜中,然后大家纷纷膜拜“大神”。我不知道那位用户究竟是靠运气还是实力,但其实就算是一群猴子在猜,只要基数大到一定程度,也是很有可能会出现一个“神猴”的。
虽然这些事背后的原理其实还挺简单的,但偏偏很多玩家无法理解或懒得理解,于是游戏设计者们就整天被一群愤怒的、嫉妒的、坚信“游戏不公平、不科学”的玩家骚扰、差评、威胁。所以许多游戏的掉宝原理的设计到最后都被迫妥协,并不是真随机,而是某种伪随机,人为削弱某些小概率事件的可能,给玩家们营造一种“随机”的感觉。然后之前那些愤怒的玩家们纷纷表示:“这不就行了吗?这才叫真的随机好吧。设计这游戏的简直数死早,还要我们玩家来帮忙。”
伪随机逼死真随机,玩家逼死游戏设计,就是这个意思。
更多关于游戏中的伪随机,请看@曾于修 的为什么有人说《暗黑破坏神 3》中的随机是「伪随机」? – 曾于修的回答
二、iTunes的歌曲随机播放:
躺枪的不只是游戏,还有苹果。最开始iTunes上“随机播放下一首”的功能用的是真随机,随到哪一首就放哪一首呗。但这想法实在是太年轻了…
苹果很快就收到了大量的投诉,说“我明明用的是随机播放,怎么会连续播放两首一样的呢?!你这随机功能肯定是坏的!差评!” …“我放了4首歌,结果出现了两首歌交替出现,ABAB这样,非常有规律,苹果你耍我呢?!”
唉,真可谓“概率不学好,生活多烦恼”…跟上面游戏的例子相似,这类事件其实完全有可能,而且概率并不小。
如果歌曲列表里有20首歌,那么听完一首歌后马上又随机到同一首的概率其实就是1/20,也就是说你听2小时歌(假设每首平均5分钟),那么至少出现一次连续两首相同的概率是0.708,至少出现一次ABAB的概率是0.058,都还挺高的。这还只是听2小时而已,如果听2000小时,那么出现ABABAB的概率也高达0.139
听说苹果当时还专门发表了一个声明,解释出现这种现象的原因,表示这不是随机播放功能出了问题。但这想得实在太简单了…
最后苹果还是用了伪随机,禁止连续随机到同样的歌,甚至禁止出现一些诸如ABAB,ABCABC之类的常见序列。
不得不通过把“随机”变得不“随机”来让用户觉得这“随机”很“随机”。人脑的认知真是很呵呵啊…
三、抛硬币和教授的“读心术”:
听说有个概率论教授有一次把班上的学生分成两组,其中一组抛一个硬币100次,然后如实记录每一次的结果。另一组,教授不许抛硬币,而是让他们编出100个“尽可能随机”的抛硬币结果。实验过程中教授会走出教室,两组学生不能够互相交流。然后教授告诉大家,他到时只需要看到两组结果就能猜出哪一组结果来自真实的抛硬币,而哪一组是编出来的。学生自然不相信,不都是随机序列么,怎么可能看出区别?教授这是欺负我们智商?于是第二组的熊孩子就干劲十足地开始编,想把结果弄得看起来非常随机,从而混淆教授。下面是最后的两组结果,大家先猜猜哪一组是编的?(我这里直接借用了@chenqin 在数字被修改了吗? – Clean Data – 知乎专栏里的例子 )
序列1:
tthhhhhtthhhhtthhthhhtthhhhttththhhtthhhhhhtthhhhh htthhthhhthhhhthhththtttththtthhtthhhhhttthhththtt序列2:
hthtthhtthtthhhthtthtttththhthhththhhhthhtthtththh hthhhthtththhhthttththhthhhthththhhhthhthttththhth
教授一眼就看出了正确答案:第二组是编的,第一组是真实的。为什么呢?因为第一组出现了连续6个相同的结果,而第二组的看起来更“杂”更“乱”一些。第二组学生的直觉告诉他们,“随机就是乱、没规律”,于是他们肯定不敢编出有连续五个六个相同结果的序列,因为这看起来“太有规律”了,“不够随机”,“看着太假”。但事实上(根据@chenqin 的计算),抛100次硬币,至少出现一次连续6个相同结果的概率超过80%,至少出现一次连续5个相同结果的概率超过90%. 所以熊孩子们想把序列弄得“尽可能随机”的心理恰好中了教授的圈套,他们直觉上越“随机”的序列往往反而不是那么“随机”。于是教授成功带领真随机逆袭啦~
这其实跟之前的歌曲随机播放例子里的逻辑很像,只不过教授是反向利用了这种认知模式和错误直觉。抛6次硬币出现6次相同结果的概率很小,但抛100次出现这样情况的概率就很高了。
其实类似的错误直觉在各种牌类游戏和赌博中也很常见。许多大家平时总结出来的“规律”,一些牌桌上的顺口溜,都不一定准确。
还是拿抛硬币举个例子,比如你和小伙伴赌抛硬币,假设已知这个硬币是公平的。之前已经连续抛出10个正面,那么接下来一次还是正面的概率是多少?有些人会想“连续11个正面的概率也太小了吧,下一个总应该是反面了吧?”这种思维模式确实有迷惑性,但只要硬币是公平的,只要每次抛硬币是独立事件,那么不管之前出现了多少次连续正面,下一次还是正面的概率还是50%. 这种心理很容易在赌徒身上出现:我今晚连输30把了,一晚上全输的概率也太小了吧,我接下来肯定要开始赢了!…
相关的讨论有很多,比如在抛了100次硬币以后连续出现100次正面,那抛101次是不是反面概率更大? – 数学题
更多关于牌桌上的错觉,请看@段昊 的打麻将的时候,为什么会有连续一段时间运气特别好的现象? – 段昊的回答
四、Benford法则和彩票:
我要是说“买彩票是有技巧的”,大家肯定会说我民科。不过用真随机数买彩票,虽然不能帮你提高彩票中奖的概率,但也许能帮你提高中奖的奖金数额。听我慢慢解释:
彩票的中奖概率是无法通过“技巧”或“研究”改变的,这点很多人都解释过了:彩票有规律可循吗? – 概率
但是大多数人都忽略了彩票中奖金额这一维度。对于许多彩票,中同一个号码的人越多,分奖金的人也越多,而每个人分到的奖金也就越少。另一方面,虽然中奖号码的产生本身是真随机,但人们买的号码往往不是随机的。如果把所有人买的号码放在一起做统计,那么0-9这些数字出现的频率会有很大的差异,有些数字被买的次数会明显高于其他一些数字。也就是说,当那些出现频率较高的数字真的出现在中奖号码中时,中奖人数就会比较多,每个人分到的金额就少。这主要有两方面原因。
首先,人们对数字有各种迷信,一般中国人会更喜欢6和8这些数字,而避开4,如果在一些西方国家,人们喜欢7,忌讳13。而买彩票时一些人也会想要一些带6和8的号码来“讨彩头”,但结果这些“幸运号码”反而让他们的收益期望值降低。这就跟出生年份的分布有点相似。大家应该都听说过龙年虎年出生的小孩特别多,而什么鸡年狗年出生的孩子相对少一些。“龙宝宝”、“虎宝宝”听着吉利,但等到小孩要升学、高考、考研、就业时面临的竞争对手也就多了,到这时候不管是再好听的“龙”还是“虎”都没半点用了。
其次,许多人都会用一些“有意义”的数字买彩票,而最常见的就是日期,比如生日、纪念日等等。而这些日期中包含的数字是绝对不随机的,而且是高度可预测的。这里就要提到Benford法则了。Benford法则粗糙地说就是,在现实中的10进制数据中,以1为首位数字的数的出现频率最高,9最低,中间的数字依次递减。而且这种差异非常明显:

我自己对日期中出现的数字频率进行了统计。严格来说不是Benford法则,但原理应该很相似。在01.02,12.25 这样形式的日期中:

其中0,1,2三个数字竟然占到了66.9%,也就是如果大家都用日期买彩票,那么0,1,2三个数字被买的次数会超过剩下的7个数字总和的两倍还多。这种不随机的程度还真是挺夸张的。
所以,我猜在中国人买的彩票里,0,1,2出现次数最多,3,6,8其次,而4有可能是最少的。所以如果想要避开其他彩民的竞争,应该尽量避免0,1,2之类的数字,然后产生真随机数,这样也许可以最大化收益。于是,真随机似乎又逆袭咯~
这里有三个声明:
1. 以上只能算是一点理论,还需要真实数据验证,所以买彩票亏了别找我哦…
2. 当然按我的方法买彩票赚了的话可要千万记得我哦~
3. 其实就算用这种方法,买任何彩票的期望收益率仍然是负的,所以大家随便玩玩就好。
更多关于Benford法则的介绍请看@chenqin 的数字被修改了吗? – Clean Data – 知乎专栏
五、”Guardians of the Randomness”——“随机护卫队”:
The generation of random numbers is too important to be left to chance.
Random numbers should not be generated with a method chosen at random.
就像“银河护卫队”一样,这是一群有点逗逼又有点牛逼的人,他们默默地守卫着:嗯,“随机”。小标题里的名字是我给他们取的,他们的真名叫http://RANDOM.ORG,也就是他们的网址。这其实是一个很正规的组织,是由爱尔兰都柏林三一学院计算机科学和统计学院的Mads Haahr博士于1988年创建的,现在已经升级为有限公司了,曾被各大媒体报道过,甚至还被十几篇顶级期刊发表的论文引用过,至今它累计已经提供了超过19万亿次随机生成相关服务了。
http://RANDOM.ORG旨在提供最优质最科学最随机的随机数生成及衍生服务。他们提供的免费服务包括:随机数、数组、字符、序列生成,随机正态分布生成,机选彩票,抛硬币,掷色子,洗牌器,随机打乱顺序,随机生成时间、日期、密码、地理坐标、DNA序列、纯净白噪音等等,从娱乐到学术都有。当然他们还有付费服务:第三方认证的抽签,为非常重要的抽签提供最高纯度的随机性。
很多人会问:生成个随机数还有好坏优劣之分?严格来讲的确有。
我们的各种电子设备需要生成许多随机数,但绝大多数的这些随机数生成都是“伪随机数生成”(PRNG),而http://RANDOM.ORG是世界上少数几个提供“真随机数生成”(TRNG)的机构。“伪随机数生成”是运用一套算法,将一个初始数值/序列等转化为看似非常随机没有规则的结果。对于99.9%的应用而言,这些“伪随机数”其实也完全没问题,但对于一些科学研究、一些专业博彩机构、一些涉及加密和信息安全的应用,“伪随机数”从理论上讲是决定性的,可预测的,周期性的,这也就会带来各种隐患,因为如果知道了初始值,知道了具体算法,就有理论上的可能还原出完全一样的“随机数”。而各类“真随机数生成”一般会使用一些无法预测和控制的自然现象来生成随机数:元素的某些随机衰变现象、环境噪音等。这些方法背后的理论基础就跟量子理论和混沌理论有关了。http://RANDOM.ORG使用的就是环境噪音。当然,“真随机数生成”的效率是远低于“伪随机数生成”的,这也是为什么http://RANDOM.ORG对每个IP每天免费生成的随机数是有限制的,大约是122kb左右。
http://RANDOM.ORG甚至还有针对黑客和恐怖袭击的应对措施…他们的设备分布在多个大洲的多个国家的隐秘地点,所以黑客或恐怖分子必须在所有地点同时用特殊仪器发起攻击才行。但即使是这样,http://RANDOM.ORG还有对应的内部监测和防御机制,简直酷炫,对得起“随机护卫队”的称号。不过不知为啥读到他们这段说明时总有种浓浓的中二感……
关于“真随机数”的科普和“真随机数”的重要性,请看RANDOM.ORG – Introduction to Randomness and Random Numbers 和 RANDOM.ORG – Statistical Analysis
大家还可以在这里看看各个领域的用户们是如何创造性地使用http://RANDOM.ORG的:RANDOM.ORG – Testimonials,除了之前提到的比较正经的,还有用来艺术创作的,用来制作白噪音提高睡眠质量的,用来提升夫妻生活质量的,用来拯救选择障碍症晚期患者的,还有跟中国的《易经》一起用来算命的…总之深受又认真又geeky的神经病的欢迎。
我最初知道这个网站是通过我们系管电脑的大叔。他这人完全就是个活生生的computer geek的刻板印象。有一次我们系开会讨论个事,中途需要决定一个日期/数字(记不清了,反正不重要),于是大家说:那我们就随机选一个吧。听到“随机”这个词,本来在思考人生的大叔突然被激活了,特别严肃地对大家说:“等等”。我们还以为他要发表什么重要观点,结果只见他打开电脑,登上http://random.org,生成了一个符合要求的随机结果,然后在全场的注目礼中继续思考人生,like a boss……从此大家在他面前不太敢用“随机”这个词了…
总之,http://RANDOM.ORG是一群认真、执着、洁癖但又有些可爱的人二十多年来共同努力的结果。希望大家优雅地使用。
我们生活中充满了跟“随机”相关的事物。有时伪随机逼死真随机,有时真随机又能逆袭,有时伪随机更实用,有时真随机能致富。这事儿还真是“随机”呢~
————————————————————————————————————
大家有兴趣还可以看一下@舒乐乐 这个回答:为什么所谓 50 年一遇、百年一遇的自然灾害几乎年年发生? – 舒乐乐的回答,跟我的文章的第一第二部分也有些关系。本来我也想写的,但刚好看到了这篇,觉得写得蛮好的~
我偶尔还会继续写一些跟概率、统计有关的科普猎奇小文章,下一篇应该叫《廉价的巧合》。有兴趣的话可以关注一下专栏~
Ernest likes this
15 Jan 09:23
如何在指针中隐藏数据?
by ashiontang
编写 C 语言代码时,指针无处不在。我们可以稍微额外利用指针,在它们内部暗中存储一些额外信息。为实现这一技巧,我们利用了数据在内存中的自然对齐特性。
内存中的数据并非保存在任意地址。处理器通常按照其字大小相同的块读取内存数据;那么考虑到效率因素,编译器会按照块大小的整数倍对内存中的实体进行地址对齐。因此在32位的处理器上,一个4字节整型数据肯定存放在内存地址能被4整除的地方。
下面,假设系统中整型数据和指针大小均为 4 字节。
现在有一个指向整型的指针。如上所述,整型数据可以存放在内存地址0×1000或者0×1004或者0×1008,但是决不会存放在0×1001或者0×1002或者0×1003或者其他不能被4整除的任何地址。所有是4整数倍的二进制数都是以00结尾。实际上,这意味着对于所有指向整型的指针,它的最后两位总是0。
那么有2比特没有承载任何信息。此处的技巧是将我们的数据放置到这两个比特中,在需要时使用,并在通过指针解引用来访问内存前删除它们。
由于C标准对指针位操作的支持不是很好,所以我们将指针保存为一个无符号整型数据。
下面是一段简短的简单代码片段。完整的代码查看github代码仓库中的 hide-data-in-ptr。
void put_data(int *p, unsigned int data)
{
assert(data < 4);
*p |= data;
}
unsigned int get_data(unsigned int p)
{
return (p & 3);
}
void cleanse_pointer(int *p)
{
*p &= ~3;
}
int main(void)
{
unsigned int x = 701;
unsigned int p = (unsigned int) &x;
printf("Original ptr: %un", p);
put_data(&p, 3);
printf("ptr with data: %un", p);
printf("data stored in ptr: %un", get_data(p));
cleanse_pointer(&p);
printf("Cleansed ptr: %un", p);
printf("Dereferencing cleansed ptr: %un", *(int*)p);
return 0;
}
代码输出如下:
Original ptr: 3216722220 ptr with data: 3216722223 data stored in ptr: 3 Cleansed ptr: 3216722220 Dereferencing cleansed ptr: 701
我们可以在指针中存储任何可以用两个比特位表示的数据。使用put_data()函数,设置指针的最低两位为要存储的数据。该数据可以使用get_data()函数获取。此处除了最后两位所有的位都被覆盖为零,于是我们隐藏的数据就显示出来。
cleanse_pointer()函数将最低两位置零,保证指针安全地解引用。注意虽然有些CPU像Intel允许我们访问未对齐内存地址,但其余CPU像ARM会出现访问错误。所以,要牢记在解引用前保证指针指向已对齐内存地址。
这在实际中有应用吗?
是的,有应用。查看Linux内核中红黑树的实现(链接)。
树的结点定义如下:
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
此处unsigned long __rb_parent_color存储了如下信息:
- 父节点的地址
- 结点的颜色
色彩的表示用0代表红色,1代表黑色。
和前面的例子一样,该数据隐藏在父指针“无用的”比特位中。
下面看一下父指针和色彩信息是如何获取的:
/* in rbtree.h */ #define rb_parent(r) ((struct rb_node *)((r)->__rb_parent_color & ~3))
/* in rbtree_augmented.h */ #define __rb_color(pc) ((pc) & 1) #define rb_color(rb) __rb_color((rb)->__rb_parent_color)
内存中每一比特都很珍贵,砸门永远不要浪费。——(本文作者)
如何在指针中隐藏数据?,首发于博客 - 伯乐在线。
Ernest likes this
15 Jan 06:37
也许是有史以来最好的游戏:NetHack
by scsecrystal
这款游戏非常容易让你上瘾。你可能需要花费一生的时间来掌握它。许多人玩了几十年也没有通关。欢迎来到 NetHack 的世界…
不管你信不信,在 NetHack 里你见到字母 D 的时候你会被吓着。但是当你看见一个 % 的时候,你将会欣喜若狂。(忘了说 ^,你看见它将会更激动)在你寻思我们的脑子是不是烧坏了并准备关闭浏览器标签之前,请给我们一点时间解释:这些符号分别代表龙、食物以及陷阱。欢迎来到 NetHack 的世界,在这里你的想象力需要发挥巨大的作用。
如你所见,NetHack 是一款文字模式的游戏:它仅仅使用标准终端字符集来刻画玩家、敌人、物品还有环境。游戏的图形版是存在的,不过 NetHack 的骨灰级玩家们都倾向于不去使用它们,问题在于假如你使用图形界面,当你通过 SSH 登录到你的古董级的运行着 NetBSD 的 Amiga 3000 上时,你还能进行游戏吗?在某些方面,NetHack 和 Vi 非常相似 – 几乎被移植到了现存的所有的操作系统上,并且依赖都非常少。
那么问题来了,和现代游戏相比如此简陋的画面,是什么造就了 NetHack 如此巨大的吸引力的呢? 事实上,这款地牢探险类神作有着令人难以置信的丰富细节。有太多的东西等着你去发掘:法术释放、怪物战斗以及技巧学习 – 以及随机生成的地牢。有太多的东西等着你去探索,几乎没有哪两局游戏会是完全一样的。许多人玩了几十年也没有通关,每次游戏依然能发现一些以前不知道的秘密。
接下来,我们会向你讲述 NetHack 的历史,给你地牢探险的基本指导,再告诉你一些技巧。免责: 在你继续阅读本文之前,视为你已经自动同意了当你沉溺于 NetHack 以致影响到你的现实生活时,你不会起诉我们。

