Shared posts
Vaccine Registries Are Good, Vaccine Apps Are Invasive
How to get more confident speaking up in meetings
Sharing your opinions in meetings can be stressful, especially if you’re more introverted. These steps can make it easier to succeed.
Group meetings can be intimidating. Lots of people, often at different levels of the organization, are sitting in one place throwing out ideas. Meetings are an opportunity to have an impact on ideas in development, but they are also a place where you can display your ignorance in front of a large group. If you’re new in an organization or an introvert who doesn’t like that spotlight, it can be easier to fade into the background and look to have your impact elsewhere.

A year into remote work, most companies still don’t get this basic concept about office-free workplaces
Remote work has quickly become the norm, but most companies are simply replicating in-person workflows online, according to a new survey from GitLab.
Remember when early internet developers created online organization systems by literally copying offices, appropriating files, drawers, and manila folders into digital form, images and all? This is essentially how workplaces are handling remote work, according to the comprehensive new Remote Work Report from the good people at GitLab.

Exxon’s $100 Billion Carbon Capture Plan: Big, Challenging And Needed

How to Reduce Motion Sickness in Virtual Reality
Things We Saw Today: FINALLY, LeVar Burton Is Guest Hosting Jeopardy!

Fans (and the beloved actor and host himself) have been campaigning for months for LeVar Burton to host Jeopardy! and finally, we’re being listened to. Former host of the show Reading Rainbow and star of shows like Star Trek: The Next Generation, Burton is one of those actors who is loved by people everywhere.
So naturally, it makes sense that his calming nature and beloved status would make him a good choice to at least guest host the show. Recently, Jeopardy! has been having guest hosts come on in the meantime, trying to figure out who best fits the mold left behind by Alex Trebek. For so many of us, we’ve been yelling about LeVar Burton since the search began, but it seemed like time and time again, they weren’t listening.
Everyone was else was getting their time except for LeVar Burton but our campaigns and cries worked out!
We can finally tell you! Here is the final group of guest hosts to close out Season 37:
• Robin Roberts
• George Stephanopoulos
• David Faber
• Joe Buck
• LeVar Burton!https://t.co/iAPNyy29pu pic.twitter.com/Twgef7i6b5— Jeopardy! (@Jeopardy) April 21, 2021
LeVar Burton is set to host for 4 days this summer from July 26th – July 30th. Will I be watching all four times? Yes, of course I will. Because I want Burton to take over. He has the right energy for the show. He’s that same beloved status that Trebek was, and it would just bring a new life to the game show and get us all excited once more. So I hope this is the first step towards Jeopardy! handing LeVar Burton the keys.
THANK YOU… to all y’all for your passionate support! I am overjoyed, excited, and eager to be guest-hosting Jeopardy!, and will do my utmost best to live up to your faith you in me. YOU MADE A DIFFERENCE! Go ahead and take my word for it, this time. https://t.co/C7mZWMok2X
— LeVar Burton (@levarburton) April 21, 2021
(image: Jesse Grant/Getty Images for Global Learning XPRIZE)
Here are some other stories we saw out there today:
- Ma’Khia Bryant’s TikToks have gone viral over the body cam footage. (via The Hill)
-
Jeremy Renner posted a photo for #Hawkeye wrapping production and teased his next appearance. https://t.co/X01TDmGCl0 pic.twitter.com/woa6dIY8Fu
— ComicBook.com (@ComicBook) April 21, 2021
- How I Met Your Father is a go. (via Deadline)
-
Shang-Chi’s Toys Tease Martial Arts Mayhem and Awkwafina’s Furry New Friend https://t.co/hACYcw93si pic.twitter.com/Ul5VEe8Cu7
— io9 (@io9) April 21, 2021
- Why don’t TV shows sound the way they used to? (via The New York Times)
Anything we missed, Mary Suevians? Let us know what you saw in the comments below!
(image: Jesse Grant/Getty Images for Global Learning XPRIZE)
Want more stories like this? Become a subscriber and support the site!
—The Mary Sue has a strict comment policy that forbids, but is not limited to, personal insults toward anyone, hate speech, and trolling.—
The post Things We Saw Today: FINALLY, LeVar Burton Is Guest Hosting Jeopardy! first appeared on The Mary Sue.An LA mortician cries out over COVID corpses

Everyone's favorite "death positive" Goth mortician, Caitlin Doughty, vents her spleen over the overwhelming number of COVID deaths her small LA funeral home and many others have been dealing with this winter. Doughty is not feeling so positive about the lack of organization and facilities for dealing with all of the victims of this lingering tragedy. — Read the rest
The Great Gatsby Is Now in the Public Domain and There’s a New Graphic Novel

If you’ve ever dreamed about mounting that “Great Gatsby” musical, or writing that sci-fi adaptation based on Gatsby but they’re all androids, there’s some good news: as of January 1, 2021, F. Scott Fitzgerald’s classic novel finally entered the public domain. (Read a public domain copy here.) Creatives can now do what they want with the work: reprint or adapt it any way they like, without having to negotiate the rights.
Or you could, just like Minneapolis-based artist K. Woodman-Maynard adapt the work into a beautiful graphic novel, pages of which you can glimpse here. Her version is all light and pastel watercolors, with a liberal use of the original text alongside more fantastic surreal imagery, making visual some of Fitzgerald’s word play. At 240 pages, there’s a lot of work here and, as if it needs repeating, no graphic novel is a substitute for the original, just…a jazz riff, if you were.
But Woodman-Maynard was one of many waiting for Gatsby to enter the public domain, which apart from Disney property, will happen to most recorded and written works over time. Many authors have been waiting for the chance to riff on the novel and its characters without worrying about a cease and desist letter. Already you can find The Gay Gatsby, B.A. Baker’s slash fiction reinterpretation of all the suppressed longing in the original novel; The Great Gatsby Undead, a zombie version; and Michael Farris Smith’s Nick, a prequel that follows Nick Carraway through World War I and out the other side. And there are plenty more to come.

