Während sich Berlin und Brüssel um Fake News und Social Bots sorgen und der Spiegel in seinen Reihen einen verwirrten Einzelfaker aufspürt, spielt sich vor unseren Augen die größte Fake-News-Krise des frühen 21. Jahrhunderts ab: die Legende von der wunderbaren Blockchain-Technologie, die alles revolutioniere. Entstanden als Behauptung windiger Geschäftemacher, schaffte sie es mittlerweile in Zeitungsartikel, auf Wahlplakate, in Koalitionsverträge sowie ins Abendprogramm der ARD. Treiber dieser memetischen Krise sind nicht die üblichen Verdächtigen – Putins Trollarmeen, horizontbeschränkte Wutbürger und Protonazis sowie Facebook, Twitter und Google – sondern gesellschaftliche Systeme, die emergent-kollektiver Bullshitterei zunehmend wehrlos gegenüberstehen.

Banale Technik
Die Blockchain gibt es tatsächlich. Sie ist allerdings keine Technologie, sondern eine IT-Architektur. Ausgangspunkt war das virtuelle Spekulationsgut Bitcoin, das auf dem Finanzmarkt gerade eine Wertberichtigung erfährt. Da sich Zufallszahlen auch mit einer guten Geschichte kaum verkaufen lassen, kombinierte Bitcoin kreativ mehrere Entwurfsmuster: (1) eine Protokolldatei aus kryptografisch verketteten Einträgen, so dass Manipulationen erkennbar werden und nur das Anhängen neuer Einträge zulässig ist, (2) die redundante Speicherung dieser Datei bei jedem Teilnehmer, (3) ein Verfahren zur (technischen) Konsensbildung darüber, welche Inhalte in welcher Reihenfolge an die Datei angehängt werden, (4) künstlich erzeugten Rechenaufwand als Voraussetzung für die Teilnahme, um Manipulationen der Konsensbildung zu verteuern, sowie (5) eine Lotterie, welche die Teilnahme an der Konsensbildung gelegentlich belohnt.
Im Wesentlichen handelt es sich bei einer Blockchain um eine Protokolldatei mit kryptografischer Integritätssicherung. Die übrigen Elemente benötigt man nur deshalb, weil man diese Protokolldatei nicht in der üblichen Weise zentral auf einem Server im Internet führt, sondern – ohne erkennbare technische Motivation – auf eine solche Instanz verzichten möchte. Später kam die Idee der „Smart Contracts” hinzu. Das sind Programme, die mit Protokolleinträgen als Ein- und Ausgaben arbeiten und selbst protokolliert sind.
Kein plausibler Nutzen
Ein Protokollierungsmechanismus, der aufgrund willkürlicher Entwurfsentscheidungen unnötig ineffizient ist, soll also die Cyberdigitalisierung revolutionieren und Krebs heilen. Wirklich Neues jedoch kann man damit gar nicht anfangen. Verlässliche Protokolle kennt die Menschheit, seit die ersten Hieroglyphen in Ton geritzt wurden. Auch Erzählungen von Smart Contracts wirken nur noch halb so beeindruckend, wenn man erst einmal das kontaktlose Bezahlen mit Karte oder Telefon ausprobiert hat. Viel smarter als eine Kreditkarte mit Chip werden Verträge in diesem Leben voraussichtlich nicht mehr
Dass es in der Praxis zudem eher auf Pragmatik ankommt als auf starke Kryptografie, konnten wir gerade in Deutschland mehrfach schmerzhaft lernen, etwa angesichts des einst in seiner Bedeutung hoffnungslos überschätzten Signaturgesetzes oder der Investitionsruine eGK. Unterdessen kaufen wir seit inzwischen Jahrzehnten alles Mögliche im Netz ein und das funktioniert prima ohne ein zentrales Transaktionsregister.
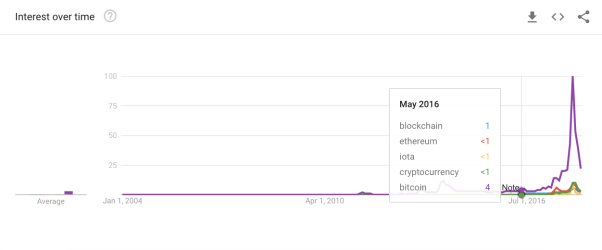
Dementsprechend vage bleiben die Verheißungen der wunderbaren Blockchain-Technologie durch sämtliche Nachrichten hinweg. Zwar betonen alle, welch eine Revolution sich gerade vollziehe, doch der Aufforderung: „Show, don’t tell“ folgt niemand. Erfolgreiche Projekte findet man nicht einmal, wenn man sie aktiv sucht und als mögliche künftige Anwendungen werden wie im Bildschirmfoto oben vor allem solche aufgezählt, die es längst gibt, nur eben funktionierend statt mit Blockchain. Da hilft auch die Umbenennung in Distributed Ledger Technology nicht.