NetHack 界面
也许是最古老的仍在开发的游戏里
名非其实,NetHack 并不是一款网络游戏。它只不过是基于一款出现较早的名为 Hack 的地牢探险类游戏开发出来的,而这款 Hack 游戏是 1980 年的游戏 Rogue 的后代。NetHack 在 1987 年发布了第一个版本,并于 2003 年发布了 3.4.3 版本,尽管在这期间一直没有加入新的功能,但各种补丁、插件,以及衍生作品还是在网络上疯狂流传。这使得它可以说是最古老的、拥有众多对游戏乐此不疲的粉丝的游戏。当你访问 www.reddit.com/r/nethack 之后,你就会了解我们的意思了 – 骨灰级的 NetHack 的玩家们仍然聚集在一起讨论新的策略、发现和技巧。偶尔你也可以发现 NetHack 的元老级玩家在历经千辛万苦终于通关之后发出的欢呼。
但怎样才能通关呢?首先,NetHack 被设定在既大又深的地牢中。游戏开始时你在最顶层 – 第 1 层 – 你的目标是不断往下深入直到你找到一个非常宝贵的物品,护身符 Yendor。通常来说 Yendor 在 第 20 层或者更深的地方,但它是可以变化的。随着你在地牢的不断深入,你会遇到各种各样的怪物、陷阱以及 NPC;有些会试图杀掉你,有些会挡在你前进的路上,还有些… 总而言之,在你靠近 TA 们之前你永远不知道 TA 们会怎样。
要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。
使 NetHack 如此引人入胜的原因是游戏中所加入的大量物品。武器、盔甲、附魔书、戒指、宝石 – 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。怪物在死亡后经常会掉落一些有用的物品,以及某些物品如果你不正确使用的话会产生及其不良的作用。你可以在地牢找到商店,里面有许多看似平凡实则非常有用的物品,不过别指望店主能给你详细的描述。你只能靠自己的经验来了解各个物品的用途。有些物品确实没有太大用处,NetHack 中有很多的恶搞元素 – 比如你可以把一块奶油砸到自己的脸上。
不过在你踏入地牢之前,NetHack 会询问你要选择哪种角色进行游戏。你可以为你接下来的地牢之行选择骑士、修道士、巫师,或者卑微的旅者,还有许多其他的角色类型。每种角色都有其独特的优势与弱点,NetHack 的重度玩家喜欢选择那些相对较弱的角色来挑战游戏。你懂的,这样可以向其他玩家炫耀自己的实力。
情报不会降低游戏的乐趣
用 NetHack 的说法来讲,“情报员”给指其他玩家提供关于怪物、物品、武器和盔甲信息的玩家。理论上来说,完全可以不借助任何外来信息而通关,但几乎没有几个玩家能做到,游戏实在是太难了。因此使用情报并不会被视为一件糟糕的事情 – 但是一开始由你自己来探索游戏和解决难题,这样才会获得更多的乐趣,只有当你遇到瓶颈的时候再去使用那些情报。
在这里给出一个比较有名的情报站点 www.statslab.cam.ac.uk/~eva/nethack/spoilerlist.html,其中的情报被分为了不同的类别。游戏中随机发生的事,比如在喷泉旁饮水可能导致的不同结果,从这里你可以得知已确定的不同结果的发生概率。
你的首次地牢之行
NetHack 几乎可以在所有的主流操作系统以及 Linux 发行版上运行,因此你可以通过 “apt-get install nethack” 或者 “yum install nethack” 等适合你用的发行版的命令来安装游戏。安装完毕后,在一个命令行窗口中键入 “nethack” 就可以开始游戏了。游戏开始时系统会询问是否为你随机挑选一位角色 – 但作为一个新手,你最好自己从里面挑选一位比较强的角色。所以,你应该点 “n”,然后点 “v” 以选取女武神(Valkyrie),而点 “d” 会选择成为侏儒(dwarf)。
接着 NetHack 上会显示出剧情,说你的神正在寻找护身符 Yendor,你的目标就是找到它并将它带给神。阅读完毕后点击空格键(其他任何时候当你见到屏幕上的 “-More-” 时都可以这样)。接着就让我们出发 – 开始地牢之行吧!
先前已经介绍过了,你的角色用 @ 来表示。你可以看见角色所出房间周围的墙壁,房间里显示“点”的那些地方是你可以移动的空间。首先,你得明白怎样移动角色:h、j、k 以及 l。(是的,和 Vim 中移动光标的操作相同)这些操作分别会使角色向向左、向下、向上以及向右移动。你也可以通过 y、u、b 和 n 来使角色斜向移动。在你熟悉如何控制角色移动前你最好在房间里来回移动你的角色。
NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然在进行。这是你可以提前计划你的行动。你可以看见一个 “d” 字符或者 “f” 字符在房间里来回移动:这是你的宠物狗/猫,(通常情况下)它们不会伤害你而是帮助你击杀怪物。但是宠物也会被惹怒 – 它们偶尔也会抢在你接近食物或者怪物尸体之前吃掉它们。

点击 “i” 列出你当前携带的物品清单
门后有什么?
接下来,让我们离开房间。房间四周的墙壁某处会有缝隙,可能是 “+” 号。”+” 号表示一扇关闭的门,这时你应该靠近它然后点击 “o” 来开门。接着系统会询问你开门的方向,假如门在你的左方,就点击 “h”。(如果门被卡住了,就多试几次)然后你就可以看见门后的走廊了,它们由 “#” 号表示,沿着走廊前进直到你找到另一个房间。
地牢之行中你会见到各种各样的物品。某些物品,比如金币(由 “$” 号表示)会被自动捡起来;至于另一些物品,你只能站在上面按下逗号键手动拾起。如果同一位置有多个物品,系统会给你显示一个列表,你只要通过合适的按键选择列表中你想要的物品最后按下 “Enter” 键即可。任何时间你都可以点击 “i” 键在屏幕上列出你当前携带的物品清单。
如果看见了怪物该怎么办?在游戏早期,你可能会遇到的怪物会用符号 “d”、”x” 和 “:” 表示。想要攻击的话,只要简单地朝怪物的方向移动即可。系统会在屏幕顶部通过信息显示来告诉你攻击是否成功 – 以及怪物做出了何种反应。早期的怪物很容易击杀,所以你可以毫不费力地打败他们,但请留意底部状态栏里显示的角色的 HP 值。
早期的怪物很容易击杀,但请留意角色的 HP 值。
如果怪物死后掉落了一具尸体(”%”),你可以点击逗号进行拾取,并点击 “e” 来食用。(在任何时候系统提示你选择一件物品,你都可以从物品列表中点击相应的按键,或者点击 “?” 来查询迷你菜单。)注意!有些尸体是有毒的,这些知识你将在日后的冒险中逐渐学会掌握。
如果你在走廊里行进时遇到了死胡同,你可以点击 “s” 进行搜寻直到找到一扇门。这会花费时间,但是你可以这样加速游戏进程:输入 “10″ 并点击 “s” 你将一下搜索 10 次。这将花费游戏中进行 10 次动作的时间,不过如果你正在饥饿状态,你将有可能会被饿死!
通常你可以在地牢顶部找到 “{“(喷泉)以及 “!”(药水)。当你找到喷泉的时候,你可以站在上面并点击 “q” 键开始 “畅饮(quaff)” – 引用后会得到从振奋的到致命的多种效果。当你找到药水的时候,将其拾起并点击 “q” 来饮用。如果你找到一个商店,你可以拾取其中的物品并在离开前点击 “p” 键进行支付。当你负重过大时,你可以点击 “d” 键丢掉一些东西。

现在已经有带音效的 3D 版 Nethack 了,如:Falcon’s Eye
愚蠢的死法
在 NetHack 玩家中流行着一个缩写词 “YASD” – 又一种愚蠢的死法(Yet Another Stupid Death)。这个缩写词表示了玩家由于自身的的愚蠢或者粗心大意导致了角色的死亡。我们搜集了很多这类死法,但我们最喜欢的是下面这种死法:
我们正在商店浏览商品,这时一条蛇突然从药剂后面跳了出来。在杀死蛇之后,系统弹出一条信息提醒我们角色饥饿值过低了,因此我们顺手食用了蛇的尸体。坏事了!这使得我们的角色失明,导致我们的角色再也不能看见商店里的其他角色及地上的商品了。我们试图离开商店,但在慌乱中却撞在了店主身上并攻击了他。这种做法激怒了店主:他立即向我们的角色使用了火球术。我们试图逃到商店外的走廊上,但却在逃亡的过程中被烧死。
如果你有类似的死法,一定要来我们的论坛告诉我们。不要担心 – 没有人会嘲笑你。经历这样的死法也是你在 NetHack 的世界里不断成长的一部分。哈哈。
武装自己
地牢里,尤其是在你击杀怪物后,你可能会发现武器或盔甲。在这里再说一次,点击逗号把它们拾起,接着点击 “w”(小写的)来使用武器或者点击 “W”(大写的)来穿上盔甲。你可以用 “T” 来脱掉盔甲或者 “t” 来取下武器 – 如果你陷入了困境,请确保你总是在使用最好的装备。
在靠近掉在地下的装备之前最好检查一下身上的东西。点击 “;”(分号)后,”Pick an object”(选择一样物品)选项将出现在屏幕顶部。选择该选项,使用移动键直到选中你想要检查的物品,然后点击 “:”(冒号)。接着屏幕顶部将出现这件物品的描述。
因为你的目标是不断深入地牢直到找到护身符 Yendor,所以请随时留意周围的 “<” 和 “>” 符号。这两个符号分别表示向上和向下的楼梯,你可以用与之对应的按键来上楼或下楼。注意!如果你想让宠物跟随你进入下/上一层地牢,下/上楼前请确保你的宠物在你邻近的方格内。若果你想退出,点击 “S”(大写的)来保存进度,输入 #quit 退出游戏。当你再次运行 NetHack 时,系统将会自动读取你上次退出时的游戏进度。
我们就不继续剧透了,地牢深处还有更多的神秘细节、陌生的 NPC 以及不为人知的秘密等着你去发掘。那么,我们再给你点建议:当你遇到了让你困惑不已的物品时,你可以尝试去 NetHack 维基 http://nethack.wikia.com 进行搜索。你也可以在www.nethack.org/v343/Guidebook.html 找到一本非常不错(尽管很长)的指导手册。最后,祝游戏愉快!
Ernest likes this
13 Jan 00:30
Java注解教程:自定义注解示例,利用反射进行解析
by Justin Wu
Java注解能够提供代码的相关信息,同时对于所注解的代码结构又没有直接影响。在这篇教程中,我们将学习Java注解,如何编写自定义注解,注解的使用,以及如何使用反射解析注解。
注解是Java 1.5引入的,目前已被广泛应用于各种Java框架,如Hibernate,Jersey,Spring。注解相当于是一种嵌入在程序中的元数据,可以使用注解解析工具或编译器对其进行解析,也可以指定注解在编译期或运行期有效。
在注解诞生之前,程序的元数据存在的形式仅限于java注释或javadoc,但注解可以提供更多功能,它不仅包含元数据,还能作用于运行期,注解解析器能够使用注解决定处理流程。举个例子,在Jersey webservice中,我们在一个方法上添加了PATH注解和URI字符串,在运行期,jersey会对其进行解析,并决定作用于指定URI模式的方法。
在Java中创建自定义注解
创建自定义注解与编写接口很相似,除了它的接口关键字前有个@符号。我们可以在注解中定义方法,先来看个例子,之后我们会继续讨论它的特性。
package com.journaldev.annotations;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Documented
@Target(ElementType.METHOD)
@Inherited
@Retention(RetentionPolicy.RUNTIME)
public @interface MethodInfo{
String author() default "Pankaj";
String date();
int revision() default 1;
String comments();
}
- 注解方法不能有参数。
- 注解方法的返回类型局限于原始类型,字符串,枚举,注解,或以上类型构成的数组。
- 注解方法可以包含默认值。
- 注解可以包含与其绑定的元注解,元注解为注解提供信息,有四种元注解类型:
1. @Documented – 表示使用该注解的元素应被javadoc或类似工具文档化,它应用于类型声明,类型声明的注解会影响客户端对注解元素的使用。如果一个类型声明添加了Documented注解,那么它的注解会成为被注解元素的公共API的一部分。
2. @Target – 表示支持注解的程序元素的种类,一些可能的值有TYPE, METHOD, CONSTRUCTOR, FIELD等等。如果Target元注解不存在,那么该注解就可以使用在任何程序元素之上。
3. @Inherited – 表示一个注解类型会被自动继承,如果用户在类声明的时候查询注解类型,同时类声明中也没有这个类型的注解,那么注解类型会自动查询该类的父类,这个过程将会不停地重复,直到该类型的注解被找到为止,或是到达类结构的顶层(Object)。
4. @Retention – 表示注解类型保留时间的长短,它接收RetentionPolicy参数,可能的值有SOURCE, CLASS, 以及RUNTIME。
Java内置注解
Java提供3种内置注解。
1. @Override – 当我们想要覆盖父类的一个方法时,需要使用该注解告知编译器我们正在覆盖一个方法。这样的话,当父类的方法被删除或修改了,编译器会提示错误信息。大家可以学习一下为什么我们总是应该在覆盖方法时使用Java覆盖注解。
2. @Deprecated – 当我们想要让编译器知道一个方法已经被弃用(deprecate)时,应该使用这个注解。Java推荐在javadoc中提供信息,告知用户为什么这个方法被弃用了,以及替代方法是什么。
3. @SuppressWarnings – 这个注解仅仅是告知编译器,忽略它们产生了特殊警告,比如:在java泛型中使用原始类型。它的保持性策略(retention policy)是SOURCE,在编译器中将被丢弃。
我们来看一个例子,展示了如何使用内置注解,以及上述示例中提及的自定义注解。
package com.journaldev.annotations;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.List;
public class AnnotationExample {
public static void main(String[] args) {
}
@Override
@MethodInfo(author = "Pankaj", comments = "Main method", date = "Nov 17 2012", revision = 1)
public String toString() {
return "Overriden toString method";
}
@Deprecated
@MethodInfo(comments = "deprecated method", date = "Nov 17 2012")
public static void oldMethod() {
System.out.println("old method, don't use it.");
}
@SuppressWarnings({ "unchecked", "deprecation" })
@MethodInfo(author = "Pankaj", comments = "Main method", date = "Nov 17 2012", revision = 10)
public static void genericsTest() throws FileNotFoundException {
List l = new ArrayList();
l.add("abc");
oldMethod();
}
}
我相信这个例子是很明了的,展示了不同场景下注解的使用方式。
Java注解解析
我们将使用Java反射机制从一个类中解析注解,请记住,注解保持性策略应该是RUNTIME,否则它的信息在运行期无效,我们也不能从中获取任何数据。
package com.journaldev.annotations;
import java.lang.annotation.Annotation;
import java.lang.reflect.Method;
public class AnnotationParsing {
public static void main(String[] args) {
try {
for (Method method : AnnotationParsing.class
.getClassLoader()
.loadClass(("com.journaldev.annotations.AnnotationExample"))
.getMethods()) {
// checks if MethodInfo annotation is present for the method
if (method
.isAnnotationPresent(com.journaldev.annotations.MethodInfo.class)) {
try {
// iterates all the annotations available in the method
for (Annotation anno : method.getDeclaredAnnotations()) {
System.out.println("Annotation in Method '"
+ method + "' : " + anno);
}
MethodInfo methodAnno = method
.getAnnotation(MethodInfo.class);
if (methodAnno.revision() == 1) {
System.out.println("Method with revision no 1 = "
+ method);
}
} catch (Throwable ex) {
ex.printStackTrace();
}
}
}
} catch (SecurityException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
以上程序的输出是:
Annotation in Method 'public java.lang.String com.journaldev.annotations.AnnotationExample.toString()' : @com.journaldev.annotations.MethodInfo(author=Pankaj, revision=1, comments=Main method, date=Nov 17 2012) Method with revision no 1 = public java.lang.String com.journaldev.annotations.AnnotationExample.toString() Annotation in Method 'public static void com.journaldev.annotations.AnnotationExample.oldMethod()' : @java.lang.Deprecated() Annotation in Method 'public static void com.journaldev.annotations.AnnotationExample.oldMethod()' : @com.journaldev.annotations.MethodInfo(author=Pankaj, revision=1, comments=deprecated method, date=Nov 17 2012) Method with revision no 1 = public static void com.journaldev.annotations.AnnotationExample.oldMethod() Annotation in Method 'public static void com.journaldev.annotations.AnnotationExample.genericsTest() throws java.io.FileNotFoundException' : @com.journaldev.annotations.MethodInfo(author=Pankaj, revision=10, comments=Main method, date=Nov 17 2012)
注解API非常强大,被广泛应用于各种Java框架,如Spring,Hibernate,JUnit。可以查看《Java中的反射》获得更多信息。
这就是java注解教程的全部内容了,我希望你能从中学到一些东西。
可能感兴趣的文章
Ernest likes this
12 Jan 06:28