Copyright law stipulates that any work after 95 years will enter the public domain. (Up until 1998, this used to be 75 years, but some lawyers talked to some congresscritters).
As of 2021, along with The Great Gatsby, the public domain gained:
Mrs. Dalloway – Virginia Woolf
In Our Time – Ernest Hemingway
The New Negro – Alain Locke (the first major compendium of Harlem Renaissance writers)
An American Tragedy – Theodore Dreiser (adapted into the 1951 film A Place in the Sun)
The Secret of Chimneys – Agatha Christie
Arrowsmith – Sinclair Lewis
Those Barren Leaves – Aldous Huxley
The Painted Veil – W. Somerset Maugham
Now, the thing about The Great Gatsby is that it is both loved by readers and hard to adapt into other mediums by its fans. It has been adapted five times for the screen (the Baz Luhrmann-Leonardo DiCaprio version is the most recent from 2013) and they have all dealt with the central paradox: Fitzgerald gives us so little about Gatsby. The author is intentionally hoping the reader to create this “great man” in our heads, and there he must stay. The novel is very much about the “idea” of a man, much like the idea of the “American Dream.” But film must cast somebody and Hollywood absolutely has to cast a star like Leonardo DiCaprio or Robert Redford. A graphic novel, however, does not have those concessions to the market. Woodman-Maynard’s version is not even the first graphic novel based on Fitzgerald’s book—-Scribner published a version adapted by Fred Fordham and illustrated by Aya Morton last year—-and it certainly will not be the last. Get ready for a bumper decade celebrating/critiquing the Roaring ‘20s, while we still figure out what to call our own era.

Related Content:
The Great Gatsby and Waiting for Godot: The Video Game Editions
The Wire Breaks Down The Great Gatsby, F. Scott Fitzgerald’s Classic Criticism of America (NSFW)
Ted Mills is a freelance writer on the arts who currently hosts the Notes from the Shed podcast and is the producer of KCRW’s Curious Coast. You can also follow him on Twitter at @tedmills, and/or watch his films here.
The Great Gatsby Is Now in the Public Domain and There’s a New Graphic Novel is a post from: Open Culture. Follow us on Facebook, Twitter, and Google Plus, or get our Daily Email. And don't miss our big collections of Free Online Courses, Free Online Movies, Free eBooks, Free Audio Books, Free Foreign Language Lessons, and MOOCs.
Empire in Denial
It’s not just Joe Biden under pressure in the post-Trump transition. It’s the American way in the world, the mindset of a global enforcer. Stephen Wertheim is our guest: a remarkable young historian with a concise and talkable take on the 80-year run of a world empire in denial. Before the fall of France in 1940, global primacy was not on the US agenda, maybe not in our DNA. But supremacy became the goal and then the reality when President Roosevelt took on the Hitler emergency in World War 2. It became a habit through the long Cold War with the Soviet Union; it’s come to feel like a bad habit in a string of bad wars since Vietnam—maybe a habit to be broken as the Trump years turn to Biden’s time.

Wertheim is the resident historian at the Quincy Institute for Responsible Statecraft (Quincy for John Quincy Adams, the sixth president of the US, who insisted that his country not “go abroad, in search of monsters to destroy”). About the modern American place in the world, Steve Wertheim makes it an 80-year saga, about an almost aloof continental sovereign USA that fell from heroic emergency duty in World War 2 into force-projection everywhere, an empire by now, in retreat and confusion.
American unreality
John Gray in New Statesman:
 The unmasking of the bourgeois belief in objective reality has been so fully accomplished in America that any meaningful struggle against reality has become absurd.” Anyone reading this might think it a criticism of America. The lack of a sense of reality is a dangerous weakness in any country. Before the revolutions of 1917, Tsarist Russia was ruled by a class oblivious to existential threats within its own society. An atmosphere of unreality surrounded the rise of Nazism in Germany – a deadly threat that Britain and other countries failed to perceive until it was almost too late.
The unmasking of the bourgeois belief in objective reality has been so fully accomplished in America that any meaningful struggle against reality has become absurd.” Anyone reading this might think it a criticism of America. The lack of a sense of reality is a dangerous weakness in any country. Before the revolutions of 1917, Tsarist Russia was ruled by a class oblivious to existential threats within its own society. An atmosphere of unreality surrounded the rise of Nazism in Germany – a deadly threat that Britain and other countries failed to perceive until it was almost too late.
For the Portuguese former diplomat Bruno Maçães, however, the decoupling of American culture from the objective world is a portent of great things to come. Finally shedding its European inheritance, America is creating a truly new world, “a new, indigenous American society, separate from modern Western civilisation, rooted in new feelings and thoughts”. The result, Maçães suggests, is that American politics has become a reality show. The country of Roosevelt and Eisenhower was one in which, however lofty the aspiration, there was always a sense that reality could prove refractory. The new America is built on the premise that the world can be transformed by reimagining it. Liberals and wokeists, conservatives and Trumpists are at one in treating media confabulations as more real than any facts that may lie beyond them. Maçães welcomes this situation, since it shows that American history has finally begun. As he puts it at the end of this refreshingly bold and deeply thought-stirring book, “For America the age of nation-building is over. The age of world-building has begun.” The truth is America cannot help thinking of itself as a world apart. At an academic meeting in the US years ago, I smiled when a speaker declared that the cause of America’s declining power and influence was its deplorable system of campaign financing. As heads nodded sagely around the table, no one seemed to have considered the possibility that, say, the rise of China might have something to do with events originating in China.
More here.
Gil Scott-Heron explains "The Revolution Will Not Be Televised"

