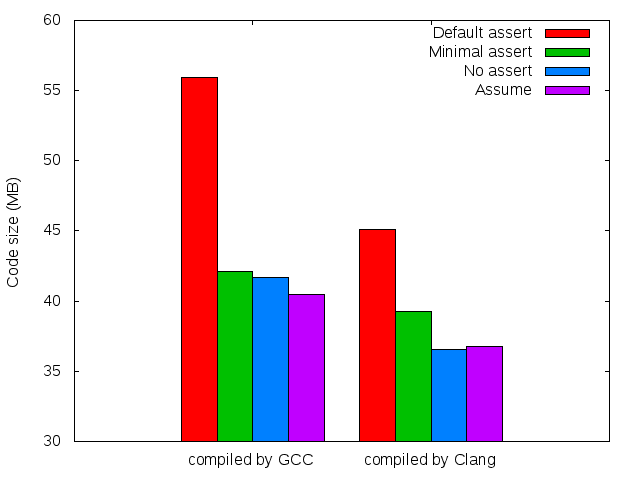
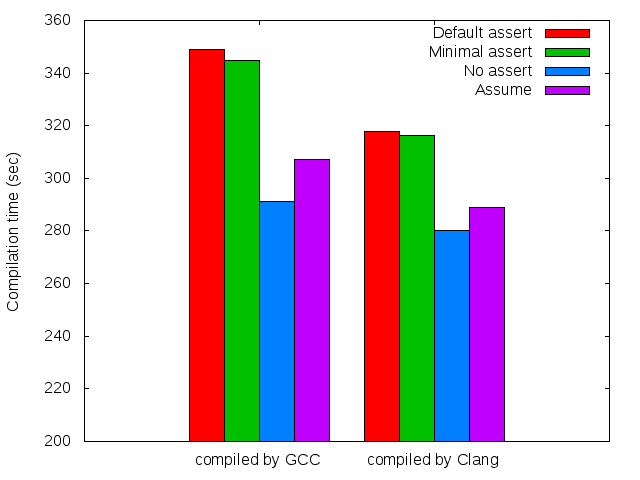
With each new release, gcc and clang add on more C++11 and C++14 features. While clang has been behind on some features, though ahead on others, they now claim to have
C++1y all worked out.
This article is not comprehensive.
Clang's 3.4 C++ release notes:
http://llvm.org/releases/3.4/tools/clang/docs/ReleaseNotes.html#id1
libc++'s C++1y status:
http://libcxx.llvm.org/cxx1y_status.html
Note: To compile these examples requires the flags, "-stdlib=libc++" and "-std=c++1y".
Variable templates.
This feature, from
N3651, took me most be surprise, but it also seems quite obvious. In the simplest example, let
def<T> be a variable that represents the default-constructed value of any type,
T.
template<typename T>
constexpr T def = T();
auto x = def<int>; // x = int()
auto y = def<char>; // y = char()
The proposal uses the example of
pi, where it may be more useful to store it as a
float or
double, or even
long double. By defining it as a template, one can have precision when needed and faster, but less precise, operations otherwise.
For another example, consider storing a few prime numbers, but not specifying the type of their container.
template<template<typename...> class Seq>
Seq<int> primes = { 1, 2, 3, 5, 7, 11, 13, 17, 19 };
auto vec = primes<std::vector>;
auto list = primes<std::list>;
(gist)
Also, the standard library contains many template meta-functions, some with a static
value member. Variable templates help there, too.
template<typename T, typename U>
constexpr bool is_same = std::is_same<T,U>::value;
bool t = is_same<int,int>; // true
bool f = is_same<int,float>; // false
(std::is_same)
But since variable templates can be specialized just like template functions, it makes as much sense to define it this way:
template<typename T, typename U>
constexpr bool is_same = false;
template<typename T>
constexpr bool is_same<T,T> = true;
(gist)
Except for when one requires that
is_same refers to an
integral_constant.
One thing worries me about this feature: How do we tell the difference between template meta-functions, template functions, template function objects, and variable templates? What naming conventions will be invented? Consider the above definition of
is_same and the fallowing:
// A template lambda that looks like a template function.
template<typename T>
auto f = [](T t){ ... };
// A template meta-function that might be better as a variable template.
template<typename T>
struct Func : { using value = ...; };
They each has subtly different syntaxes. For example,
N3545 adds an
operator() overload to
std::integral_constant which enables syntax like this:
bool b = std::is_same<T,U>(), while
N3655 adds
std::is_same_t<T,U> as a synonym for
std::is_same<T,U>::value.