Google 的 Gmail 可能是近幾年來大家使用率最高的郵件系統之一,當年很多人因為它強大的垃圾郵件過濾功能轉而使用,不過也因為一開始大家只看到郵件過濾,而可能忽略了活用 Gmail 可以使用的特殊方法與功能。
作為 Google 雲端工作平台的一員, Gmail 負擔的不只是郵件收發,也要負責與 Google 雲端硬碟和 Google日曆連動的任務處理和排程需求,因為這種特殊性, Gmail 中隱藏了許多高效率的專屬功能,或許長期使用 Gmail 的朋友也不一定發現。
今天這篇文章,我想分享的是自己多年來使用 Gmail 的經驗裡覺得非常有用的 16 個特殊功能,值得大家好好研究。
不過在除了知道有哪些隱藏的、附加的特殊功能外,我也建議大家搭配電腦玩物陸續分享過的「 Gmail 管理策略」一起使用才能發揮 Gmail 真正的功力:
如果你在使用其他電子郵件系統時遇到了郵件雜多凌亂,無法有效找到重要郵件,於是也無法專注在關鍵任務處理的難題,那麼 Gmail 內建的自動分類功能,就是幫我們找出重點郵件。
可是如果你在應用 Gmail 自動分類功能時,覺得他的需求還無法完全滿足你,那麼建議看看我上面提供的那篇文章。
透過這個自動分類,整理 Gmail 不再需要我們自己浪費時間與精力,而收件匣可以保持清爽聚焦,處理重點任務時更加得心應手。

如果你的工作對於郵件處理有更高層級的要求,不只是把郵件回覆完而已,還可能需要排程郵件到某一天時再處理,或是持續追蹤某一封重要郵件的進度。這時候,你應該要知道 Gmail 裡面有一個「工作表」的功能,值得好好利用。
工作表在哪裡?參考我上面那篇教學便可以獲得解答,而學會功能後,也建議大家參考電腦玩物的:「Google Tasks 工作表的 10 個待辦事項管理方法心得建議」,在 Gmail 裡打造真正的郵件時間管理。

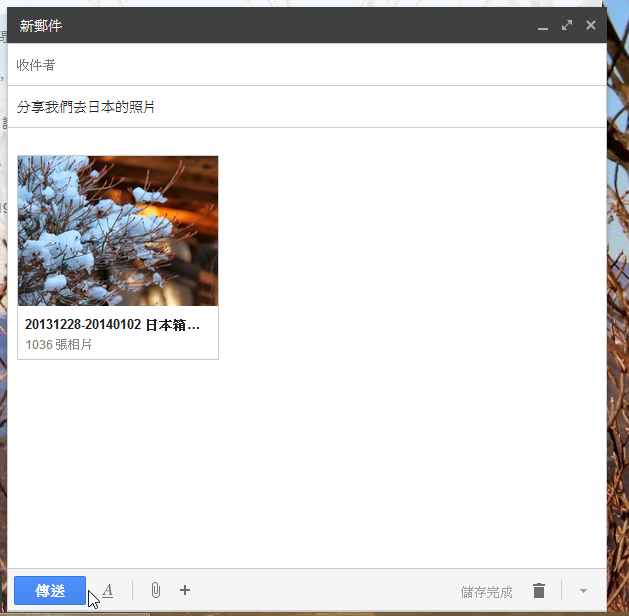
經由與雲端空間的連結, Gmail 也改變了我們寄送郵件附加檔案的方式。如果在 Gmail 裡想要寄送大量照片,甚至這次活動出遊的幾百張照片給朋友、同事,最好的方式就是利用內建的「 Google 雲端相簿」。
用郵件分享照片,就再也沒有檔案數量、大小的限制,對方甚至可以隨時看到我們後續在相簿裡新增的照片內容
Gmail 透過跟 Google Drive 雲端硬碟的連動,也改變了我們工作上用電子郵件附加檔案傳送重要文件時的溝通難題,除了沒有文件大小的限制,能夠一次傳送更多、超大檔案外,我們也不用因為文件需要更新而彼此不斷反覆寄信,最後搞亂檔案版本,也造成大家的溝通困擾。
在 Gmail 中如何利用內建的 Google Drive 功能,直接分享雲端文件、即時協同編輯、雲端儲存附加檔案、雲端編輯 Office 文件附檔,並且不需透過再次、三次郵件就能讓團隊成員保持後續的檔案更新,推薦大家一定要看看小標題這篇文章提供的功能。

Gmail 把撰寫新郵件的視窗變成右下方的浮動彈出畫面後,撰寫新郵件就變成一件更有效率的動作,這個新功能最好的利用方式,就是一邊撰寫新郵件,一邊在背後的郵件匣裡搜尋相關工作的舊郵件,互相對照參考,寫郵件時不再需要為了切換視窗而煩惱。

Gmail 雖然是雲端郵件,但是可不可以離線工作呢?可以的,因此像是我在雲端的 Google Chromebook 筆電上,一樣可以離線撰寫 Gmail 郵件、查看 Gmail 郵件。
只要安裝上面這篇文章提到的 Google 自製套件「離線版 Gmail 」,就會自動儲存最近收到的郵件,提供離線讀取功能,也能在離線介面中先撰寫好郵件草稿,事後上網時再寄出。

Gmail 在查看郵件時也提供了很有用的附加資訊,在郵件內文的右方,會顯示這個寄件者相關的連絡人資訊,以及最近我和他的通信內容。
這個好用的附加資訊,可以讓我在處理郵件時,快速打電話、傳訊息給對方,或是快速找到我們上一次工作時處理的附加檔案文件,讓工作的進展更順利。

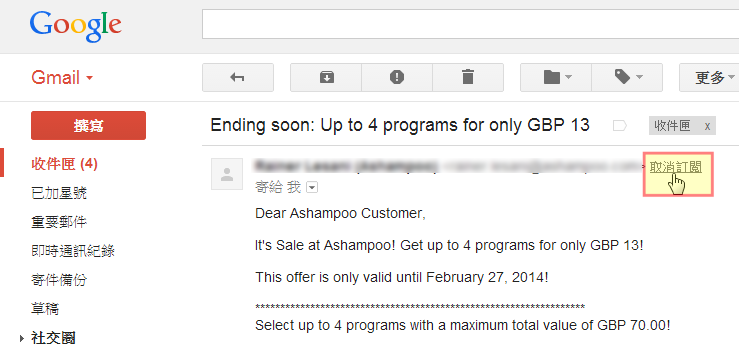
有時候我們收到的額外郵件不一定是垃圾郵件,也可能是我們之前訂閱,但是現在不想續訂的資訊,可是要回到當初的服務去退訂其實有點麻煩。而在 Gmail 中,我們可以注意看看收到的郵件寄件者附近,有時候會出現「取消訂閱」的連結,幫助我們快速退訂某些電子報或工具更新訊息。
這是一個我建議一定要根據我上面這篇文章的教學,在 Gmail 中開啟的「反悔」功能,讓我們不小心或手快按下寄出後,臨時發現有什麼需要修改的地方,可以立刻按下復原反悔,收回剛剛寄出的郵件。

你知道從 Gmail 寄出的郵件,我們的寄件人帳號不一定只能使用 Gmail 帳號,也可以使用公司或你其他的郵件帳號嗎?
而且我們還可以幫每個郵件帳號設定不同的簽名檔,在 Gmail 裡就可以直接完成不同郵件帳號的發信中心。
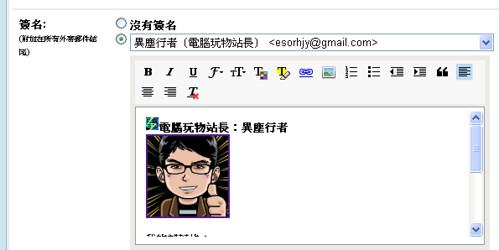
方法很簡單,在 Gmail 的設定裡,找到「帳戶和匯入」頁面,在「以這個地址寄送郵件」項目中「新增您的另一個電子郵件地址」。
這樣一來,我就可以在 Gmail 裡使用不同的非 Gmail 郵件帳戶發信,例如我的公司信箱帳號發信。
而且更棒的是,對方收到郵件後看到的寄件者是我的公司信箱,可是對方如果選擇直接回信,這封郵件一樣會寄回我的 Gmail 裡!這麼方便的功能一定要學起來。

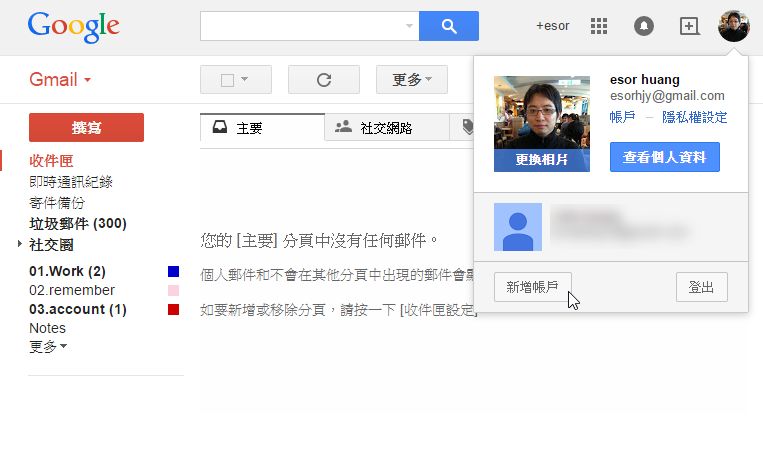
若是另外一種情況,我有多個 Gmail 帳號信箱,並且工作與私人之間常常要切換處理,那麼這時候 Gmail 一樣提供內建的快速切換多帳號功能,讓我們處理不同信箱郵件。
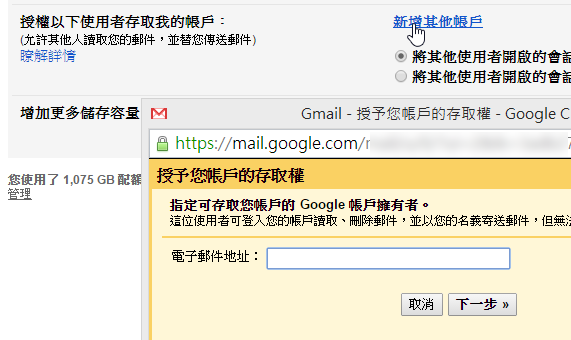
另外一個隱藏版 Gmail 好用功能,就是如果我很忙,或是有團隊合作需要,我可以授權家人、同事幫我處理我的 Gmail 郵件。
一樣是到 Gmail 設定裡的「帳戶和匯入」,找到「授權以下使用者存取我的帳戶」項目,新增其他帳戶,輸入對方的郵件地址,完成後續的認證,就能讓對方擁有讀取、刪除、寄送我的 Gmail 的權限!
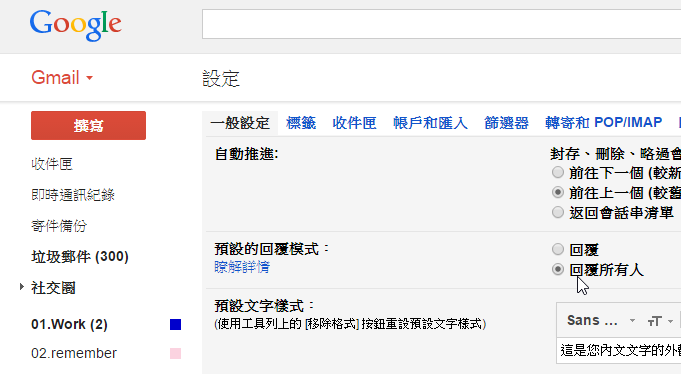
你常常在團隊溝通的來往郵件裡,回信時忘記「回覆給所有人」,導致某些訊息只傳給某個人看,而團隊其他夥伴沒收到嗎?
這時候記得到 Gmail 設定中的「一般設定」,在「預設的回覆模式」勾選「回覆所有人」,就能在每次回信時,自動回信給前封郵件裡的所有收信人。
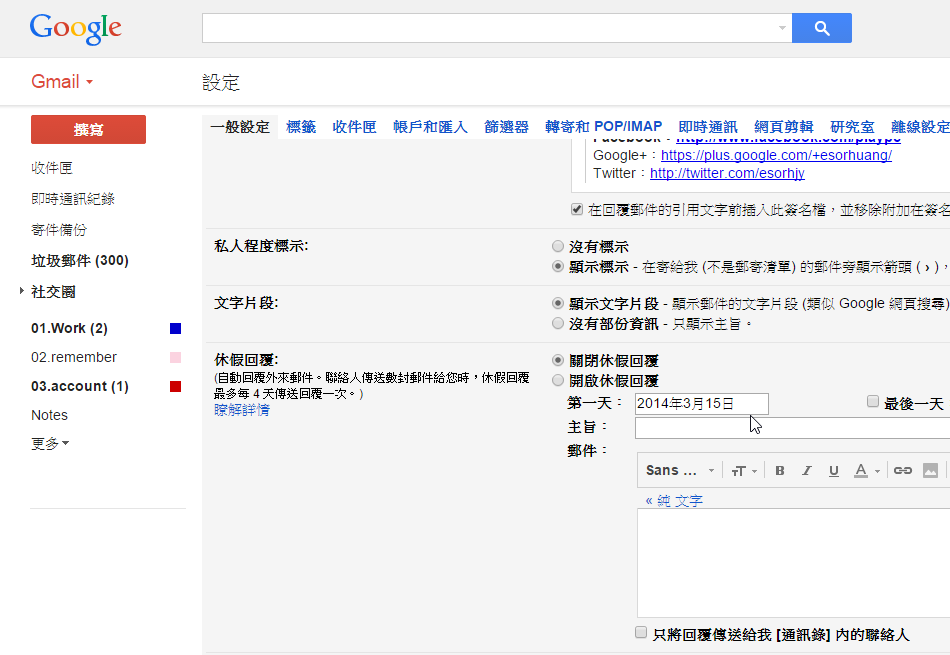
現代人可能愈來愈難區分工作與生活時間,很多職業都必須在週末也專注有沒有收到重要郵件。但是,如果現在真的是我們「年度重要休假」的時間,不僅我們不想收到工作郵件,也可能休假的地方真的不方便收信,那麼記得去開啟「休假回覆」功能。
在 Gmail 的「一般設定」裡就能自訂休假自動回覆,讓這段時間來信的人知道我們什麼時候會回到工作岡位,什麼時候可以回信給他們。
前面分享的主要都是 Gmail 網頁版上的功能,但是面對現在愈來愈常發生的行動工作需求,那麼上面這篇我在電腦玩物撰寫過的 Gmail App 技巧攻略,相信可以讓我們在 Android 上也能完成這篇文章裡提到的需求超級便利的工作技巧。