From an interview with Gil-Scott Heron:
— Read the rest"The first change that takes place is in your mind. You have to change your mind before you change the way you live and the way you move…It will just be something you see and you'll think, "Oh I'm on the wrong page."
Alton Brown is just as unhinged as the rest of us right now

Twas the long, dark night before the 2020 Election when Alton Brown shared a series of tweets that will only make sense to everyone feeling absolutely unhinged at this particularly horrible moment in time. In a world beset by a pandemic that increasingly few people seem to give a shit about, a presidential election…
Despite the polls, Trump may still win

The final polls say much the same as they've been saying for weeks, if not months: Joe Biden has a huge lead nationally, and a comfortable one in most swing states. For Trump to win, the polls would have to be off by more than twice what they were off by in 2016. — Read the rest
How to play 1-dimensional Chess

Doctor Popular created a variant of Chess, called 1D Chess. You can download the rules and different board layouts here.
— Read the rest1D Chess is a fun, innovative chess variant played on a single row of 16 squares. Each player begins with one of each piece and must take their opponent's king to win.
Racial disparity and racial bias
by Raji Jayaraman
 Racial disparities are present in all aspects of life. In the U.S. labor market black men are 28 per cent less likely to be employed than white men, and those that are employed earn 69 cents on a white man’s dollar. Blacks and hispanics are 50 percent more likely to experience some kind of force in their interactions with police. Blacks drivers are 40 percent more likely to be stopped than white drivers. The prevalence of, and mortality from, Covid-19 is disproportionately high among blacks.
Racial disparities are present in all aspects of life. In the U.S. labor market black men are 28 per cent less likely to be employed than white men, and those that are employed earn 69 cents on a white man’s dollar. Blacks and hispanics are 50 percent more likely to experience some kind of force in their interactions with police. Blacks drivers are 40 percent more likely to be stopped than white drivers. The prevalence of, and mortality from, Covid-19 is disproportionately high among blacks.
Megan Thee Stallion’s opinion piece was one of last week’s most popular articles in the New York Times. In it, the hip-hop star notes that, “Maternal mortality rates for Black mothers are about three times higher than those for White mothers, an obvious sign of racial bias in health care.” What is obvious to me is that this disparity is unacceptable. What is less evident is that it is “an obvious sign of racial bias”. Is race per se to blame for racial disparities? Maybe, maybe not. It’s possible, perhaps even likely, that healthcare workers or employers harbour racial prejudice against blacks. But it’s not obvious and yet, this type of claim—that racial bias can be inferred from the presence of racial disparities—is commonplace.
Economists have an arguably simplistic, but nevertheless useful way to think about the question of racial disparity. They break it down into two categories: racial bias and statistical discrimination. Racial bias refers to plain vanilla “racism”—I treat a black person differently than I do a white person because I harbour racial prejudice against blacks. Statistical discrimination is at play when I treat blacks and whites differently because, quite apart from race, they have substantively different underlying characteristics.
Consider racial disparities in employment. Prior to the pandemic, the unemployment rate among black workers was twice as large as that of white workers. One explanation for this is preference-based. For example, an employer may choose a white hire over a black hire because she prefers whites to blacks. This is racial bias. Another possibility is that the employer just wants the best person for the job. Unfortunately, she doesn’t get to observe a person’s talents or skills. What she does know is there exists a large educational achievement gap between blacks and whites, so she makes a valid statistical inference that a white applicant is more likely than a black applicant to have the requisite skills for the job. So, even if she harbours no personal prejudice against blacks, she still deliberately chooses a white hire over a black hire. This is statistical discrimination.
Two points about statistical discrimination are worth noting. First, race-based statistical discrimination only exists because we don’t get to observe the truth. An employer can never perfectly observe an applicant’s job aptitude, so she makes an inference based on what she can see. If unobserved truths were observed—if ability or job match quality were stamped on an applicant’s forehead—statistical inference on the basis of skin colour would be unnecessary. The second point to note is that statistical discrimination may logical, but it’s not fair. Just ask the man who couldn’t afford to attend university; would have been perfect for the job; but just so happens to be black.
Empirically, the question of whether racial disparities are driven by racial bias or statistical discrimination is tricky to answer for the simple reason that we don’t get to see the counterfactual: would a black job applicant have been hired, had he been white? Same interviewer, same job, same person,…different race. We can’t know that because the applicant is black. Still, there are ways to try to tease these two things apart and the evidence is mixed, with some studies finding that once one accounts for observable differences between blacks and whites there doesn’t appear to be racial bias, and others finding that these other differences account for part but not all of the racial disparities in labor market or law enforcement outcomes.
This distinction may seem like splitting hairs because at the end of the day, racial disparities remain and should fill us all with moral repugnance. Still, as Ken Arrow pointed out, “moral feelings without analysis can easily lead to unconstructive policies,” and this distinction matters for policy. If racial disparities are driven by racial bias, then reducing these disparities will involve either changing racists’ preferences or getting them to act against their underlying (racist) preferences. If, on the other hand, disparities are driven by statistical discrimination, then reducing racial disparities require some combination of information and opportunity provision.
Consider again the case of racial disparities in employment. If racial bias accounted for this, then potential remedies may be to ensure that there are no racists in the employer’s HR department; or to train them to overcome racial prejudice. If, instead, statistical discrimination is to blame, then the employer may want to gather more information on applicants in order to reduce their reliance on race-based statistical inference; or governments may need to do more to bridge the educational achievement gap between blacks and whites.
I am no psychoanalyst, but casual observation of my fellow human beings over the course of several decades has left me skeptical that we have any credible means to identify racists; “convert” them; or get them to behave properly in any consistent manner. Recent evidence that things like implicit bias training and diversity training are largely ineffectual lend support to my skepticism. The upshot is that studies, which find that racial disparities can be attributed to racial bias leave me feeling incredibly depressed. Human nature in adulthood just isn’t malleable enough to fundamentally change people’s preferences or behaviours.
Evidence that racial disparities can be attributed to statistical discrimination gives me no joy. But it does give me a modicum of hope that something can be done to reduce disparities. We could reduce the need for statistical inference based on race by gathering better information. We could institute policies that level the playing field and provide equality of opportunity. These policy measures have their own problems and some may prove intractable, but addressing the problems underlying statistical discrimination strikes me as a less futile endeavour than “curing racism”.
One of my main objections to left-leaning friends who cry, “Racist!” when confronted with racial discrimination is that their explanation trivializes what is in fact a much deeper problem, that warrants a complex set of solutions that can only be informed through a deeper understanding of underlying sources of statistical discrimination. Solutions that we have some ability, and hopefully the will, to implement.
Amy Coney Barrett’s Lack of Notes Isn’t Impressive, It’s Disturbing