(Note: libc++ is missing std::is_same_t.) Even without variable templates, we have now three ways to refer to the same thing.
Finally, one problem I did have with it is I wrote a function like so:
template<typename T>
auto area( T r ) {
return pi<T> * r * r;
};
and found that clang thought
pi<T> was undefined at link time and clang's diagnostics did little to point that out.
/tmp/main-3487e1.o: In function `auto $_1::operator()<Circle<double> >(Circle<double>) const':
main.cpp:(.text+0x5e3d): undefined reference to `_ZL2piIdE'
clang: error: linker command failed with exit code 1 (use -v to see invocation
I solved this by explicitly instantiating
pi for the types I needed by adding this to
main:
pi<float>;
pi<double>;
Why in
main and not in global scope? When I tried it right below the definition of
pi, clang thought I wanted to specialize the type. Finally, attempting
template<> pi<float>; left the value uninitialized. This is a
bug in clang, and has been fixed. Until the next release, variable templates work as long as only non-template functions refer to them.
Generic lambdas and generalized capture.
Hey, didn't I already do
an article about this? Well, that one covers Faisal Vali's
fork of clang based off of the
N3418, which has many more features than this iteration based off the more conservative
N3559. Unfortunately it lacks the terseness and explicit template syntax (i.e.
[]<class T>(T t) f(t)), but it maintains
automatic types for parameters (
[](auto t){return f(t);}).
Defining lambdas as variable templates helps, but variable templates lack the abilities of functions, like implicit template parameters. For the situations where that may be helpful, it's there.
template<typename T>
auto convert = [](const auto& x) {
return T(x);
};
(gist)
Also, previously, clang couldn't capture values by move or forward into lambdas, which prohibited capturing move-only types by anything other than a reference. Transitively, that meant many perfect forwarding functions couldn't return lambdas.
Now, initialization is "general", to some degree.
std::unique_ptr<int> p = std::make_unique<int>(5);
auto add_p = [p=std::move(p)](int x){ return x + *p; };
std::cout << "5 + 5 = " << add_p(5) << std::endl;
(See also: std::make_unique)
Values can also be copied into a lambda using this syntax, but check out Scott Meyer's article for why
[x] or
[=] does not mean the same thing as
[x=x] for
mutable lambdas. (
http://scottmeyers.blogspot.de/2014/02/capture-quirk-in-c14.html)
Values can also be defined and initialized in the capture expression.
std::vector<int> nums{ 5, 6, 7, 2, 9, 1 };
auto count = [i=0]( auto seq ) mutable {
for( const auto& e : seq )
i++; // Would error without "mutable".
return i;
};
gcc has had at least partial support for this since 4.5, but should fully support it in 4.9.
Auto function return types.
This is also a feature gcc has had since 4.8 (
and I wrote about, as well), but that was based off of
N3386, whereas gcc 4.9 and clang 3.4 base off of
N3638. I will not say much here because this is not an entirely new feature, not much has changed, and it's easy to groc.
Most notably, the syntax,
decltype(auto), has been added to overcome some of the shortcomings of
auto. For example, if we try to write a function that returns a reference with
auto, a value is returned. But if we write it...
decltype(auto) ref(int& x) {
return x;
}
decltype(auto) copy(int x) {
return x;
}
(gist)
Then a reference is returned when a is given, and a copy when a value is given. (Alternatively, the return type of
ref could be
auto&.)
More generalized constexprs.
The requirement that
constexprs be single return statements worked well enough, but simple functions that required more than one line could not be
constexpr. It sometimes forced inefficient implementations in order to have at least some of its results generated at compile-time, but not always all. The factorial function serves as a good example.
constexpr unsigned long long fact( unsigned long long x ) {
return x <= 1 ? 1ull : x * fact(x-1);
}
but now we can write...
constexpr auto fact2( unsigned long long x ) {
auto product = x;
while( --x ) // Branching.
product *= x; // Variable mutation.
return product;
}
(gist)
This version may be more efficient, both at compile time and run time.
The accompanying release of libc++ now labels many standard functions as constexpr thanks to
N3469 (chrono),
3470 (containers),
3471 (utility),
3302 (std::complex), and
3789 (functional).