最後一個 Gmail 秘密功能,我要跟大家推薦的是「 Google Inbox 」這個獨立的 Google 新郵件任務管理系統。 Inbox 或許沒有上述那麼多 Gmail 強大的功能,但是 Inbox 前瞻的提出了一個他自己獨有的特色:「智慧型的任務時間管理系統」。
如果說你也跟我一樣,覺得郵件的目的不是收發信,收發信只是一個執行動作,而他背後的目的是「完成我們的任務」。那麼我推薦你試試看 Google Inbox ,他正是偏重在如何更聰明、有效的幫助我們完成任務上。
以上,就是我推薦 Gmail 使用者一定要知道的 16 個特殊的、有用的,或是隱藏的功能,每個功能對我來說,現在都還是會使用到的技巧,裡面有你還沒善用的嗎?希望可以幫大家完成更高效率的郵件管理。
你一定也會想看:
轉載本文請註明來自電腦玩物原創,作者 esor huang(異塵行者),並附上原文連結:Gmail 16 個秘密功能教學:學會最高效率的郵件管理







Gmail 16 個秘密功能教學:學會最高效率的郵件管理
by esor huang
Google 的 Gmail 可能是近幾年來大家使用率最高的郵件系統之一,當年很多人因為它強大的垃圾郵件過濾功能轉而使用,不過也因為一開始大家只看到郵件過濾,而可能忽略了活用 Gmail 可以使用的特殊方法與功能。
作為 Google 雲端工作平台的一員, Gmail 負擔的不只是郵件收發,也要負責與 Google 雲端硬碟和 Google日曆連動的任務處理和排程需求,因為這種特殊性, Gmail 中隱藏了許多高效率的專屬功能,或許長期使用 Gmail 的朋友也不一定發現。
今天這篇文章,我想分享的是自己多年來使用 Gmail 的經驗裡覺得非常有用的 16 個特殊功能,值得大家好好研究。
不過在除了知道有哪些隱藏的、附加的特殊功能外,我也建議大家搭配電腦玩物陸續分享過的「 Gmail 管理策略」一起使用才能發揮 Gmail 真正的功力:
- 1. 整理 Gmail 郵件的最佳方法:Gmail 收件匣自動分類活用,不需手動懶人整理郵件方法
如果你在使用其他電子郵件系統時遇到了郵件雜多凌亂,無法有效找到重要郵件,於是也無法專注在關鍵任務處理的難題,那麼 Gmail 內建的自動分類功能,就是幫我們找出重點郵件。
可是如果你在應用 Gmail 自動分類功能時,覺得他的需求還無法完全滿足你,那麼建議看看我上面提供的那篇文章。
透過這個自動分類,整理 Gmail 不再需要我們自己浪費時間與精力,而收件匣可以保持清爽聚焦,處理重點任務時更加得心應手。
- 2. 利用 Gmail 工作表排程處理:如何利用Gmail Tasks工作表規劃郵件分工處理流程?心得分享
如果你的工作對於郵件處理有更高層級的要求,不只是把郵件回覆完而已,還可能需要排程郵件到某一天時再處理,或是持續追蹤某一封重要郵件的進度。這時候,你應該要知道 Gmail 裡面有一個「工作表」的功能,值得好好利用。
工作表在哪裡?參考我上面那篇教學便可以獲得解答,而學會功能後,也建議大家參考電腦玩物的:「Google Tasks 工作表的 10 個待辦事項管理方法心得建議」,在 Gmail 裡打造真正的郵件時間管理。
- 3. 傳送上千張照片相簿:Gmail 無限制分享手機電腦照片!新增插入 Google 相簿
經由與雲端空間的連結, Gmail 也改變了我們寄送郵件附加檔案的方式。如果在 Gmail 裡想要寄送大量照片,甚至這次活動出遊的幾百張照片給朋友、同事,最好的方式就是利用內建的「 Google 雲端相簿」。
用郵件分享照片,就再也沒有檔案數量、大小的限制,對方甚至可以隨時看到我們後續在相簿裡新增的照片內容
- 4. 附加超大檔案文件:Gmail 開始支援直接編輯 Office 附件
Gmail 透過跟 Google Drive 雲端硬碟的連動,也改變了我們工作上用電子郵件附加檔案傳送重要文件時的溝通難題,除了沒有文件大小的限制,能夠一次傳送更多、超大檔案外,我們也不用因為文件需要更新而彼此不斷反覆寄信,最後搞亂檔案版本,也造成大家的溝通困擾。
在 Gmail 中如何利用內建的 Google Drive 功能,直接分享雲端文件、即時協同編輯、雲端儲存附加檔案、雲端編輯 Office 文件附檔,並且不需透過再次、三次郵件就能讓團隊成員保持後續的檔案更新,推薦大家一定要看看小標題這篇文章提供的功能。
- 5. 善用新郵件浮動撰寫視窗:Gmail 撰寫新郵件功能大升級!浮動視窗寫信更快更方便
Gmail 把撰寫新郵件的視窗變成右下方的浮動彈出畫面後,撰寫新郵件就變成一件更有效率的動作,這個新功能最好的利用方式,就是一邊撰寫新郵件,一邊在背後的郵件匣裡搜尋相關工作的舊郵件,互相對照參考,寫郵件時不再需要為了切換視窗而煩惱。

- 6. 如何離線處理 Gmail 郵件:Offline Google Mail 離線版Gmail
Gmail 雖然是雲端郵件,但是可不可以離線工作呢?可以的,因此像是我在雲端的 Google Chromebook 筆電上,一樣可以離線撰寫 Gmail 郵件、查看 Gmail 郵件。
只要安裝上面這篇文章提到的 Google 自製套件「離線版 Gmail 」,就會自動儲存最近收到的郵件,提供離線讀取功能,也能在離線介面中先撰寫好郵件草稿,事後上網時再寄出。

- 7. 善用郵件聯絡人附加資訊:強化 Gmail 聯絡人商務名片
Gmail 在查看郵件時也提供了很有用的附加資訊,在郵件內文的右方,會顯示這個寄件者相關的連絡人資訊,以及最近我和他的通信內容。
這個好用的附加資訊,可以讓我在處理郵件時,快速打電話、傳訊息給對方,或是快速找到我們上一次工作時處理的附加檔案文件,讓工作的進展更順利。
- 8. 快速退訂電子郵件:Gmail 內建「取消訂閱」讓你一鍵退訂電子報!功能實測心得
有時候我們收到的額外郵件不一定是垃圾郵件,也可能是我們之前訂閱,但是現在不想續訂的資訊,可是要回到當初的服務去退訂其實有點麻煩。而在 Gmail 中,我們可以注意看看收到的郵件寄件者附近,有時候會出現「取消訂閱」的連結,幫助我們快速退訂某些電子報或工具更新訊息。
- 9. 即時反悔寄出的郵件:別再誤發失禮郵件!一定要開啟的 Gmail 取消傳送功能
這是一個我建議一定要根據我上面這篇文章的教學,在 Gmail 中開啟的「反悔」功能,讓我們不小心或手快按下寄出後,臨時發現有什麼需要修改的地方,可以立刻按下復原反悔,收回剛剛寄出的郵件。
- 10. 自訂我的不同寄件人帳號與郵件簽名檔: Gmail郵件簽名終於支援自訂字體、顏色、圖片與區分發信帳號
你知道從 Gmail 寄出的郵件,我們的寄件人帳號不一定只能使用 Gmail 帳號,也可以使用公司或你其他的郵件帳號嗎?
而且我們還可以幫每個郵件帳號設定不同的簽名檔,在 Gmail 裡就可以直接完成不同郵件帳號的發信中心。
方法很簡單,在 Gmail 的設定裡,找到「帳戶和匯入」頁面,在「以這個地址寄送郵件」項目中「新增您的另一個電子郵件地址」。
這樣一來,我就可以在 Gmail 裡使用不同的非 Gmail 郵件帳戶發信,例如我的公司信箱帳號發信。
而且更棒的是,對方收到郵件後看到的寄件者是我的公司信箱,可是對方如果選擇直接回信,這封郵件一樣會寄回我的 Gmail 裡!這麼方便的功能一定要學起來。
- 11. 快速切換多個 Gmail 帳號:Google Multiple Sign-in 同時開雙Gmail,多重帳號登入功能筆記
若是另外一種情況,我有多個 Gmail 帳號信箱,並且工作與私人之間常常要切換處理,那麼這時候 Gmail 一樣提供內建的快速切換多帳號功能,讓我們處理不同信箱郵件。
- 12. 授權其他使用者幫我收信發信
另外一個隱藏版 Gmail 好用功能,就是如果我很忙,或是有團隊合作需要,我可以授權家人、同事幫我處理我的 Gmail 郵件。
一樣是到 Gmail 設定裡的「帳戶和匯入」,找到「授權以下使用者存取我的帳戶」項目,新增其他帳戶,輸入對方的郵件地址,完成後續的認證,就能讓對方擁有讀取、刪除、寄送我的 Gmail 的權限!
- 13. 預設為回覆所有人
你常常在團隊溝通的來往郵件裡,回信時忘記「回覆給所有人」,導致某些訊息只傳給某個人看,而團隊其他夥伴沒收到嗎?
這時候記得到 Gmail 設定中的「一般設定」,在「預設的回覆模式」勾選「回覆所有人」,就能在每次回信時,自動回信給前封郵件裡的所有收信人。
- 14. 大絕招,休假自動回覆
現代人可能愈來愈難區分工作與生活時間,很多職業都必須在週末也專注有沒有收到重要郵件。但是,如果現在真的是我們「年度重要休假」的時間,不僅我們不想收到工作郵件,也可能休假的地方真的不方便收信,那麼記得去開啟「休假回覆」功能。
在 Gmail 的「一般設定」裡就能自訂休假自動回覆,讓這段時間來信的人知道我們什麼時候會回到工作岡位,什麼時候可以回信給他們。
- 15. 如何活用 Gmail Android App :Gmail Android App 你可能不知道的 10 個郵件效率技巧
前面分享的主要都是 Gmail 網頁版上的功能,但是面對現在愈來愈常發生的行動工作需求,那麼上面這篇我在電腦玩物撰寫過的 Gmail App 技巧攻略,相信可以讓我們在 Android 上也能完成這篇文章裡提到的需求超級便利的工作技巧。