Today is the second day of confirmation hearings for Amy Coney Barrett to take Ruth Bader Ginsburg’s seat on the Supreme Court. With only 21 days until the election, Republicans are fast-tracking her confirmation in a last-ditch effort to pack the court and potentially rule on the results of the election with a conservative majority. And given their majority in the Senate, there seems to be no stopping Coney Barrett’s confirmation.
Coney Barrett knows this, which may be why she brought zero notes, records, or receipts to the multi-day hearing. Today, when prompted by Texas Senator John Cornyn, she revealed a little blank notepad with nothing on it. “That’s impressive,” Cornyn responded, before moving on.
VIRAL MOMENT: Amy Coney Barrett reveals she has no notes at hearing.
Sen. John Cornyn: “Can you hold up what you’ve been referring to in answering our questions? Is there anything on it.”
Barrett: “A letterhead that says United States Senate.”
Cornyn: “That’s impressive.” pic.twitter.com/QOybcZrUiE
— The Hill (@thehill) October 13, 2020
This has led to a chorus of Republicans praising Coney Barrett for her keen legal mind. “She doesn’t need notes! It’s all in her head!”, they cry as if Coney Barrett’s complete lack of preparation is something to celebrate. But it’s not. As ACB continues to offer non-answers and political doublespeak to the senators’ questions, she isn’t saying much of anything at all. Nobody needs notes to rattle off disingenuous platitudes about the law.
This was when Barrett was asked to show what notes she had brought to hearing. Senators are sitting in front of thick binders of research as they question her https://t.co/WhT6xLFcEn
— Mollie (@MZHemingway) October 13, 2020
But much like the president who nominated her, ACB can’t be bothered to prepare. It’s a sign of an oversized ego, of the knowledge that she already has the votes to be confirmed. And she has zero interest in defending her record, because she knows it doesn’t matter. It’s smarm masquerading as knowledge, and zealotry in the face of scrutiny. But Coney Barrett has already shown she’s not taking the process seriously with her omission of important documents to the senate committee.
Democrats on the Senate Judiciary Committee sent a letter to the Department of Justice to request withheld materials from Coney Barrett, which include two lectures given to anti-abortion students groups at Notre Dame. The Democrats’ letter read, “First, Judge Barrett’s SJQ supplement includes two 2013 talks — a lecture and a seminar — about the Supreme Court’s cases on women’s reproductive rights, … Both talks, which were also omitted from Judge Barrett’s 2017 SJQ and attachments, were made public in press reports early yesterday. It is troubling that Judge Barrett supplemented her SJQ to include these talks only after they were identified by the press.”
It feels absurd to type this, but it must be said: America deserves a Supreme Court justice who does the work, who prepares, who gathers evidence, and who doesn’t omit problematic speeches and positions. Her smug lack of preparation is insulting to everyone watching these hearings. If confirmed, she’ll be making decisions that affect millions of Americans. That should be more than enough reason for her to do her homework.
It’s also a searing indictment of these hearings and her nomination. Amy Coney Barrett isn’t making a case for herself because she thinks she’s already won. Many took to social media to call out her concerning lack of notes:
Amy Coney Barrett: I can say literally nothing about how I’ll decide cases.
Sen. Cornyn: wow and you gave that answer with no notes?
ACB: Yes.
Cornyn: Holy shit.
— Johnny “The Crypt Renter” McNulty (@JohnnyMcNulty) October 13, 2020
Amy Coney Barrett wants to be the replacement for Justice Ruth Bader Ginsburg, and I’m supposed to be impressed she didn’t bring notes to the hearing?
That’s not impressive. That’s concerning.
— Charlotte Clymer 🏳️🌈 (@cmclymer) October 13, 2020
Amy Coney Barrett is going to vote to dismantle health care — and she won’t even need NOTES.
— Matt Fuller (@MEPFuller) October 13, 2020
It’s not difficult to be “confident in how you’re going to express yourself” if you plan on… not expressing yourself.
Stop applauding Amy Coney Barrett for having zero notes in front of her during this hearing. She doesn’t need any. She’s not saying anything. #SCOTUShearings
— Danielle Campoamor (@DCampoamor) October 13, 2020
WATCH: Senator @amyklobuchar just asked Judge Barrett whether it’s illegal under federal law to intimidate voters at the polls.
Barrett refused to answer. Then Klobuchar read her the law. Astonishing. pic.twitter.com/cxoIaXTP9e
— Vanita Gupta (@vanitaguptaCR) October 13, 2020
Maybe this is why 88 of her colleagues at Notre Dame called for her to step aside. I doubt she’ll listen.
(featured image: screencap/MSNBC)
Want more stories like this? Become a subscriber and support the site!
—The Mary Sue has a strict comment policy that forbids, but is not limited to, personal insults toward anyone, hate speech, and trolling.—
Facebook Bans Anti-Vaccine Ads, But Not Organic Misinformation
Read more of this story at Slashdot.
Qian Zhongzhu Should Win the Nobel
Brendan O’Kane in the Los Angeles Review of Books:

Qian Zhongshu is a tough pitch to win the Nobel prize in literature this year. He’s dead, for starters – traditionally an obstacle to many things, including winning Nobel prizes – and his total creative output consists solely of a few essays, several short stories, and a single novel. On the other hand, that novel, Fortress Besieged, seems to me to be the high-water mark of something significant, if hard to explain, so I’m going to make my best case for it being enough to secure Qian’s place in history. The book takes its title from a French proverb, sets its action in the China of the 1930s, and tracks the misfortunes of Fang Hongjian, a feckless, cowardly student returning from Europe with a mail-order doctorate in Chinese from an American university that exists only in the imagination of a crooked Irishman. It may be one of the most cosmopolitan books ever written; certainly it is, as literary critic C. T. Hsia said, one of the greatest Chinese novels of the 20th century.
More here.
4 under-the-radar Google Docs features that will save you time
Type as fast as you can speak, Google without Googling, gather feedback in a few clicks, and more with these Google Docs tools you may have overlooked.
For many of us, Google Docs is an oft-used weapon in the productivity battle. But even if you use Docs on the regular, you might not know about some of its best time-saving tricks.

What Voltaire Meant When He Said That “We Must Cultivate Our Garden”: An Animated Introduction

“Voltaire’s goal in writing [his 1759 satire Candide] was to destroy the optimism of his times,” says Alain de Botton in the School of Life video above, “an optimism that centered around science, love, technical progress, and a faith in reason.” These beliefs were folly, Voltaire thought: the transfer of faith from a providential God to a perfect, clockwork universe. Candide satirizes this happy rationalism in Doctor Pangloss, whose belief that ours is the best of possible worlds comes directly from the philosophical optimism of Gottfried Leibniz.
The preponderance of the evidence, Voltaire made abundantly clear in the novel’s series of increasingly horrific episodes, points toward a blind, indifferent universe full of needless cruelty and chaos. “Hope was, he felt, a disease,” de Botton says, and “it was Voltaire’s generous goal to try and cure us of it.” But as everyone who has read Candide (or read a summary or brief notes on Candide) knows, the novel does not end with despair, but on a “Stoic note.”
After enduring immense suffering on their many travels, Candide and his companions settle in Turkey, where they meet an old man sitting quietly under a tree. He tells them about his philosophy, how he abstains from politics and simply cultivates the fruits of his garden for market as his sole concern. Invited to feast with the man and his family, they remark upon the luxurious ease in which they live and learn that they do so on a fairly small plot of land.
Voltaire loved to goose his largely Christian readers and delighted in putting the novel’s parting wisdom, “arguably the most important adage in modern philosophy,” in the mouth of an Islamic character: Il faut cultiver notre jardin, “we must cultivate our garden.” What does this mean? De Botton interprets the line in the literal spirit with which the character known only as “the Turk” delivers it: we should keep a “safe distance between ourselves and the world.”