Note: gcc 4.9 does not yet implement branching and mutation in constexprs, but does include some of the library enhancements.
Although this library addition may not be of use to everyone, anyone who has attempted to unpack a tuple into a function (like
this guy or
that guy or
this one or ...) will appreciate
N3658 for "compile-time integer sequences". Thus far, no standard solution has existed. N3658 adds one template class,
std::integer_sequence<T,t0,t1,...,tn>, and
std::index_sequence<t0,...,tn>, which is an
integer_sequence with
T=size_t. This lets us write an
apply_tuple function like so:
template<typename F, typename Tup, size_t ...I>
auto apply_tuple( F&& f, Tup&& t, std::index_sequence<I...> ) {
return std::forward<F>(f) (
std::get<I>( std::forward<Tup>(t) )...
);
}
(See also: std::get)
For those who have not seen a function like this, the point of this function is just to capture the indexes from the
index_sequence and call
std::get variadically. It requires another function to create the
index_sequence.
N3658 also supplies
std::make_integer_sequence<T,N>, which expands to
std::integer_sequence<T,0,1,...,N-1>,
std::make_index_sequence<N>, and
std::index_sequence_for<T...>, which expands to
std::make_index_sequence<sizeof...(T)>.
// The auto return type especially helps here.
template<typename F, typename Tup >
auto apply_tuple( F&& f, Tup&& t ) {
using T = std::decay_t<Tup>; // Thanks, N3655, for decay_t.
constexpr auto size = std::tuple_size<T>(); // N3545 for the use of operator().
using indicies = std::make_index_sequence<size>;
return apply_tuple( std::forward<F>(f), std::forward<Tup>(t), indicies() );
}
(See also: std::decay, std::tuple_size, gist)
Unfortunately, even though the proposal uses a similar function as an example, there still exists no standard
apply_tuple function, nor a standard way to extract an
index_sequence from a
tuple. Still, there may exist several conventions for applying
tuples. For example, the function may be the first element or an outside component. The tuple may have an incomplete argument set and require additional arguments for
apply_tuple to work.
Update: Two library proposals in the works address this issue:
N3802 (apply), and
N3416 (language extension: parameter packs).
experimental::optional.
While not accepted into C++14, libc++ has an implementation of
N3672's
optional hidden away in the
experimental folder. Boost fans may think of it as the standard's answer to
boost::optional as functional programers may think of it as like
Haskell's Maybe.
Basically, some operations may not have a value to return. For example
, a square root cannot be taken from a negative number, so one might want to write a "safe" square root function that returned a value only when
x>0.
#include <experimental/optional>
template<typename T>
using optional = std::experimental::optional<T>;
optional<float> square_root( float x ) {
return x > 0 ? std::sqrt(x) : optional<float>();
}
(gist)
Using an
optional is simple because they implicitly convert to bools and act like a pointer, but with value semantics (which is incidentally how libc++ implements it). Without
optional, one might use a
unique_ptr, but value semantics on initialization and assignment make
optional more convenient.
auto qroot( float a, float b, float c )
-> optional< std::tuple<float,float> >
{
// Optionals implicitly convert to bools.
if( auto root = square_root(b*b - 4*a*c) ) {
float x1 = -b + *root / (2*a);
float x2 = -b - *root / (2*a);
return {{ x1, x2 }}; // Like optional{tuple{}}.
}
return {}; // An empty optional.
}
(gist)
Misc. improvements.
This version of libc++ allows one to retrieve a
tuple's elements by type using
std::get<T>.
std::tuple<int,char> t1{1,'a'};
std::tuple<int,int> t2{1,2};
int x = std::get<int>(t1); // Fine.
int y = std::get<int>(t2); // Error, t2 contains two ints.
Clang now allows the use of single-quotes (') to separate digits.
1'000'000 becomes 1000000, and
1'0'0 becomes 100.
(example) (It doesn't require that the separations make sense, but one cannot write
1''0 or
'10.)
libc++ implements
N3655, which adds several template aliases in the form of
std::*_t = std::*::type to
<type_traits>, such as
std::result_of_t,
std::is_integral_t, and many more. Unfortunately, while N3655 also adds
std::is_same_t (see the top of the 7th page), libc++ does not define it. I do not know, but I believe this may be an oversight that will be fixed soon as it requires only one line.