- 16. 搭配新世代任務管理 Google Inbox:完全解密 Google Inbox !十大功能改造Gmail實測教學
最後一個 Gmail 秘密功能,我要跟大家推薦的是「 Google Inbox 」這個獨立的 Google 新郵件任務管理系統。 Inbox 或許沒有上述那麼多 Gmail 強大的功能,但是 Inbox 前瞻的提出了一個他自己獨有的特色:「智慧型的任務時間管理系統」。
如果說你也跟我一樣,覺得郵件的目的不是收發信,收發信只是一個執行動作,而他背後的目的是「完成我們的任務」。那麼我推薦你試試看 Google Inbox ,他正是偏重在如何更聰明、有效的幫助我們完成任務上。
以上,就是我推薦 Gmail 使用者一定要知道的 16 個特殊的、有用的,或是隱藏的功能,每個功能對我來說,現在都還是會使用到的技巧,裡面有你還沒善用的嗎?希望可以幫大家完成更高效率的郵件管理。
你一定也會想看:
轉載本文請註明來自電腦玩物原創,作者 esor huang(異塵行者),並附上原文連結:Gmail 16 個秘密功能教學:學會最高效率的郵件管理
Ernest likes this
12 Jan 00:59
单例这种设计模式
by 技术小黑屋
随着我们编写代码的深入,我们或多或少都会接触到设计模式,其中单例(Singleton)模式应该是我们耳熟能详的一种模式。本文将比较特别的介绍一下Java设计模式中的单例模式。
概念
单例模式,又称单件模式或者单子模式,指的是一个类只有一个实例,并且提供一个全局访问点。
实现思路
- 在单例的类中设置一个private静态变量sInstance,sInstance类型为当前类,用来持有单例唯一的实例。
- 将(无参数)构造器设置为private,避免外部使用new构造多个实例。
- 提供一个public的静态方法,如getInstance,用来返回该类的唯一实例sInstance。
其中上面的单例的实例可以有以下几种创建形式,每一种实现都需要保证实例的唯一性。
饿汉式
饿汉式指的是单例的实例在类装载时进行创建。如果单例类的构造方法中没有包含过多的操作处理,饿汉式其实是可以接受的。
饿汉式的常见代码如下,当SingleInstance类加载时会执行private static SingleInstance sInstance = new SingleInstance();初始化了唯一的实例,然后getInstance()直接返回sInstance即可。
1 2 3 4 5 6 7 8 9 10 |
public class SingleInstance {
private static SingleInstance sInstance = new SingleInstance();
private SingleInstance() {
}
public static SingleInstance getInstance() {
return sInstance;
}
}
|
饿汉式的问题
- 如果构造方法中存在过多的处理,会导致加载这个类时比较慢,可能引起性能问题。
- 如果使用饿汉式的话,只进行了类的装载,并没有实质的调用,会造成资源的浪费。
懒汉式
懒汉式指的是单例实例在第一次使用时进行创建。这种情况下避免了上面饿汉式可能遇到的问题。
但是考虑到多线程的并发操作,我们不能 简简单单得像下面代码实现。
1 2 3 4 5 6 7 8 9 10 11 12 |
public class SingleInstance {
private static SingleInstance sInstance;
private SingleInstance() {
}
public static SingleInstance getInstance() {
if (null == sInstance) {
sInstance = new SingleInstance();
}
return sInstance;
}
}
|
上述的代码在多个线程密集调用getInstance时,存在创建多个实例的可能。比如线程A进入null == sInstance这段代码块,而在A线程未创建完成实例时,如果线程B也进入了该代码块,必然会造成两个实例的产生。
synchronized修饰方法
使用synchrnozed修饰getInstance方法可能是最简单的一个保证多线程保证单例唯一性的方法。
synchronized修饰的方法后,当某个线程进入调用这个方法,该线程只有当其他线程离开当前方法后才会进入该方法。所以可以保证getInstance在任何时候只有一个线程进入。
1 2 3 4 5 6 7 8 9 10 11 12 |
public class SingleInstance {
private static SingleInstance sInstance;
private SingleInstance() {
}
public static synchronized SingleInstance getInstance() {
if (null == sInstance) {
sInstance = new SingleInstance();
}
return sInstance;
}
}
|
但是使用synchronized修饰getInstance方法后必然会导致性能下降,而且getInstance是一个被频繁调用的方法。虽然这种方法能解决问题,但是不推荐。
双重检查加锁
使用双重检查加锁,首先进入该方法时进行null == sInstance检查,如果第一次检查通过,即没有实例创建,则进入synchronized控制的同步块,并再次检查实例是否创建,如果仍未创建,则创建该实例。
双重检查加锁保证了多线程下只创建一个实例,并且加锁代码块只在实例创建的之前进行同步。如果实例已经创建后,进入该方法,则不会执行到同步块的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public class SingleInstance {
private static volatile SingleInstance sInstance;
private SingleInstance() {
}
public static SingleInstance getInstance() {
if (null == sInstance) {
synchronized (SingleInstance.class) {
if (null == sInstance) {
sInstance = new SingleInstance();
}
}
}
return sInstance;
}
}
|
volatile是什么
Volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。使用volatile修饰sInstance变量之后,可以确保多个线程之间正确处理sInstance变量。
关于volatile,可以访问深入分析Volatile的实现原理了解更多。
利用static机制
在Java中,类的静态初始化会在类被加载时触发,我们利用这个原理,可以实现利用这一特性,结合内部类,可以实现如下的代码,进行懒汉式创建实例。
1 2 3 4 5 6 7 8 9 10 11 12 |
public class SingleInstance {
private SingleInstance() {
}
public static SingleInstance getInstance() {
return SingleInstanceHolder.sInstance;
}
private static class SingleInstanceHolder {
private static SingleInstance sInstance = new SingleInstance();
}
}
|
关于这种机制,可以具体了解双重检查锁定与延迟初始化
好奇问题
真的只有一个对象么
其实,单例模式并不能保证实例的唯一性,只要我们想办法的话,还是可以打破这种唯一性的。以下几种方法都能实现。
- 使用反射,虽然构造器为非公开,但是在反射面前就不起作用了。
- 如果单例的类实现了cloneable,那么还是可以拷贝出多个实例的。
- Java中的对象序列化也有可能导致创建多个实例。避免使用readObject方法。
- 使用多个类加载器加载单例类,也会导致创建多个实例并存的问题。
单例可以继承么
单例类能否被继承需要分情况而定。
可以继承的情况
当子类是父类单例类的内部类时,继承是可以的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
public class BaseSingleton {
private static volatile BaseSingleton sInstance;
private BaseSingleton() {
}
public static BaseSingleton getInstance() {
if (null == sInstance) {
synchronized(BaseSingleton.class) {
if (null == sInstance) {
sInstance = new BaseSingleton();
}
}
}
return sInstance;
}
public static class MySingleton extends BaseSingleton {
}
}
|
但是上面仅仅是编译和执行上允许的,但是继承单例没有实际的意义,反而会变得更加事倍功半,其代价要大于新写一个单例类。感兴趣的童鞋可以尝试折腾一下。
不可以继承的情况
如果子类为单独的类,非单例类的内部类的话,那么在编译时就会出错Implicit super constructor BaseSingleton() is not visible for default constructor. Must define an explicit constructor,主要原因是单例类的构造器是private,解决方法是讲构造器设置为可见,但是这样做就无法保证单例的唯一性。所以这种方式不可以继承。
总的来说,单例类不要继承。
单例 vs static变量
全局静态变量也可以实现单例的效果,但是使用全局变量无法保证只创建一个实例,而且使用全局变量的形式,需要团队的约束,执行起来可能会出现问题。
关于GC
因为单例类中又一个静态的变量持有单例的实例,所以相比普通的对象,单例的对象更不容易被GC回收掉。单例对象的回收应该发生在其类加载器被GC回收掉之后,一般不容易出现。
相关阅读
一本书
Head First设计模式,本书荣获2005年第十五届Jolt通用类图书震撼大奖。本书英文影印版被《程序员》等机构评选为2006年最受读者喜爱的十大IT图书之一 。本书趋近完美,因为它在提供专业知识的同时,仍然具有相当高的可读性。叙述权威、文笔优美。
 0
0
 0
0
由 udpwork.com 聚合 | 评论: 0 | 要! 要! 即刻! Now!
Ernest likes this
10 Jan 04:30
Java序列化示例教程
by Justin Wu
Java序列化是在JDK 1.1中引入的,是Java内核的重要特性之一。Java序列化API允许我们将一个对象转换为流,并通过网络发送,或将其存入文件或数据库以便未来使用,反序列化则是将对象流转换为实际程序中使用的Java对象的过程。Java同步化过程乍看起来很好用,但它会带来一些琐碎的安全性和完整性问题,在文章的后面部分我们会涉及到,以下是本教程涉及的主题。
- Java序列化接口
- 使用序列化和serialVersionUID进行类重构
- Java外部化接口
- Java序列化方法
- 序列化结合继承
- 序列化代理模式
Java序列化接口
如果你希望一个类对象是可序列化的,你所要做的是实现java.io.Serializable接口。序列化一种标记接口,不需要实现任何字段和方法,这就像是一种选择性加入的处理,通过它可以使类对象成为可序列化的对象。
序列化处理是通过ObjectInputStream和ObjectOutputStream实现的,因此我们所要做的是基于它们进行一层封装,要么将其保存为文件,要么将其通过网络发送。我们来看一个简单的序列化示例。
package com.journaldev.serialization;
import java.io.Serializable;
public class Employee implements Serializable {
// private static final long serialVersionUID = -6470090944414208496L;
private String name;
private int id;
transient private int salary;
// private String password;
@Override
public String toString(){
return "Employee{name="+name+",id="+id+",salary="+salary+"}";
}
//getter and setter methods
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
// public String getPassword() {
// return password;
// }
//
// public void setPassword(String password) {
// this.password = password;
// }
}
注意一下,这是一个简单的java bean,拥有一些属性以及getter-setter方法,如果你想要某个对象属性不被序列化成流,你可以使用transient关键字,正如示例中我在salary变量上的做法那样。
现在我们假设需要把我们的对象写入文件,之后从相同的文件中将其反序列化,因此我们需要一些工具方法,通过使用ObjectInputStream和ObjectOutputStream来达到序列化的目的。
package com.journaldev.serialization;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
/**
* A simple class with generic serialize and deserialize method implementations
*
* @author pankaj
*
*/
public class SerializationUtil {
// deserialize to Object from given file
public static Object deserialize(String fileName) throws IOException,
ClassNotFoundException {
FileInputStream fis = new FileInputStream(fileName);
ObjectInputStream ois = new ObjectInputStream(fis);
Object obj = ois.readObject();
ois.close();
return obj;
}
// serialize the given object and save it to file
public static void serialize(Object obj, String fileName)
throws IOException {
FileOutputStream fos = new FileOutputStream(fileName);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(obj);
fos.close();
}
}
注意一下,方法的参数是Object,它是任何Java类的基类,这样写法以一种很自然的方式保证了通用性。
现在我们来写一个测试程序,看一下Java序列化的实战。
package com.journaldev.serialization;
import java.io.IOException;
public class SerializationTest {
public static void main(String[] args) {
String fileName="employee.ser";
Employee emp = new Employee();
emp.setId(100);
emp.setName("Pankaj");
emp.setSalary(5000);
//serialize to file
try {
SerializationUtil.serialize(emp, fileName);
} catch (IOException e) {
e.printStackTrace();
return;
}
Employee empNew = null;
try {
empNew = (Employee) SerializationUtil.deserialize(fileName);
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
System.out.println("emp Object::"+emp);
System.out.println("empNew Object::"+empNew);
}
}
运行以上测试程序,可以得到以下输出。
emp Object::Employee{name=Pankaj,id=100,salary=5000}
empNew Object::Employee{name=Pankaj,id=100,salary=0}
由于salary是一个transient变量,它的值不会被存入文件中,因此也不会在新的对象中被恢复。类似的,静态变量的值也不会被序列化,因为他们是属于类而非对象的。
使用序列化和serialVersionUID进行类重构
Java序列化允许java类中的一些变化,如果他们可以被忽略的话。一些不会影响到反序列化处理的变化有:
- 在类中添加一些新的变量。
- 将变量从transient转变为非tansient,对于序列化来说,就像是新加入了一个变量而已。
- 将变量从静态的转变为非静态的,对于序列化来说,就也像是新加入了一个变量而已。
不过这些变化要正常工作,java类需要具有为该类定义的serialVersionUID,我们来写一个测试类,只对之前测试类已经生成的序列化文件进行反序列化。
package com.journaldev.serialization;
import java.io.IOException;
public class DeserializationTest {
public static void main(String[] args) {
String fileName="employee.ser";
Employee empNew = null;
try {
empNew = (Employee) SerializationUtil.deserialize(fileName);
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
System.out.println("empNew Object::"+empNew);
}
}
现在,在Employee类中去掉”password”变量的注释和它的getter-setter方法,运行。你会得到以下异常。
java.io.InvalidClassException: com.journaldev.serialization.Employee; local class incompatible: stream classdesc serialVersionUID = -6470090944414208496, local class serialVersionUID = -6234198221249432383 at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:604) at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1601) at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1514) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1750) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1347) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:369) at com.journaldev.serialization.SerializationUtil.deserialize(SerializationUtil.java:22) at com.journaldev.serialization.DeserializationTest.main(DeserializationTest.java:13) empNew Object::null
原因很显然,上一个类和新类的serialVersionUID是不同的,事实上如果一个类没有定义serialVersionUID,它会自动计算出来并分配给该类。Java使用类变量、方法、类名称、包,等等来产生这个特殊的长数。如果你在任何一个IDE上工作,你都会得到警告“可序列化类Employee没有定义一个静态的final的serialVersionUID,类型为long”。
我们可以使用java工具”serialver”来产生一个类的serialVersionUID,对于Employee类,可以执行以下命令。
SerializationExample/bin$serialver -classpath . com.journaldev.serialization.Employee
记住,从程序本身生成序列版本并不是必须的,我们可以根据需要指定值,这个值的作用仅仅是告知反序列化处理机制,新的类是相同的类的新版本,应该进行可能的反序列化处理。
举个例子,在Employee类中仅仅将serialVersionUID字段的注释去掉,运行SerializationTest程序。现在再将Employee类中的password字段的注释去掉,运行DeserializationTest程序,你会看到对象流被成功地反序列化了,因为Employee类中的变动与序列化处理是相容的。
Java外部化接口
如果你在序列化处理中留个心,你会发现它是自动处理的。有时候我们想要去隐藏对象数据,来保持它的完整性,可以通过实现java.io.Externalizable接口,并提供writeExternal()和readExternal()方法的实现,它们被用于序列化处理。
package com.journaldev.externalization;
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
public class Person implements Externalizable{
private int id;
private String name;
private String gender;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeInt(id);
out.writeObject(name+"xyz");
out.writeObject("abc"+gender);
}
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
id=in.readInt();
//read in the same order as written
name=(String) in.readObject();
if(!name.endsWith("xyz")) throw new IOException("corrupted data");
name=name.substring(0, name.length()-3);
gender=(String) in.readObject();
if(!gender.startsWith("abc")) throw new IOException("corrupted data");
gender=gender.substring(3);
}
@Override
public String toString(){
return "Person{id="+id+",name="+name+",gender="+gender+"}";
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
}
注意,在将其转换为流之前,我已经更改了字段的值,之后读取时会得到这些更改,通过这种方式,可以在某种程度上保证数据的完整性,我们可以在读取流数据之后抛出异常,表明完整性检查失败。来看一个测试程序。
package com.journaldev.externalization;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class ExternalizationTest {
public static void main(String[] args) {
String fileName = "person.ser";
Person person = new Person();
person.setId(1);
person.setName("Pankaj");
person.setGender("Male");
try {
FileOutputStream fos = new FileOutputStream(fileName);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
FileInputStream fis;
try {
fis = new FileInputStream(fileName);
ObjectInputStream ois = new ObjectInputStream(fis);
Person p = (Person)ois.readObject();
ois.close();
System.out.println("Person Object Read="+p);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
运行以上测试程序,可以得到以下输出。
Person Object Read=Person{id=1,name=Pankaj,gender=Male}
那么哪个方式更适合被用来做序列化处理呢?实际上使用序列化接口更好,当你看到这篇教程的末尾时,你会知道原因的。
Java序列化方法
我们已经看到了,java的序列化是自动的,我们所要做的仅仅是实现序列化接口,其实现已经存在于ObjectInputStream和ObjectOutputStream类中了。不过如果我们想要更改存储数据的方式,比如说在对象中含有一些敏感信息,在存储/获取它们之前我们要进行加密/解密,这该怎么办呢?这就是为什么在类中我们拥有四种方法,能够改变序列化行为。
如果以下方法在类中存在,它们就会被用于序列化处理。
- readObject(ObjectInputStream ois):如果这个方法存在,ObjectInputStream readObject()方法会调用该方法从流中读取对象。
- writeObject(ObjectOutputStream oos):如果这个方法存在,ObjectOutputStream writeObject()方法会调用该方法从流中写入对象。一种普遍的用法是隐藏对象的值来保证完整性。
- Object writeReplace():如果这个方法存在,那么在序列化处理之后,该方法会被调用并将返回的对象序列化到流中。
- Object readResolve():如果这个方法存在,那么在序列化处理之后,该方法会被调用并返回一个最终的对象给调用程序。一种使用方法是在序列化类中实现单例模式,你可以从序列化和单例中读到更多知识。
通常情况下,当实现以上方法时,应该将其设定为私有类型,这样子类就无法覆盖它们了,因为它们本来就是为了序列化而建立的,设定为私有类型能避免一些安全性问题。
序列化结合继承
有时候我们需要对一个没有实现序列化接口的类进行扩展,如果依赖于自动化的序列化行为,而一些状态是父类拥有的,那么它们将不会被转换为流,因此以后也无法获取。
在此,readObject()和writeObject()就可以派上大用处了,通过提供它们的实现,我们可以将父类的状态存入流中,以便今后获取。我们来看一下实战。
package com.journaldev.serialization.inheritance;
public class SuperClass {
private int id;
private String value;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
父类是一个简单的java bean,没有实现序列化接口。
package com.journaldev.serialization.inheritance;
import java.io.IOException;
import java.io.InvalidObjectException;
import java.io.ObjectInputStream;
import java.io.ObjectInputValidation;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class SubClass extends SuperClass implements Serializable, ObjectInputValidation{
private static final long serialVersionUID = -1322322139926390329L;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString(){
return "SubClass{id="+getId()+",value="+getValue()+",name="+getName()+"}";
}
//adding helper method for serialization to save/initialize super class state
private void readObject(ObjectInputStream ois) throws ClassNotFoundException, IOException{
ois.defaultReadObject();
//notice the order of read and write should be same
setId(ois.readInt());
setValue((String) ois.readObject());
}
private void writeObject(ObjectOutputStream oos) throws IOException{
oos.defaultWriteObject();
oos.writeInt(getId());
oos.writeObject(getValue());
}
@Override
public void validateObject() throws InvalidObjectException {
//validate the object here
if(name == null || "".equals(name)) throw new InvalidObjectException("name can't be null or empty");
if(getId() <=0) throw new InvalidObjectException("ID can't be negative or zero");
}
}
注意,将额外数据写入流和读取流的顺序应该是一致的,我们可以在读与写之中添加一些逻辑,使其更安全。
同时还需要注意,这个类实现了ObjectInputValidation接口,通过实现validateObject()方法,可以添加一些业务验证来确保数据完整性没有遭到破坏。
以下通过编写一个测试类,看一下我们是否能够从序列化的数据中获取父类的状态。
package com.journaldev.serialization.inheritance;
import java.io.IOException;
import com.journaldev.serialization.SerializationUtil;
public class InheritanceSerializationTest {
public static void main(String[] args) {
String fileName = "subclass.ser";
SubClass subClass = new SubClass();
subClass.setId(10);
subClass.setValue("Data");
subClass.setName("Pankaj");
try {
SerializationUtil.serialize(subClass, fileName);
} catch (IOException e) {
e.printStackTrace();
return;
}
try {
SubClass subNew = (SubClass) SerializationUtil.deserialize(fileName);
System.out.println("SubClass read = "+subNew);
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
}
运行以上测试程序,可以得到以下输出。
SubClass read = SubClass{id=10,value=Data,name=Pankaj}
因此通过这种方式,可以序列化父类的状态,即便它没有实现序列化接口。当父类是一个我们无法改变的第三方的类,这个策略就有用武之地了。
序列化代理模式
Java序列化也带来了一些严重的误区,比如:
- 类的结构无法大量改变,除非中断序列化处理,因此即便我们之后已经不需要某些变量了,我们也需要保留它们,仅仅是为了向后兼容。
- 序列化会导致巨大的安全性危机,一个攻击者可以更改流的顺序,继而对系统造成伤害。举个例子,用户角色被序列化了,攻击者可以更改流的值为admin,再执行恶意代码。
序列化代理模式是一种使序列化能达到极高安全性的方式,在这个模式下,一个内部的私有静态类被用作序列化的代理类,该类的设计目的是用于保留主类的状态。这个模式的实现需要合理实现readResolve()和writeReplace()方法。
让我们先来写一个类,实现了序列化代码模式,之后再对其进行分析,以便更好的理解原理。
package com.journaldev.serialization.proxy;
import java.io.InvalidObjectException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class Data implements Serializable{
private static final long serialVersionUID = 2087368867376448459L;
private String data;
public Data(String d){
this.data=d;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public String toString(){
return "Data{data="+data+"}";
}
//serialization proxy class
private static class DataProxy implements Serializable{
private static final long serialVersionUID = 8333905273185436744L;
private String dataProxy;
private static final String PREFIX = "ABC";
private static final String SUFFIX = "DEFG";
public DataProxy(Data d){
//obscuring data for security
this.dataProxy = PREFIX + d.data + SUFFIX;
}
private Object readResolve() throws InvalidObjectException {
if(dataProxy.startsWith(PREFIX) && dataProxy.endsWith(SUFFIX)){
return new Data(dataProxy.substring(3, dataProxy.length() -4));
}else throw new InvalidObjectException("data corrupted");
}
}
//replacing serialized object to DataProxy object
private Object writeReplace(){
return new DataProxy(this);
}
private void readObject(ObjectInputStream ois) throws InvalidObjectException{
throw new InvalidObjectException("Proxy is not used, something fishy");
}
}
- Data和DataProxy类都应该实现序列化接口。
- DataProxy应该能够保留Data对象的状态。
- DataProxy是一个内部的私有静态类,因此其他类无法访问它。
- DataProxy应该有一个单独的构造方法,接收Data作为参数。
- Data类应该提供writeReplace()方法,返回DataProxy实例,这样当Data对象被序列化时,返回的流是属于DataProxy类的,不过DataProxy类在外部是不可见的,所有它不能被直接使用。
- DataProxy应该实现readResolve()方法,返回Data对象,这样当Data类被反序列化时,在内部其实是DataProxy类被反序列化了,之后它的readResolve()方法被调用,我们得到了Data对象。
- 最后,在Data类中实现readObject()方法,抛出InvalidObjectException异常,防止黑客通过伪造Data对象的流并对其进行解析,继而执行攻击。
我们来写一个小测试,检查一下这样的实现是否能工作。
package com.journaldev.serialization.proxy;
import java.io.IOException;
import com.journaldev.serialization.SerializationUtil;
public class SerializationProxyTest {
public static void main(String[] args) {
String fileName = "data.ser";
Data data = new Data("Pankaj");
try {
SerializationUtil.serialize(data, fileName);
} catch (IOException e) {
e.printStackTrace();
}
try {
Data newData = (Data) SerializationUtil.deserialize(fileName);
System.out.println(newData);
} catch (ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
}
运行以上测试程序,可以得到以下输出。
Data{data=Pankaj}
如果你打开data.ser文件,可以看到DataProxy对象已经被作为流存入了文件中。
这就是Java序列化的所有内容,看上去很简单但我们应当谨慎地使用它,通常来说,最好不要依赖于默认实现。你可以从上面的链接中下载项目,玩一玩,这能让你学到更多。
相关文章
Ernest likes this
09 Jan 06:34
大数据+机器学习+平台,所以Dato拿了1850万美元B轮融资
by tips+syq@36kr.com(小石头)