We should not, that is, become overly engaged in politics, and should devote ourselves to tending our own livelihood and welfare, not taking more than we need. We should leave our neighbors alone and not bother about what they do in their gardens. To be at peace in the world, Voltaire argued, we must accept the world as it is, not as we want it to be, and give up utopian ideas of societies perfected by science and reason. In short, to “tie our personal moods” to human affairs writ large is to invite endless misery.
The philosophy of Candide is not pessimistic or nihilistic. A happy, fulfilled human life is entirely possible, Voltaire suggests, if not human happiness in general. Candide has much in common with the ancient Roman outlook. But it might also express what could be seen as an early attempt at a secular Buddhist point of view. Voltaire was familiar with Buddhism, though it did not go by that name. Buddhists were lumped in, Donald S. Lopez, professor of Buddhist and Tibetan Studies at the University of Michigan, writes at the Public Domain Review, with the mass of “idolaters” who were not Christian, Jewish, or Muslim.
Yet the many Jesuit accounts of Eastern religion reaching Europe at the time circulated widely among intellectuals, including Voltaire, who wrote approvingly, though critically, of Buddhist tenets in his 1764 Dictionnaire philosophique. As the secular mindfulness movement has done in the 21st century, Lopez argues, Voltaire sought in the age of Enlightenment to separate miraculous legend from practical teaching. But like the Buddha, whose supposed biography Voltaire knew well, Candide begins his life in a castle. And the story ends with a man sitting quietly under a tree, more or less advising Candide to do what Voltaire had heard of in the “religion of the Siamese…. Meditate in private, and reflect often on the fragility of human affairs.”
Related Content:
An Animated Introduction to Voltaire: Enlightenment Philosopher of Pluralism & Tolerance
Voltaire: “Those Who Can Make You Believe Absurdities, Can Make You Commit Atrocities”
Philosophers Drinking Coffee: The Excessive Habits of Kant, Voltaire & Kierkegaard
Josh Jones is a writer and musician based in Durham, NC. Follow him at @jdmagness
What Voltaire Meant When He Said That “We Must Cultivate Our Garden”: An Animated Introduction is a post from: Open Culture. Follow us on Facebook, Twitter, and Google Plus, or get our Daily Email. And don't miss our big collections of Free Online Courses, Free Online Movies, Free eBooks, Free Audio Books, Free Foreign Language Lessons, and MOOCs.
Google Maps gets a COVID-19 layer
-
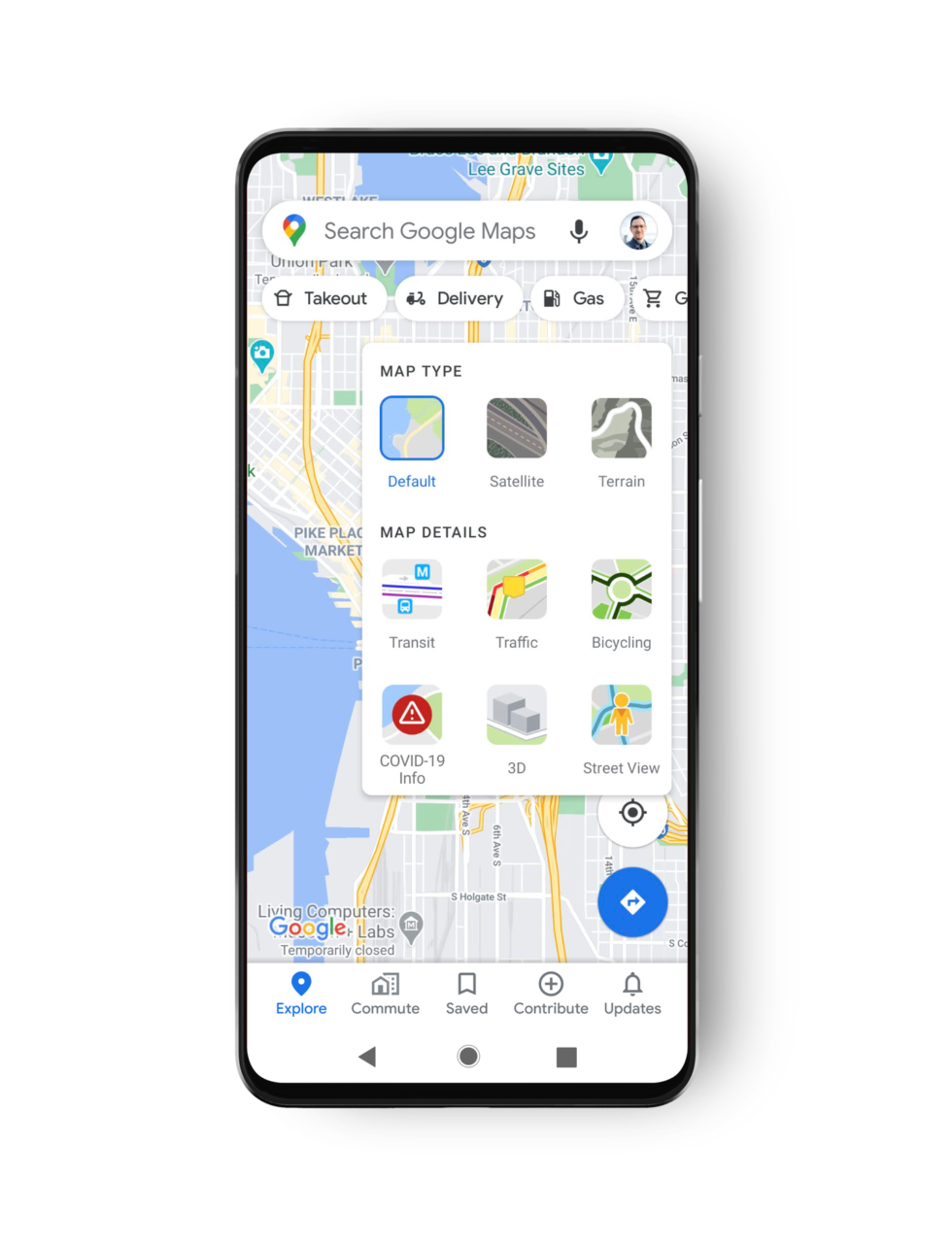
Tap the layer menu in the top right and press "COVID-19 info." [credit: Google ]
Google Maps is getting a COVID-19 overlay, meaning soon you'll be able to see pandemic data as easily as you can view satellite or traffic data.
Once the rollout hits your device, you'll be able to press the "layer" button and switch to a "COVID-19" view that will re-color the map. Google says the overlay is a "seven-day average of new COVID cases per 100,000 people for the area of the map you’re looking at." Users will also get an arrow indicating if the numbers are trending up or down. Here's the color code:
- Gray: Less than 1 case
- Yellow: 1-10 cases
- Orange: 10-20 cases
- Dark orange: 20-30 cases
- Red: 30-40 cases
- Dark red: 40+ cases
Google says the information comes from "multiple authoritative sources, including Johns Hopkins, the New York Times, and Wikipedia." I wouldn't quite call Wikipedia an "authoritative source," but Google notes that "these sources get data from public health organizations like the World Health Organization, government health ministries, along with state and local health agencies and hospitals."
Read 1 remaining paragraphs | Comments
Breonna Taylor’s Image Is Not for Your Commodification