Das konnte man alles sehen und wissen, schon lange, wenn man ab und zu nach Antworten auf naheliegende Fragen gesucht hat: Wie soll das funktionieren? Hat das mal jemand ausprobiert? Wie hat man das Problem bisher gelöst? Was wird besser, was schlechter, wenn man eine Blockchain-Lösung baut? Handelt es sich überhaupt um ein Problem, für dessen Lösung jemand Geld ausgeben würde? Viele haben es auch gesehen und gewusst und die Blockchain-Promoter belächelt, seit Jahren schon, denn überzeugende Details enthielt die Geschichte nie, dafür viele phantasievolle Ausschmückungen des immergleichen Grundgerüsts, und zuletzt sprachen auch harte Daten gegen die Vermutung eines echten Technologietrends.
Bullshitblase
Gescheitert sind an der Legende von der Blockchain jedoch gesellschaftliche Teilsysteme, denen die Einschätzung von Wahrheit und Relevanz obliegt: die Medien, die Wissenschaft und in der Folge auch die Politik. Eine lose Allianz aus Geschäftemachern, Konzernen, Wissenschaftlern und Wissenschaftsorganisationen sowie Journalisten bildet eine Blökchain, in der alle einander auf die Schulter klopfen und versichern, wie prächtig und revolutionär des Kaisers neue Blockchain sei – während ringsum alles in Chor ruft, da sei nicht mal ein nackter Kaiser.

Als schwarze Schafe, welche die Legende in die Welt setzten, fungierte zum einen die ICO-Szene, zum anderen Konzerne mit Innovationsdefiziten. Die ICO-Szene entwickelte sich aus der Erkenntnis, dass sich das Bitcoin-Modell beliebig vervielfältigen lässt, und der Idee, solche Kopien herzustellen und aus diesem Anlass „Token“ an risikobereite Investoren zu verkaufen. Im Gegensatz zum oberflächlich ähnlichen IPO eines Startups erwerben die Investoren dabei keine Unternehmensanteile, sondern sie investieren lediglich in die Hoffnung, jemand könne ihnen in Zukunft ihre Token abkaufen, warum auch immer, und dafür einen höheren als den ursprünglichen Preis zahlen.
Gleichzeitig sahen einige Konzerne eine Gelegenheit, sich innovativ zu geben und ihren an sich langweiligen und schwer unterscheidbaren Produkten und Dienstleistungen Alleinstellungsmerkmale anzudichten – eben die Blockchain-Technologie, welche danke Bitcoin-Blase und ICO-Meldungen im Gespräch war. Das ist nicht ungewöhnlich; man denke etwa an die Second-Life-Blase vor etwas mehr als zehn Jahren mit ähnlichem Verhalten teils derselben Akteure. Wenn ein Konzern laut darüber redet, so etwas zu tun, dann sind Nachahmer nicht weit, und so behaupten heute viele alte Unternehmen, irgendwas mit Blockchain zu tun. Zugute kommt ihnen dabei der Blökchain-Mechanismus – sie müssen nur in den Chor derer einstimmen, die von der goldenen Blockchain-Zukufnft schwärmen, und sie sind in diesem Chor herzlich willkommen.
Überforderte Institutionen
Bis hierhin handelt es sich um legitime Spekulation und PR im eigenen Interesse, um ganz normalen Kapitalismus, der bestimmungsgemäß funktioniert. Normalerweise stehen diesen Akteuren und ihrem Handeln jedoch als Korrektiv Systeme mit Objektivitätsanspruch gegenüber, etwa die Medien und die Wissenschaft. Diese Systeme sind bislang allen offensichtlichen Zeichen zum Trotz an der Legende von der Blockchain-Revolution gescheitert.
Für die Medien ist die Geschichte von der Blockchain ein gefundenes Fressen. Medien mögen Geschichten, selbst wenn sie falsch sind. Gleichzeitig steckt die Presse seit Jahren in der Krise, ihre Auflagen sinken ebenso wie die Werbeeinnahmen und vom einstigen Geschäft mit den Kleinanzeigen sind höchstens noch die Trauerfälle in der längst woanders produzierten Lokalzeitung übrig. Ein Thema ernsthaft und kritisch zu recherchieren, auch wenn keine spektakuläre Enthüllung als Belohnung winkt, kann man sich kaum noch leisten. Recherchiert man weniger gründlich, verfängt man sich jedoch fast zwangsläufig in der Blökchain. Die sichtbarsten und zugänglichsten Experten sind dann jene, auf deren Agenda die Blockchain-Promotion steht und sie verbreiten selbstverständlich ihre Legende.