大数据在硅谷炙手可热,拿融资自然也不再话下,拿到千万级美元融资的也有不少,不久前大数据分析云服务GoodData就获得了Intel Capital领投的2750万美元。据华尔街日报消息,机器学习平台GraphLab 刚刚改名Dato,并获得了1850万美元新融资,投资方为Vulcan Capital 、Opus Capital 、New Enterprise Associates、Madrona Venture Group。此前他们曾获得680万美元融资。
GraphLab提供了一个完整的平台,让客户能够使用可扩展的机器学习系统进行大数据分析。简单来说,就是从别的应用程序或者服务中抓取数据,让机器学习这个模型,并将学到的知识作为基础,自动地进行准确的预测和决策制定。这么讲挺抽象,我们还是具体举几个例子吧。可能最好理解的就是民主国家政府的民意调查,可以通过社交网络、媒体等提取数据,分析出民众到底在关心什么,分析出哪些区域的哪些问题必须关注、解决。其实,生物医学研究团队也会使用GraphLab,主要是来分析临床记录,从而预测病人的病情发展趋势。零售业可以做价格预测、用户推荐;金融服务业可以做诈骗预警;市场公司则可以通过情绪分析锁定关键客户。现在GraphLab的客户已经包括Zillow、Adobe、Zynga、Pandora等。
那为什么是GraphLab(现在应该叫Dato了)会获得这么多客户的青睐呢? 其实,将原始数据转化为决策依据,并作出预测,这个过程还是很复杂的。往往需要大量的数据处理工具,收集、清洗数据,再建模分析,得出结论,进行展示;还需要大量的数据科学家或同样知识渊博的软件工程师来配合完成。既耗时费力,还投入不菲。所以GraphLab这样的平台,可以让毫无编程经验的数据科学家,快速地将理念转化为生产环境可以使用的产品,提高企业的生产效率,自然受欢迎。值得一提的是,Dato现在能处理各种数据类型。