Breonna Taylor’s life was cut short by police, and in the aftermath of the fact that no officers were charged directly in her death, and only one faces three counts of wanton endangerment for shooting into neighboring apartments, rage is in the air. Yet, when it comes to getting justice for Breonna, there are multiple battles being fought—one over the judicial system and one over the commodification of her image, death, and legacy.
Hulu began promoting a Breonna Taylor docu-series just a few hours after the verdict was made, meaning that they had this waiting in the wings to be part of commodifying Black pain. Very quickly, the streaming service was called out and issued an apology on Twitter, removed the post, and claimed that they will learn from the error in judgement.
Earlier today, we promoted content that we felt would be meaningful in light of today’s events. That was, quite simply, the wrong call. We’ve taken the posts down and are deeply sorry. Thank you for holding us accountable – we will learn from this.
— Hulu (@hulu) September 24, 2020
Despite apologizing for this, the damage was done, and it is just another example of how websites, and businesses in general, have used Black pain and suffering as a way of profiting—highlighting Black voices for a month, but underpaying Black creators and fostering racist spaces. Making Black Lives Matter merch, but having no Black staff.
Breonna Taylor’s name has been on the lips of known racists as part of their rebranding to prove that their racism is in the past and that they’re so plugged in to the Black issues of the day. While for some there is true growth, for others, it is them accepting that casual racism just is not as groovy as it used to be.
Justice for Breonna Taylor was more than a hashtag; it was a call to arms and a bittersweet reminder for Black Americans that we are not citizens with value in this country—that we have to dismantle a system that allows, in the core of its legal system, the murder of citizens by the police.
To take something that is so painful and raw, to take another act of systematic injustice and use that to promote a docu-series, is cruel, ignorant, and shows that Black Lives Matter is just a slogan for many. But this goes beyond Hulu. If you were having events, making money, and building a brand based around trying to get justice for Breonna Taylor, what are you going to do now? How are you going to take her legacy and use it to create something that honors her? Or was the hashtag the end of it?
(image: JASON CONNOLLY/AFP via Getty Images)
Want more stories like this? Become a subscriber and support the site!
—The Mary Sue has a strict comment policy that forbids, but is not limited to, personal insults toward anyone, hate speech, and trolling.—
Biggest Worry On Election Security Is Americans' Loss Of Confidence, Wray Says

The FBI director told members of Congress his greatest fear isn't so much that a foreign nation might achieve some coup, but that too many citizens might no longer trust their own democratic process.
(Image credit: Chip Somodevilla/AP)
James Gunn continues to ace his role as the unofficial MCU/DCEU peace ambassador

Pop culture really doesn’t deserve James Gunn. First, the writer and director breathed new life into the MCU with Guardians of the Galaxy, paving the way for weirder fare like Taika Waititi’s Thor: Ragnarok. Then, after being scorned by Disney over some bad-faith trolling, he agreed to cross over to the other side to …
Artists Ask Whitney Museum to “Commit to a Year of Action”