N3421 adds specializations to the members of
<functional>. If one wanted to send an addition function into another functions, one might write
f(std::plus<int>(),args...), but we new longer need to specify the type and can instead write
std::plus<>(). This instantiates a function object that can accept two values of any type to add them. Similarly,
std::greater<>,
std::less<>,
std::equal_to<>, etc...
Conclusions.
This may not be the
most ground-breaking release, but C++14 expands on the concepts from C++11, improves the library, and adds a few missing features, and I find it impressive that the clang team has achieved this so preemptively. I selected to talk about the features I thought were most interesting, but I did not talk about, for example,
sized deallocation,
std::dynarray (
<experimental/dynarry>), some
additional overloads in <algorithm>, or
Null Forward Iterators, to name a few. See the bottom for links to the full lists.
The GNU team still needs to do more work to catch up to clang. If one wanted to write code for both gcc 4.9 and clang 3.4, they could use generic lambdas,
auto for return types, but not variable templates or generalized
constexprs. For the library, gcc 4.9 includes
std::make_unique (as did 4.8), the N3412 specializations in
<functional>, integer sequences,
constexpr library improvements, even
experimental::optional (though I'm not sure where), and much more. It may be worth noting it does not seem to include the
<type_traits> template aliases, like
result_of_t.
See clang's full release notes related to C++14 here:
http://llvm.org/releases/3.4/tools/clang/docs/ReleaseNotes.html#id1
For libc++'s improvements, see:
http://libcxx.llvm.org/cxx1y_status.html
gcc 4.9's C++14 features:
http://gcc.gnu.org/projects/cxx1y.html
And gcc's libstdc++ improvements:
http://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html#status.iso.2014
The code I wrote to test these features:
https://gist.github.com/splinterofchaos/8810949


 Last month, Valve invited select developers to Washington for its first-ever conference. Now, anyone can watch the presentations on the web. ...
Last month, Valve invited select developers to Washington for its first-ever conference. Now, anyone can watch the presentations on the web. ...



 be the total number of players,
be the total number of players,  be the edges of a connected graph on
be the edges of a connected graph on  \in E") we assign a weight
we assign a weight  which is the latency of the edge in seconds. In the network we assume that players only communicate with those whom are adjacent in
which is the latency of the edge in seconds. In the network we assume that players only communicate with those whom are adjacent in  bits/second and that the size of the game state is
bits/second and that the size of the game state is  . Given these, we will now calculate the latency and bandwidth requirements of both active and passive replication under the optimal network topology with respect to minimizing latency.
. Given these, we will now calculate the latency and bandwidth requirements of both active and passive replication under the optimal network topology with respect to minimizing latency. \in E} l_{ij} )") . The bandwidth required by active replication over a peer-to-peer network is
. The bandwidth required by active replication over a peer-to-peer network is ") per client, since each client must broadcast to every other client, or
per client, since each client must broadcast to every other client, or ") total.
total. \in E} l_{0j})") . The total bandwidth consumed is
. The total bandwidth consumed is ") per client and
per client and ") for the server.
for the server.") and if we make the additional reasonable assumption that
and if we make the additional reasonable assumption that  , then we could conclude that peer-to-peer replication is overall more efficient. However, in practice this is not quite true for several reasons. First, in passive replication it is not necessary to replicate the entire state each tick, which results in a lower total bandwidth cost. And second, it is possible for clients to eagerly process inputs locally thus lowering the perceived latency. When applied correctly, these optimizations combined with the fact that it is easier to secure a client-server network against cheating means that it is in practice a preferred option to peer-to-peer networking.
, then we could conclude that peer-to-peer replication is overall more efficient. However, in practice this is not quite true for several reasons. First, in passive replication it is not necessary to replicate the entire state each tick, which results in a lower total bandwidth cost. And second, it is possible for clients to eagerly process inputs locally thus lowering the perceived latency. When applied correctly, these optimizations combined with the fact that it is easier to secure a client-server network against cheating means that it is in practice a preferred option to peer-to-peer networking.






 The output window is useful for debugging where breakpoints would be too invasive or interrupt flow but it’s pretty noisy.
The output window is useful for debugging where breakpoints would be too invasive or interrupt flow but it’s pretty noisy.

 Sometimes you want to see what a function returned but you can’t easily because you didn’t store the value because it was the input to another function.
Sometimes you want to see what a function returned but you can’t easily because you didn’t store the value because it was the input to another function.