Ist dies oft genug geschehen, wird die Politik aufmerksam. Was es mit einem Schlagwort wirklich auf sich hat, interessiert dort erst einmal weniger, solange es als Code für Fortschritt und Modernität oder sonst irgendeinen ätherischen Wert brauchbar scheint. So landete die Blockchain erst in den Wahlkämpfen der FDP und alsbald auch im Koalitionsvertrag der aktuellen GroKo. Das nationale und kontinentale Trauma, in der IT- und Internetwirtschaft hoffnungslos den Anschluss verloren und sich stattdessen in Datenschutz-, Ethik- und Sicherheitsdebatten verzettelt zu haben, bereitet inzwischen reale Schmerzen. Man sucht händeringend nach dem Next Big Thing , bei dem man endlich mal die Nase vorn haben möchte, und läuft deshalb jedem sich abzeichnenden Trend hinterher. So wandert die Legende weiter in die real existierende Forschungsförderung. Ähnliches spielt sich auf europäischer Ebene ab.
, bei dem man endlich mal die Nase vorn haben möchte, und läuft deshalb jedem sich abzeichnenden Trend hinterher. So wandert die Legende weiter in die real existierende Forschungsförderung. Ähnliches spielt sich auf europäischer Ebene ab.
Dies wiederum führt die Wissenschaft an die Blökchain heran. Was mancher noch für eine hehre Wahrheitssuche hält, ist über weite Strecken längst zu einem Geschäft geworden, in dem jene als die Erfolgreichsten gelten, welche die höchsten Fördersummen akquirieren und verbrauchen. Von dort ist folglich zur Blockchain-Legende kaum ein kritisches Wort zu hören, solange man mit Fördermitteln für dieses Thema rechnet. Im Gegenteil, seit sich der Thementrend abzeichnet, produziert man eilig Thesenpapiere, Experten und Labore, um sich für den Kampf ums Geld in Position zu bringen und so auszusehen, als hätte man die Blockchain beinahe miterfunden. So stimmen Wissenschaftler und Funktionäre in den Chor ein, der von einer goldenen Blockchain-Zukunft schwärmt, denn alles andere wäre sehr dumm, wenn Geld für Blockchain-Projekte winkt.
Was nun?
So hat sich quer durch die Gesellschaft eine Blase gebildet, in der die Legende von der wunderbaren, alles revolutionierenden Blockchain-Technologie durch wechselseitige Bestätigung und Bekräftigung am Leben erhalten wird, während man sich gegen Kritik und Zweifel durch Ausschluss der Kritiker immunisiert. Schuld daran sind weder Putins Trollarmeen noch die bösen Internetplattformen, sondern die Verhältnisse in wichtigen Teilsystemen unserer Gesellschaft sowie deren Zusammenwirken. Wo alle einander nachhaltig dieselbe offensichtlich halbwahre Geschichte nacherzählen, fehlt es an öffentlichem Widerspruch und mithin an Pluralismus.
Von ihrem gegenwärtigen Leitthema wird sich diese Fake-News-Blase bald verabschieden, weil es darüber kaum noch Neues zu erzählen gibt und sich die alte Legende abnutzt, wenn vorzeigbare Erfolge weiter ausbleiben. Doch die Strukturen und Mechanismen dahinter werden bleiben und sie werden neue Themen finden, mit denen sie uns ebenso lange und intensiv auf die Nerven gehen werden. Wir müssen uns deshalb fragen, mit welchen Mitteln wir künftig Nachrichten, Weltbilder und Kritik produzieren möchten und was wir ungenierter Bullshitterei entgegensetzen können.
Ein Hoffnungsschimmer
Andererseits sehe ich nicht so schwarz, wie es hier im Text vielleicht scheint, sondern ich glaube daran, dass sich die Wahrheit auf lange Sicht doch durchsetzt. Gegenwärtig kommt ein Hauch von Realismus in der Berichterstattung an und wenn das Rückzugsgefecht so weitergeht, lassen wir das Thema Blockchain vielleicht bald hinter uns. Es wird auch Zeit.


















 Chris ist auch ein aktiver Twitterer (@chris_pyak), was mir immer wieder eine große Freude ist. Vor einiger Zeit hat er mich für seinen
Chris ist auch ein aktiver Twitterer (@chris_pyak), was mir immer wieder eine große Freude ist. Vor einiger Zeit hat er mich für seinen 
 . The bias I can see is the following: I’ve collected all the job offers that one individual has received in the past two years while identifying as Sr. Application Security Engineer on a popular social media platform that is the hunting ground for recruiters. It is not representative of the industry at wide at all, but rather a view of what someone would attract in a specific geographical region. What I like about that bias, is that it expresses a consensus of people looking for the same thing, so really pin pointed at what I want to explicit in this post.
. The bias I can see is the following: I’ve collected all the job offers that one individual has received in the past two years while identifying as Sr. Application Security Engineer on a popular social media platform that is the hunting ground for recruiters. It is not representative of the industry at wide at all, but rather a view of what someone would attract in a specific geographical region. What I like about that bias, is that it expresses a consensus of people looking for the same thing, so really pin pointed at what I want to explicit in this post.










{kind=link}