Last month, the Whitney Museum of American Art canceled its planned exhibition Collective Actions after numerous artists denounced the acquisition process for the works, most of which were purchased by the museum from social justice fundraisers and included in the show without their input. Critics noted that many of the works were by Black artists, prompting accusations that the show exploited the labor of creators of color.
Today, September 17, the intended opening date of the now-defunct exhibition, a group of artists that were selected for the show has released an open letter asking the museum to “commit to a year of action — of mobilization and introspection.”
Authored by Chiara No, Kara Springer, and fields harrington and signed by 47 artists who were selected to participate in Collective Actions, the letter urges the Whitney to seriously examine its practices and policies to better represent and engage with historically excluded communities. Among its signatories are artists Lola Flash, Texas Isaiah, Shaniqwa Jarvis, and Dana Scruggs.
The letter begins by acknowledging that the exhibition “originated from a place of well intentioned interest in marking a historical moment of political action.”
However, the artists continue, “Though it was our commitment to mutual aid and political action that brought us together and drew you to us in the first place, rather than joining us in that effort and that spirit of reciprocal support, the missteps made here stand in marked contrast to the ethical framework within which these projects were created.”
Spanning prints, photographs, and posters sold primarily to benefit causes related to Black Lives Matter and COVID-19, the works in Collective Action were priced below market value, critics of the show argued. Others were downloaded free of cost as digital files submitted to Printed Matter’s open call for anti-racist protest material. Rather than negotiating the value of the works and discussing the context of the exhibition with the artists, the show’s curator, Director of Research Resources Farris Wahbeh, apprised most selected participants of their inclusion via email less than a month before the exhibition’s scheduled opening. The controversy went viral, and within 24 hours, the museum formally called off the exhibition and issued an apology to the artists.
Rather than “hurriedly cancelling a show whose failures lay in the museum,” the Whitney should have “taken the time to listen and respond,” the open letter argues. “The brave move would have been to lean into the discomfort rather than further demonstrating our dispensability to your institution by cancelling the show within hours of receiving criticism online.”
The incident has sparked a conversation about the ways in which cultural institutions at large contribute to the systemic devaluing of Black artists’ work. Springer, No, and harrington encourage the Whitney to institute ethical guidelines for acquisition practices and determine approaches that do not rely on “the unpaid labour of Black, Indigenous, and POC artists and community members,” among other recommendations.
“This is a critical historical moment that calls for us to move past easy statements of support for Black lives into the real work to transform and dismantle oppressive systems of power,” they write. “We, the undersigned, come together now as we will again in a year, as an offer of accountability.”
In response to Hyperallergic’s request for comment, Senior Deputy Director Scott Rothkopf said, “Over the past three weeks, we have reached out personally to each of the artists to acknowledge their concerns and have had productive conversations with many of them. We recognize the issues raised and are committed to continuing this dialogue and making positive changes for the future.”
Read the open letter in full below or at cancelledcollectiveactions.com:
To the curators, directors, and board members of the Whitney Museum:
We are living through a moment marked by well-intentioned, but all too often hollow, gestures of support for Black Lives and racial justice. We understand that the now cancelled Collective Actions originated from a place of well intentioned interest in marking a historical moment of political action. Though it was our commitment to mutual aid and political action that brought us together and drew you to us in the first place, rather than joining us in that effort and that spirit of reciprocal support, the missteps made here stand in marked contrast to the ethical framework within which these projects were created. We come together here to ask what a real effort by the Whitney Museum to support communities further marginalized and pushed toward precarity in this moment of global crisis and national reckoning might look like.
The Whitney’s formal statement in support of Black communities states that you have increased the racial diversity of your collection, exhibitions, and performances. The ways in which you acquired our work and planned to show it, without conversation with or consent from many of the included artists, demonstrates an undervaluing of our labor and denial of our agency. This calls into question how you have increased the diversity of your collection. The purpose of acquiring work is not only to preserve a moment in time but also to support living artists. All too often, Black, Indigineous, and POC artists are invited in because our radicality serves to signify institutional inclusivity and progressiveness. This performance of racial inclusion seldom comes alongside a real commitment to supporting historically excluded communities. That we were brought into the museum through an administrative loophole in which the special collection acquisition made it possible to collect and exhibit our work without adhering to the museum’s own standards of compensation offers an important insight into how Black, Indigineous, and POC artists continue to be inadvertently marginalized and exploited.
While this is very much a situation born of the specific longstanding problems of the Whitney Museum, it is also true that there are very few institutions who don’t suffer from the same blindspots. Rather than hurriedly cancelling a show whose failures lay in the museum’s rush to encapsulate a still unfolding historical moment, the museum could have taken the time to listen and respond. The brave move would have been to lean into the discomfort rather than further demonstrating our dispensability to your institution by cancelling the show within hours of receiving criticism online. We want to be clear that this is not a calling out of the failure of any individual. These fumblings are born of the broken system that undergirds all of our lives and our institutions. That the Whitney found itself in a situation in which it was called out by individuals and communities who felt their actions here were unethical and exploitative is neither new nor remarkable. What could be new, what could be remarkable is to allow the radicality of collective vision and action to seep into the fabric of your institutional foundation. You could change.
We urge the Whitney Museum to take this opportunity to do so. We’re writing to you on September 17th, the day of the scheduled opening of the Collective Action exhibition. We ask that you as an institution commit to a year of action – of mobilization and introspection. How will you take less and give more to historically excluded communities? How will you institute ethical guidelines in future acquisition practices? How will you ensure that your institution holds the capacity to navigate this charged political moment without relying on the unpaid labour of Black, Indigenous, and POC artists and community members to advocate for the betterment of your institution?
We appreciate that the Whitney has entered into dialogue with many of the artists from the now cancelled Collective Actions. The question at the root of our collective actions and of your assembling of our work, is how can we make use of the means we have available to us to support the urgent needs of our most vulnerable in this time of global and national crisis? This is a critical historical moment that calls for us to move past easy statements of support for Black lives into the real work to transform and dismantle oppressive systems of power. We, the undersigned, come together now as we will again in a year, as an offer of accountability. Let us hold each other to the task of real action and intervention in this time of change.
Sincerely,
Kara Springer, Whitney ISP ‘18
Chiara No, Artist
fields harrington, Whitney ISP ‘20
Kirsten Hatfield
Nicole Rodrigues
Charles Mason III, Artist
Spyros Rennt, Artist
Simi Mahtani, Artist
Joe Kusy, Artist
Texas Isaiah, Artist
Katy Nelson, Artist
Jessica Caponigro, Snake Hair Press
Mark Clennon
Marcus Maddox
Zora J Murff, University of Arkansas / Strange Fire Collective
Lola Flash, Artist
Kevin Claiborne
Christelle de Castro
Clay Hickson
Linda Huang, Designer
Andrew LeClair, Designer
Lukaza Branfman-Verissimo
Mimi Zhu, Artist
Sheldon Abba, People’s Film Program
Alicia Smith
Daniel Arnold
Denise Shanté Brown, Holistic Design Strategist
Anthony Geathers
Milcah Bassel, Sol JC
Shantal Henry, Sol JC
Michelle Pérez, Sol JC
Gisel Endara, Sol JC
Joana Arruda, Sol JC
Serena Hocharoen
Kimi Hanauer, Press Press
Seitu Ken Jones, Seitu Jones Studio
Justine Kelley
Julia Kim Smith, Artist
Ike Edeani
Taeyoon Choi
Ciara Mendez
Alex Hodor-Lee
Kenny Cousins
Shaniqwa Jarvis, Artist
Georgia McCandlish
Jessica Foley, Photographer
Dana Scruggs
Taco Bell is now selling "Jalapeño Noir" wine in select locations

Goodbye, Big Oil: "Half the world's proven reserves (1.7 trillion barrels) will never be needed"

Now Is the Time To Bring Back Away Messages
Read more of this story at Slashdot.
See how Dune 2020 visually compares to David Lynch's 1984 adaptation

On Wednesday, the clouds parted and the first trailer for Denis Villeneuve’s anticipated adaptation of Dunc Dune shined down upon us. Sure, it could end up being a big ol’ dud, but, given that Villeneuve’s past films include Blade Runner 2049 and Arrival, whatever we get is at least going to be visually arresting,…