GraphLab的创始人Carlos Guestrin是机器学习界国际公认的大牛,曾被Popular Science杂志评为2008年 “Brilliant 10”,还获得过美国青年科学家总统奖。2008年在卡耐基梅隆大学带着两个学生研发了GraphLab的原型,2012年被Jeff Bezos游说去了华盛顿大学。在Madrona Ventures和NEA的资金支持下,2014年3月创办了GraphLab,并以测试版的形式推出了第一个商业版。2013年10月,增加了机器学习功能,推出了新版本。现在的GraphLab已经不仅仅是图谱分析了,更是一家基于AI的大数据公司,能够处理各种数据类型,所以公司也改名叫Dato了。
我司在美帝的妹子小苏曾写过文章,详细的介绍了硅谷的大数据行业发展。在美国现在的大数据公司主要有四类:
- 数据的拥有者、数据源:特点是业务优势能收集到大量数据,就像煤老板垄断一个地区的矿一样。其实大多数有能力产生或收集数据的公司都属于这类型,比如Vantage Sports和收集了PB级数据的包子铺。
- 大数据咨询:特点是非常技术,提供从基础设施规划建设维护到软件开发和数据分析等的服务,但不拥有数据,比如Cloudera这家不到500人的startup是最著名的Hadoop架构咨询公司。
- 做大数据工具的:比如AMPLab出来的Databricks和Yahoo人主导的Hortonworks。
- 整合应用型:特点是收集拥有或购买一些数据,然后结合AI来解决更多实际的痛点。
像Dato这种做整合应用型的大数据公司才有可能有希望。未来是 AI 的,而 AI 的食物是数据。就像很多产业链一样,最困难且最有价值的创新往往发生在接近最终用户的那端,比如 iPhone。大数据行业最有价值的部分在于如何利用机器去处理数据得到洞见,影响组织和个人的行为,从而改变世界。收集和整理数据在未来会变得标准化和自动化,而利用 AI 进行分析的能力会变得更为关键。
新版36氪 iOS 客户端正式上线。该有的都有了,想看创业资讯,想分享,想看视频,想来活动现场,下载36氪 iOS 客户端,即氪触达。点击链接下载:http://lnk8.cn/kIxB9s
除非注明,本站文章均为原创或编译,转载请注明: 文章来自 36氪
Ernest likes this
08 Jan 12:12
java高效地读取大文件
by 刘志军
Java – Reading a Large File Efficiently
The post java高效地读取大文件 appeared first on 头条 - 伯乐在线.
Ernest likes this
08 Jan 11:37
PDF
Twitter
推荐!国外程序员整理的Java资源大全
by 唐尤华
构建
这里搜集了用来构建应用程序的工具。
- Apache Maven:Maven使用声明进行构建并进行依赖管理,偏向于使用约定而不是配置进行构建。Maven优于Apache Ant。后者采用了一种过程化的方式进行配置,所以维护起来相当困难。
- Gradle:Gradle采用增量构建。Gradle通过Groovy编程而不是传统的XML声明进行配置。Gradle可以很好地配合Maven进行依赖管理,并且把Ant脚本当作头等公民。
字节码操作
编程操作Java字节码的函数库。
- ASM:通用底层字节码操作及分析。
- Javassist:尝试简化字节码编辑。
- Byte Buddy:使用“流式API”进一步简化字节码生成。
代码分析
软件度量和质量评估工具。
- Checkstyle:对编程规范和标准进行静态分析。
- FindBugs:通过字节码静态分析找出潜在Bug。
- PMD:对源代码中不良编程习惯进行分析。
- SonarQube:通过插件集成其它分析组件,提供评估最终结果报告。
编译器
创建分析器、解释器和编译器的框架。
持续集成
支持持续集成、测试和应用发布的工具。
- Bamboo:Atlassian的持续集成(CI)解决方案,包含很多其它产品。
- CircleCI:提供托管服务,可免费试用。
- Codeship:提供托管服务,提供有限免费计划。
- Go:ThoughtWork开源持续集成解决方案。
- Jenkins:提供基于服务器的部署服务。
- TeamCity:JetBrain持续集成方案,提供免费版。
- Travis:提供托管服务,常用于开源项目。
数据库
简化数据库交互的工具、库。
- Flyway:使用Java API轻松完成数据库迁移。
- H2:小型SQL数据库,以内存操作著称。
- JDBI:便捷的JDBC抽象。
- jOOQ:基于SQL schema生成类型安全代码。
- Presto:针对大数据的分布式SQL查询引擎。
- Querydsl:针对Java的类型安全统一查询。
日期和时间
处理日期和时间的函数库。
依赖注入
帮助代码实现控制反转模式的函数库。
开发库
从基础层次上改进开发流程。
- AspectJ:面向切面编程扩展,与程序无缝连接。
- Auto:源代码生成器集合。
- DCEVM:通过修改JVM,在运行时可无限次重定义已加载的类。OpenJDK 7、8已提供支持,详情可查看这个分支(fork)。
- JRebel:商用软件,无需重新部署可即时重新加载代码及配置。
- Lombok:代码生成器,旨在减少Java冗余代码。
- RxJava:使用JVM中可观察序列,创建异步、基于事件应用程序的函数库。
- Spring Loaded:另一个JVM类重载代理。
- vert.x:JVM多语言事件驱动应用框架。
分布式应用
用来开发分布式、具有容错性应用程序的函数库和框架。
- Akka:构建并发、分布式和具有容错功能的事件驱动应用程序所需的工具包和运行时。
- Apache Storm:分布式实时计算系统。
- Apache ZooKeeper:为大型分布式系统,使用分布式配置、同步和命名注册提供协调服务。
- Hazelcast:分布式、高可扩展性内存网格。
- Hystrix:为分布式系统提供延迟和容错处理。
- JGroups:一组提供可靠消息传输的工具包,可用来创建集群。集群中的节点可互相发送消息。
- Quasar:为JVM提供轻量级线程和Actor。
发布
使用本机格式分发Java应用程序的工具。
- Bintray:对二进制发布进行版本控制,可与Maven或Gradle配合使用。
- IzPack:为跨平台部署建立授权工具。
- Launch4j:将JAR包装为小巧的Windows可执行文件。
- packr:将程序JAR、资源和JVM打包成Windows、Linux和Mac OS X的本机文件。
文档处理
用来处理Office格式文档的函数库。
- Apache POI:支持OOXML (XLSX、DOCX、PPTX)以及 OLE2 (XLS, DOC or PPT)格式的文档。
- jOpenDocument:处理OpenDocument格式文档。
游戏开发
游戏开发框架。
- jMonkeyEngine:支持现代3D开发的游戏引擎。
- libGDX:全面的跨平台高级开发框架。
- LWJGL:抽象了OpenGL、CL、AL等函数库的健壮框架。
GUI
用来创建现代图形用户界面的函数库。
- JavaFX:Swing的继承者。
- Scene Builder:JavaFX虚拟布局工具。
高性能
与高性能计算有关的资源,包括集合以及很多具体功能的函数库。
- Disruptor:线程间消息函数库。
- fastutil:快速紧凑的Java类型安全集合。
- GS Collections:受Smalltalk启发的集合框架。
- hftc:Hash set和hash map。
- HPPC:基本类型集合。
- Javolution:针对实时嵌入式系统的函数库。
- Trove:基本类型集合。
IDE
视图简化开发的集成开发环境。
- Eclipse:后台做了很多工作,以其丰富插件著称。
- IntelliJ IDEA:支持很多JVM语言,为Android开发提供了很多不错的选项。其商业版本主要面向企业用户。
- NetBeans:集成了很多Java SE和Java EE特性,包括数据库访问、服务器、HTML5以及AngularJS。
图像处理
用来帮助创建、评估或操作图形的函数库。
JSON
简化JSON处理的函数库。
JVM和JDK
目前的JVM、JDK实现。
日志
记录应用程序的日志函数库。
- Apache Log4j 2:对之前版本进行了完全重写。现在的版本具备一个强大的插件和配置架构。
- kibana:对日志进行分析并进行可视化。
- Logback:Log4j原班人马作品。被证明是一个强健的日志函数库,通过Groovy提供了很多有意思的配置选项。
- logstash:日志文件管理工具。
- SLF4J:日志抽象层,需要与某个具体日志框架配合使用。
机器学习
提供具体统计算法的工具。其算法可从数据中学习。
- Apache Hadoop:对商用硬件集群上大规模数据存储和处理的开源软件框架。
- Apache Mahout:专注协同过滤、聚类和分类的可扩展算法。
- Apache Spark:开源数据分析集群计算框架。
- h2o:用作大数据统计的分析引擎。
- Weka:用作数据挖掘的算法集合,包括从预处理到可视化的各个层次。
消息
在客户端之间进行消息传递,确保协议独立性的工具。
- Apache ActiveMQ:实现JMS的开源消息代理(broker),可将同步通讯转为异步通讯。
- Apache Kafka:高吞吐量分布式消息系统。
- JBoss HornetQ:清晰、准确、模块化且方便嵌入的消息工具。
- JeroMQ:ZeroMQ的纯Java实现。
其它
其它资源。
- Design Patterns:实现并解释了最常见的设计模式。
- Jimfs:内存文件系统。
- Lanterna:类似curses的简单console文本GUI函数库。
- LightAdmin:可插入式CRUD UI函数库,可用于快速应用开发。
- Metrics:创建自己的软件度量或者为支持框架添加度量信息,通过JMX或HTTP进行发布或者发送到数据库。
- OpenRefine:用来处理混乱数据的工具,包括清理、转换、使用Web Service进行扩展并将其关联到数据库。
- RoboVM:Java编写原生iOS应用。
自然语言处理
用来专门处理文本的函数库。
- Apache OpenNL:处理类似分词等常见任务的工具。
- CoreNLP:斯坦佛的CoreNLP提供了一组基础工具,可以处理类似标签、实体名识别和情感分析这样的任务。
- LingPipe:一组可以处理各种任务的工具集,支持POS标签、情感分析等。
- Mallet:统计学自然语言处理、文档分类、聚类、主题建模等。
网络
网络编程函数库。
ORM
处理对象持久化的API。
- EclipseLink:支持许多持久化标准,JPA、JAXB、JCA和SDO。
- Hibernate:广泛使用、强健的持久化框架。Hibernate的技术社区非常活跃。
- Ebean:支持快速数据访问和编码的ORM框架。
用来帮助创建PDF文件的资源。
- Apache FOP:从XSL-FO创建PDF。
- Apache PDFBox:用来创建和操作PDF的工具集。
- DynamicReports:JasperReports的精简版。
- iText:一个易于使用的PDF函数库,用来编程创建PDF文件。注意,用于商业用途时需要许可证。
- JasperReports:一个复杂的报表引擎。
REST框架
用来创建RESTful 服务的框架。
- Dropwizard:偏向于自己使用的Web框架。用来构建Web应用程序,使用了Jetty、Jackson、Jersey和Metrics。
- Jersey:JAX-RS参考实现。
- RESTEasy:经过JAX-RS规范完全认证的可移植实现。
- Retrofit:一个Java类型安全的REST客户端。
- Spark:受到Sinatra启发的Java REST框架。
- Swagger:Swagger是一个规范且完整的框架,提供描述、生产、消费和可视化RESTful Web Service。
科学
用于科学计算和分析的函数库。
- SCaVis:用于科学计算、数据分析和数据可视化环境。
搜索
文档索引引擎,用于搜索和分析。
- Apache Solr :一个完全的企业搜索引擎。为高吞吐量通信进行了优化。
- Elasticsearch:一个分布式、支持多租户(multitenant)全文本搜索引擎。提供了RESTful Web接口和无schema的JSON文档。
安全
用于处理安全、认证、授权或会话管理的函数库。
- Apache Shiro:执行认证、授权、加密和会话管理。
- Cryptomator:在云上进行客户端跨平台透明加密。
- Keycloak:为浏览器应用和RESTful Web Service集成SSO和IDM。目前还处于beta版本,但是看起来非常有前途。
- PicketLink:PicketLink是一个针对Java应用进行安全和身份认证管理的大型项目(Umbrella Project)。
- Spring Security:专注认证、授权和多维度攻击防护框架。
序列化
用来高效处理序列化的函数库。
- FlatBuffers:序列化函数库,高效利用内存,无需解包和解析即可高效访问序列化数据。
- Kryo:快速和高效的对象图形序列化框架。
- MessagePack:一种高效的二进制序列化格式。
服务器
用来部署应用程序的服务器。
- Apache Tomcat:针对Servlet和JSP的应用服务器,健壮性好且适用性强。
- Apache TomEE:Tomcat加Java EE。
- GlassFish:Java EE开源参考实现,由Oracle资助开发。
- Jetty:轻量级、小巧的应用服务器,通常会嵌入到项目中。
- WildFly:之前被称作JBoss,由Red Hat开发。支持很多Java EE功能。
模版引擎
对模板中表达式进行替换的工具。
- Apache Velocity:提供HTML页面模板、email模板和通用开源代码生成器模板。
- FreeMarker:通用模板引擎,不需要任何重量级或自己使用的依赖关系。
- Handlebars.java:使用Java编写的模板引擎,逻辑简单,支持语义扩展(semantic Mustache)。
- JavaServer Pages:通用网站模板,支持自定义标签库。
- Thymeleaf:旨在替换JSP,支持XML文件。
测试
测试内容从对象到接口,涵盖性能测试和基准测试工具。
- Apache JMeter:功能性测试和性能评测。
- Arquillian:集成测试和功能行测试平台,集成Java EE容器。
- AssertJ:支持流式断言提高测试的可读性。
- JMH:JVM微基准测试工具。
- JUnit:通用测试框架。
- Mockito:在自动化单元测试中创建测试对象,为TDD或BDD提供支持。
- Selenium:为Web应用程序提供可移植软件测试框架。
- Selenide:为Selenium提供精准的周边API,用来编写稳定且可读的UI测试。
- TestNG :测试框架。
- VisualVM:提供可视化方式查看运行中的应用程序信息。
工具类
通用工具类函数库。
- Apache Commons:提供各种用途的函数,比如配置、验证、集合、文件上传或XML处理等。
- Guava:集合、缓存、支持基本类型、并发函数库、通用注解、字符串处理、I/O等。
- javatuples:正如名字表示的那样,提供tuple支持。尽管目前tuple的概念还有留有争议。
网络爬虫
用于分析网站内容的函数库。
- Apache Nutch :可用于生产环境的高度可扩展、可伸缩的网络爬虫。
- Crawler4j:简单的轻量级爬虫。
- JSoup :刮取、解析、操作和清理HTML。
Web框架
用于处理Web应用程序不同层次间通讯的框架。
- Apache Tapestry:基于组件的框架,使用Java创建动态、强健的、高度可扩展的Web应用程序。
- Apache Wicket:基于组件的Web应用框架,与Tapestry类似带有状态显示GUI。
- Google Web Toolkit:一组Web开发工具集,包含在客户端将Java代码转为JavaScript的编译器、XML解析器、RCP API、JUnit集成、国际化支持和GUI控件。
- Grails:Groovy框架,旨在提供一个高效开发环境,使用约定而非配置、没有XML并支持混入(mixin)。
- Play: 使用约定而非配置,支持代码热加载并在浏览器中显示错误。
- PrimeFaces:JSF框架,提供免费版和带技术支持的商业版。包含一些前端组件。
- Spring Boot:微框架,简化了Spring新程序的开发过程。
- Spring:旨在简化Java EE的开发过程,提供依赖注入相关组件并支持面向切面编程。
- Vaadin:基于GWT构建的事件驱动框架。使用服务端架构,客户端使用Ajax。
- Ninja:Java全栈Web开发框架。非常稳固、快速和高效。
- Ratpack:一组Java开发函数库,用于构建快速、高效、可扩展且测试完备的HTTP应用程序。
资源
社区
活跃的讨论区。
- r/java:Java社区的Subreddit。
- stackoverflow:问答平台。
有影响的书籍
具有广泛影响且值得阅读的Java经典书籍。
播客
可以一边编程一边听的东西。
值得关注的帐号。
- Adam Bien:自由职业者、作家、JavaONE明星演讲者、顾问、Java Champion。
- Antonio Goncalves:Java Champion、JUG Leader、Devoxx France、Java EE 6/7、JCP、作家。
- Arun Gupta:Java Champion、JavaONE明星演讲者、JUG Leader、Devoxx4Kids成员、Red Hatter。
- Bruno Borges:Oracle产品经理、Java Jock。
- Ed Burns:Oracle技术团队顾问。
- Eugen Paraschiv:Spring安全课程作者。
- James Weaver:Java、JavaFX、IoT开发者、作者和演讲者。
- Java EE:Java EE Twitter官方账号。
- Java Magazine:Java杂志官方账号。
- Java.net:Java.net官方账号。
- Java:Java Twitter官方账号。
- Javin Paul:知名Java博客作者。
- Lukas Eder:Data Geekery(jOOQ)创始人兼CEO。
- Mario Fusco:RedHatter、JUG协调、活跃讲师和作者。
- Mark Reinhold:Oracle首席架构师、Java平台开发组。
- Martijn Verburg:London JUG co-leader、演讲者、作家、Java Champion等。
- OpenJDK:OpenJDK官方账号。
- Reza Rahman:Java EE、GlassFish、WebLogic传道者、作家、演讲者、开源黑客。
- Simon Maple:Java Champion、virtualJUG创始人、LJC leader、RebelLabs作者。
- Stephen Colebourne: Java Champion、演讲者。
- Tim Boudreau:作家、NetBeans大牛。
- Trisha Gee:Java Champion、演讲者。
网站
值得阅读的网站。
- Google Java Style
- InfoQ
- Java Code Geeks
- Java.net
- Javalobby
- JavaWorld
- RebelLabs
- The Java Specialist’ Newsletter
- TheServerSide.com
- Thoughts On Java
- ImportNew(ImportNew 专注 Java 技术)
参与贡献
热烈欢迎参与贡献此列表!
请参阅CONTRIBUTING加入贡献。
可能感兴趣的文章
Ernest likes this
07 Jan 11:02
2150MB/s读 1550MB/s写:三星已开始量产PCIe 3.0 SSD
还记得三星在去年的“固态硬盘全球峰会”上大秀了一把的迷你NVM Express存储装置么?现在,该公司已经开始量产这款型号为SM951的SSD了!由于采用了4x的PCIe 3.0通道,其顺序读写速度最高可以达到2150 MB/s(读)和1550 MB/s(写)。而如果在PCIe 2.0接口上使用,其峰值速度会分别降低到1600 MB/s和1350 MB/s。不过对于一款M.2 2280设备来说,其速度仍然已经相当之快。





Ernest likes this
07 Jan 09:47
如何开始参与开源项目?
by cucr
在过去五年我一直参与 Durgapur Linux用户组。我一直为各种开源项目进行贡献。我为开源贡献的主要原因是享受当你发送一个补丁或PR(pull request 提交问题)到一个开源项目的感觉。当数以百万计的人在每天的生活中使用你的一些代码时,这会让你感到幸福。
通过Google Summer of Code和 Super Student,很多人与我联系。他们都有相同的问题。
如何开始?我懂x、y、z语言。我应该对哪个项目贡献?我如何能过滤出一个bug?所以,我想写一篇博客文章来将尝试回答这些问题。但是,首先让我们了解什么是开源软件。
什么是开源软件(OSS)
开源软件是指计算机软件的源代码是公开,在各种许可证下可修改和改进分发。“What is open source?”(“开源是什么?“)是一个很好的解读。
我相信读几行代码比读500页书更值得的事实。当你追随优秀程序员编写的代码,在你编码时,你会自动倾向于使用一些很好的实践。
甚至我在大学里学软件工程课题前,我就已经实践了版本控制系统,调试器,任务跟踪,持续集成工具这些知识,这都是由于贡献了一个开源项目。
你让一个优秀的简历从人群中脱颖而出。贡献开源软件可以帮助您构建在线的形象。
但是,这些好话还不能足够帮助你开始。
我如何开始?
首先和最重要的事情是选择一个你选择的编程语言。一旦你完成了选择编程语言,寻找一个你可能会感兴趣的项目。
Open Hatch适合像你这样的初学者。Open Hatch 的搜索页面可以基于语言项目过滤bug。Mozilla也有很多基于编程语言过滤的项目, What can I do for Mozilla?(我能为Mozilla做什么)
我如何过滤出bug?
老实说,找到一个bug对于一个初学者真是一个辛苦的工作。我面临同样的问题。但我将把如何找到easy bugs(简单的缺陷)和开始为大型组织贡献列出来。
Fedora
Fedora Easy Fix page 列出了所有你可以开始的easy fixes(简单的修复)。每个项目列出了你需要联系的项目的维护者。
Fedora基础架构仓库包含一些easy fixes。在issues(任务)仓库部分寻找EasyFix标签。https://github.com/fedora-infra
Mozilla
Mozilla的开源项目非常简单。给新贡献者提供了很多的入口。
我能为mozilla做什么?
这个网站基于你选择的编程技术为你推荐项目。一旦你决定了你的项目,它会带你到相应的mozilla项目。
Bugs Ahoy网站尤其适合新的贡献者。网站基于各种项目比如JS Engine,Devtools,Firefox OS等分类成‘Easy bugs’ 和 ‘Mentored Bugs’。
但是,如果你不知道哪个项目以哪种编程语言为基础。Bugs Ahoy基于编程语言对easy bugs进行了分类,主要有Python、Java、Shell、JS、C / C++、HTML / CSS。你可以使用组合过滤来选择合适的bug来开始。
Mozilla参与页面
Mozilla对已经参与的某个团队的项目进行罗列,包含:
- 可以联系的导师。
- Bugzilla 页面
- IRC 频道名
- mentored bugs列表
- Getting Involved DevTools – https://wiki.mozilla.org/DevTools/GetInvolved
- Getting Involved Mozilla.org – https://wiki.mozilla.org/Webdev/GetInvolved/mozilla.org
- Getting Involved AMO – https://wiki.mozilla.org/Webdev/GetInvolved/addons.mozilla.org
- Getting Involved SUMO – https://wiki.mozilla.org/Webdev/GetInvolved/support.mozilla.org
- Getting Involved MDN – https://wiki.mozilla.org/Webdev/GetInvolved/developer.mozilla.org
- Getting Involved Socorro – https://wiki.mozilla.org/Webdev/GetInvolved/crash-stats.mozilla.org
- Getting Involved Mozillians – https://wiki.mozilla.org/Webdev/GetInvolved/mozillians.org
- Getting Involved ReMo – https://wiki.mozilla.org/Webdev/GetInvolved/reps.mozilla.org
- Getting Involved input.mozilla.org – https://wiki.mozilla.org/Webdev/GetInvolved/reps.mozilla.org
- Getting Involved careers.mozilla.org – https://wiki.mozilla.org/Webdev/GetInvolved/careers.mozilla.org
- Getting Involved QUMO – https://quality.mozilla.org/docs/webqa/get-involved/
- Here is another link for Bugzilla Mentored Bugs list – https://bugzil.la/sw:mentor
KDE
如果你想开始为KDE贡献,寻找 Junior Jobs(初级职位)标签。像每个组织一样,KDE也包含了如何开始KDE项目的部分。
Getting Started – http://techbase.kde.org/Contribute
入门 – http://techbase.kde.org/Contribute
Building a KDE Application – http://techbase.kde.org/Getting_Started/Build
构建KDE应用程序 – http://techbase.kde.org/Getting_Started/Build
KDE Guide for a new contributor – http://flossmanuals.net/kde-guide/
新贡献者的KDE指南 – http://flossmanuals.net/kde-guide/
IRC – #kde-devel on Freenode
IRC – #kde-devel on Freenode
Mailing List – https://mail.kde.org/mailman/listinfo/kde-devel
邮件列表 – https://mail.kde.org/mailman/listinfo/kde-devel
OpenStack
OpenStack也是一个优秀的可参与项目。OpenStack项目分为各种组件:Swift, Glance, Nova, Horizon, Keystone等。每个组件都有自己的页面。如果你去 OpenStack Wiki主页,您可以看到分别列出的组件。
每个组件页面包含到仓库的链接,bug追踪器(Launchpad),文档等。OpenStack把初学者级别bug叫做“容易摘到的果子”。
开始 – https://wiki.openstack.org/wiki/How_To_Contribute
如果你是一位开发者 – https://wiki.openstack.org/wiki/How_To_Contribute#If_you.27re_a_developer
文档- docs.openstack.org
IRC – #openstack-101, #openstack on Freenode
IRC – #openstack-101, #openstack on Freenode
寻找“容易摘到的果子” Click here!
Wikipedia
地球上的大多数人听说过维基百科这个名字,但未想过为它贡献。维基百科靠维基媒体基金会支持。Mediawiki使用简单标签标记他们的easy bugs。Click!
开始 – http://www.mediawiki.org/wiki/Gerrit/Getting_started
如何成为一个Mediawiki迷 – http://www.mediawiki.org/wiki/How_to_become_a_MediaWiki_hacker
在本地安装Mediawiki – http://www.mediawiki.org/wiki/MediaWiki-Vagrant
IRC – #mediawiki
IRC – #mediawiki
现在这个链接很重要
烦人的小bug – http://www.mediawiki.org/wiki/Annoying_little_bugs
GNOME
“Gnome-love”是标记那些初学者开始GNOME的easy bugs的可爱标签。如果你曾经访问GNOME主页:“参与”链接在头部菜单栏清晰可见。无论如何这是你不用搜索的链接:)
GNOME维护一个新手指南: https://wiki.gnome.org/NewcomersTutorial
如果你想知道如何提交你的第一个补丁,读这篇文章 :https://wiki.gnome.org/GnomeLove/SubmittingPatches
如果你想构建代码,从这里开始构建:https://wiki.gnome.org/GnomeLove/JhbuildIntroduction
文档: https://developer.gnome.org/
Apache
Apache, http://community.apache.org/newcomers/index.html
Apache维护了相当多的项目。project.apache.org列出了超过140个项目,每一个你都可以开始做贡献。新来者的部分是如何在Apache开始的简单说明,http://community.apache.org/newcomers/index.html
参与Apache软件基金会:http://www.apache.org/foundation/getinvolved.html
我是一个有几年经验的Python / Django活跃开发者。所以,我增加了如何开始为Python / Django贡献
Python
开始用Python贡献,请查看开发人员指南(http://docs.python.org/devguide/)。它首先告诉在你的系统克隆仓库,继续告诉你如何检查easy fixes。
开发人员指南提到,你如何开始做文档的修复,然后修复小bug。一旦你了解了,你可以开始对付easy bugs。
读物: http://docs.python.org/devguide/fixingissues.html
任务跟踪: http://bugs.python.org/
简单的任务: http://goo.gl/NzJuDp
Django
Django是一个基于Python的web框架,它被一些非常大的公司使用,例如Disqus,Instagram,Transifex等。如果要开始为Django贡献,请去 Contributing to Django页面。
这个页面列出了邮件列表,IRC频道,任务跟踪的链接。
参与Django: https://code.djangoproject.com/#Gettinginvolved
像大多数开源项目,Django也有针对新贡献者的easy fixes。
小且简单的改进 – https://code.djangoproject.com/wiki/LittleEasyImprovements
简单的 – https://code.djangoproject.com/query?status=!closed&easy=1
“小且简单的改进”提到的任务还有,为文档发送补丁,编写测试或者或者改善代码库。
Django维护一个建议新贡献者的页面:https://docs.djangoproject.com/en/1.6/internals/contributing/new-contributors/
开源贡献不只是强制你只为一个著名的社区做贡献。互联网上存在巨量开源项目,像Github,SourceForge,Google Code,Bitbucket等。我也确信的事实是仅仅开源贡献并不会起到帮助。一个人需要在为项目工作时让想法从他大脑中流出。
我想你会喜欢从一个不错的blog post(博文)引用的几行话:
You shouldn’t become an artist so you can be famous, but because there’s art inside of you that will kill you if you don’t let it out.
You shouldn’t found a startup to make money, but because it’s your life’s work.
And you shouldn’t hack on open source projects because someone told you that your GitHub profile is your new resume, but because you want to code socially.
你不应该为了你可以出名而成为一个艺术家,而是因为如果你不让你内在的艺术释放出来,它会杀了你。
你不应该为赚钱而开始,而是因为它是你一生的工作。
你不应该因为有人告诉你github概要就是你新的简历而深入到开源项目,而是因为你想让编程社交化。
一旦你开始贡献,你开始通过IRC,邮件列表与人交流。我强烈建议你去看看组织遵守的礼仪。通常看看这个演示文稿来得到一个简要的了解.http:/ /www.shakthimaan.com/downloads/glv/presentations/mailing-list-etiquette.pdf
即使阅读本文后,如果你遇到任何问题。可以随时在Twitter找我或给我发邮件:sayan dot chowdhury2012 @ gmail dot com。我还要感谢Chandan Kumar,他帮助我写了这篇博文,他可以通过chandankumar dot 093047 @ gmail dot com联系。
如何开始参与开源项目?,首发于博客 - 伯乐在线。
Ernest and -1 others like this
05 Jan 00:50
VPNMe 不限流量免费VPN
by Qiang Fan
德國線路 服務器地址:de1.vpnme.me 用戶名:vpnme 密碼: ItEIYy
美國線路1 服務器地址:us1.vpnme.me 用戶名:vpnme 密碼: SgIChs
美國線路2 服務器地址:us2.vpnme.me 用戶名:vpnme 密碼: 95uMT8

VPNMe特點
- 100%免費!
絕對不收費。
- 高度匿名。
無需註冊和登錄。
- 易於使用。
無需安裝(PPTP)或安裝免費的客戶端(OpenVPN的)。
- 安全連接。
強大的AES-256 加密。
- 歐盟和美國的服務器。
更多服務器即將上市。
- 適用於所有平台。
PC, Linux, Playstation 3/4, Apple 和 Android 裝置.
官方主頁:https://www.vpnme.me/
源地址:http://www.atgfw.org/2015/01/vpnme-100-vpnpptpopen-vpn.html
美國線路1 服務器地址:us1.vpnme.me 用戶名:vpnme 密碼: SgIChs
美國線路2 服務器地址:us2.vpnme.me 用戶名:vpnme 密碼: 95uMT8
VPNMe特點
- 100%免費!
絕對不收費。
- 高度匿名。
無需註冊和登錄。
- 易於使用。
無需安裝(PPTP)或安裝免費的客戶端(OpenVPN的)。
- 安全連接。
強大的AES-256 加密。
- 歐盟和美國的服務器。
更多服務器即將上市。
- 適用於所有平台。
PC, Linux, Playstation 3/4, Apple 和 Android 裝置.
官方主頁:https://www.vpnme.me/
源地址:http://www.atgfw.org/2015/01/vpnme-100-vpnpptpopen-vpn.html
翻墙技术博客订阅地址及社交帐号
Ernest likes this
05 Jan 00:49
操作系统中进程简介
by 进林
操作系统:进程介绍
很久前我就想写这篇文章了,但总是以各种理由来拖延。操作系统是我日常工作的主要部分,特别是GNU/Linux,这篇文章主要关注GUN/Linux。
进程是个大话题,我不确定如何才能覆盖进程的所有知识点。这篇文章将会包含足够多的代码让你学会如何与进程交互。这些代码例子将会侧重于GNU/Linux系统,因为这是我最熟悉的系统。
那么,什么是进程呢?Linux信息项目(The Linux Information)把进程定义为“程序的一个执行(即,运行)实例”。所以,要定义进程我们先要定义什么是程序。再次根据Linux信息项目里的定义,“程序是内存里的一个可执行文件。”
所以,我们知道进程是正在运行的程序的一部分。这是否意味着进程一定是在运行中的?不一定。
进程状态
为了弄明白正在运行的进程是什么意思,我们需要知道进程的不同状态。一个进程可以有几个状态(在Linux内核里,进程有时候也叫做任务)。
下面的状态在 fs/proc/array.c 文件里定义:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
运行状态(running)并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。睡眠状态(sleeping)意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(interruptible sleep))。磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待IO的结束。
可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
例如,可以用下面的方法来停止或继续运行进程:
kill -SIGSTOP <pid> kill -SIGCONT <pid>
可以使用gdb终止进程来实现跟踪终止状态。如果我没有记错的话,这个状态和终止状态基本上是一样的。
死亡状态是内核运行 kernel/exit.c 里的 do_exit() 函数返回的状态。这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
僵死状态(Zombies)是一个比较特殊的状态。有些人认为这个状态是在父进程死亡而子进程存活时产生的。实际上不是这样的。父进程可能已经死了但子进程依然存活着,那个子进程的父进程将会成为init进程,pid 1。当进程退出并且父进程(使用wait()系统调用)没有读取到子进程退出的返回代码时就会产生僵死进程。僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。
这里有一个创建维持30秒的僵死进程例子:
#include <stdio.h>
#include <stdlib.h>
/*
* A program to create a 30s zombie
* The parent spawns a process that isn't reaped until after 30s.
* The process will be reaped after the parent is done with sleep.
*/
int main(int argc, char **argv[])
{
int id = fork();
if ( id > 0 ) {
printf("Parent is sleeping..n");
sleep(30);
}
if ( id == 0 )
printf("Child process is done.n");
exit(EXIT_SUCCESS);
}
Linux进程状态是一篇非常棒的文章,它使用代码例子来讲述进程状态并使用 ptrace 来控制它。
进程包含了什么信息?
我简要地提过进程表,我将会在这解释什么是进程表。进程表是Linux内核的一种数据结构,它会被装载到RAM里并且包含着进程的信息。
每个进程都把它的信息放在 task_struct 这个数据结构里,task_struct 包含了这些内容:
- 状态(任务状态,退出代码,退出信号。。。)
- 优先级
- 进程id(PID)
- 父进程id(PPID)
- 子进程
- 使用情况(cpu时间,打开的文件。。。)
- 跟踪信息
- 调度信息
- 内存管理信息
保存进程信息的数据结构叫做 task_struct,并且可以在 include/linux/sched.h 里找到它。所有运行在系统里的进程都以 task_struct 链表的形式存在内核里。
进程的信息可以通过 /proc 系统文件夹查看。要获取PID为400的进程信息,你需要查看 /proc/400 这个文件夹。大多数进程信息同样可以使用top和ps这些用户级工具来获取。
进程执行
当进程执行时,它会被装载进虚拟内存,为程序变量分配空间,并把相关信息添到task_struct里。
进程内存布局分为四个不同的段:
- 文本段,包含程序的源指令。
- 数据段,包含了静态变量。
- 堆,动态内存分区区域。
- 栈,动态增长与收缩的段,保存本地变量。
这里有两种创建进程的方法,fork()和execve()。它们都是系统调用,但它们的运行方式有点不同。
要创建一个子进程可以执行fork()系统调用。然后子进程会得到父进程中数据段,栈段和堆区域的一份拷贝。子进程独立可以修改这些内存段。但是文本段是父进程和子进程共享的内存段,不能被子进程修改。
如果使用execve()创建一个新进程。这个系统调用会销毁所有的内存段去重新创建一个新的内存段。然而,execve()需要一个可执行文件或者脚本作为参数,这和fork()有所不同。
注意,execve()和fork()创建的进程都是运行进程的子进程。
进程执行还有很多其他的内容,比如进程调度,权限许可,资源限制,库链接,内存映射… 然而这篇文章由于篇幅限制不可能都讲述,以后访问可能会加上
进程间通信(IPC)
为了进程间的通信,存在两个解决方法,共享内存,消息传递。
在共享内存的方案里,为了几个进程间能够通信创建了一个共享的区域。这个区域能被多个进程同时访问。这种方法通常在使用线程时使用。这是实现IPC最快的形式,因为这种形式只涉及到内存的读写。 但是,这需要进程在访问共享内存时受到的限制和访问内核实现的其他进程内存一样。
共享内存段的使用情况可以使用ipcs -m命令查看。
实现一个共享内存的服务器程序,代码如下:
#include <stdlib.h>
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define SEGMENT_SIZE 64
int main(int argc, char **argv[])
{
int shmid;
char *shmaddr;
/* Create or get the shared memory segment */
if ((shmid = shmget(555, SEGMENT_SIZE, 0644 | IPC_CREAT)) == -1) {
printf("Error: Could not get memory segmentn");
exit(EXIT_FAILURE);
}
/* Attach to the shared memory segment */
if ((shmaddr = shmat(shmid, NULL, 0)) == (char *) -1) {
printf("Error: Could not attach to memory segmentn");
exit(EXIT_FAILURE);
}
/* Write a character to the shared memory segment */
*shmaddr = 'a';
/* Detach the shared memory segment */
if (shmdt(shmaddr) == -1) {
printf("Error: Could not close memory segmentn");
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
通过把 *shmaddr = ‘a’; 替换为 printf(“Segment: %sn”, shmaddr) ,你将会得到一个客户端程序并且能够读取共享内存段的数据。
运行 ipcs -m 将会输出服务共享内存段的信息:
anton@shell:~$ ipcs -m ------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x0000022b 0 anton 644 64 0
共享内存段可以使用 ipcrm 命令移除。要了解更多的共享内存实现IPC,可以阅读Beej的共享内存段教程。
其他实现IPC的方法有文件,信号,套接字,消息队列,管道,信号灯和消息传递。这些方法我不可能全部都深入讲解,但我觉得信号和管道的方法我需要提供一些有趣的例子。
信号
介绍进程状态时,我们已经看了一个使用kill命令的信号示例。信号是把事件或者异常的发生通知进程的软件中断。
每个信号都有一个整型标识,但通常使用 SIGXXX 来描述信号,例如 SIGSTOP 或者 SIGCONT 。内核使用信号来通知进程事件的发生,进程也可以使用kill()系统调用发送信号给进程。接收信号的进程可以忽略信号,被杀死,或者被挂起。可以使用信号处理器来处理信号并且在信号出现时任意处理信号。SIGKILL 这个特殊的信号不能被捕获(处理器处理),要杀死一个挂起的进程时可以使用这个信号。不要把 SIGKILL 和 SIGTERM 混淆了,当使用 Ctrl+C 或者 kill <PID> 杀死进程时默认会发送 SIGKILL 信号。 SIGTERM 不会强制杀死进程并且它可以被捕获,使用 SIGTERM 的进程通常可以被清理。
管道
管道用来把一个进程的输出连接到另外一个进程的输入。这是实现IPC最古老的方法之一。普通管道是单向通信的, 它有一个单向流。可以使用pipe() 创建一个管道,管道和Linux的其他对象一样,都被看成文件对象。
通其他文件一样,read()和write()操作都适用于管道。
命名管道是普通管道的增强版,它是双向通信的并且可以实现管道的多进程读写。这都是普通管道不能实现的。无论有没有进程对命名管道进行读写,它都会实际存在。命名管道在文件系统里以特殊设备文件存在。在GNU/Linux里,命名管道也被称为FIFOs(先进先出,First In First Out)。
这里有一个创建命名管道的例子:
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
int main(int argc, char **argv[])
{
if (mknod("myfifo", S_IFIFO|0666, 0) == -1) {
printf("Failed to mknodn");
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
在运行目录里,我们会看到myfifo文件。它的信息和下面的类似:
prw-rw-r-- 1 anton anton 0 Dec 16 16:14 myfifo
以上就是进程的基本介绍。写得越多我就越意识到进程有太多东西要讲了。从哪里开始讲进程和把不需要覆盖的知识划分出来,这是个很艰难的决定。共享内存段是我没有很好地规划好的一部分。回看进程间通信那部分是很有趣的。此外,因为有大量诸如Linux编程接口和操作系统概念的好资源,使我们更容易回归概念思考。
参考
下面的资源用来加深对这个领域知识的理解。如果你想学习关于操作系统的更多内容,一定要看看这些书,虽然书很厚但是值得你阅读。
Ernest likes this