
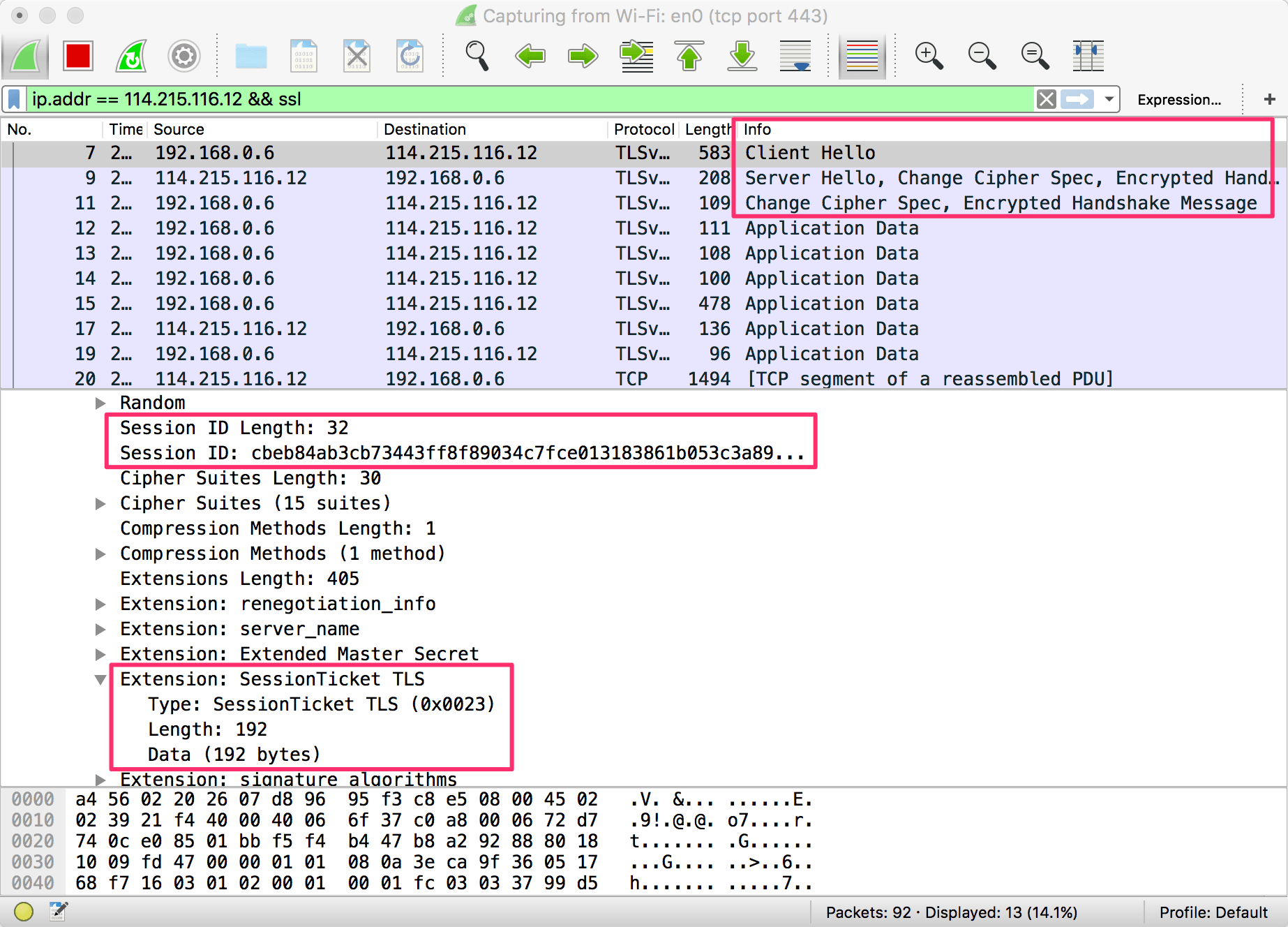
汽车行业的未来是如此令人兴奋,你几乎能够碰到它了——在那个自动驾驶电动车的世界中,没有了每年 125 万的交通死亡人数,引起气候变化的气体排放量大大减少,城市的停车场变成公园,醉驾和分心驾驶的危险不复存在。我们似乎都知道自己想要的是什么。但是,谁会把这个前景带给我们?
我相信,这个不可避免的转换将会创造出颠覆传统汽车制造业的、极为清晰的推动力量, 而且,正如其它被科技改变的行业(报纸、旅行社、音乐行业、传统零售业等等),许多新赢家可能会出现。让我们看看原因何在。
1.创新
随着每个行业都变成了科技行业,它的创新步伐必须加速。那些习惯于把摩尔定律当做信息时代唯一确定性特征的人们知道,快速创新是持久存在的事情。如果你不能快速创新,你的竞争者就会去做,而你就在这一轮技术发展中落后了。
快速创新的传统在科技行业是常见的,但是,工业时代的公司却缺乏这个传统。思考一下汽车工业的产品周期有多长吧——新汽车模型的开发需要花费 3 至 5 年,然后,在上市后,这款车型会在市场上停滞六年时间,缺乏有意义的改进或新的创新。得到新功能的唯一方法?买一辆新汽车吧。
当涉及到汽车时,科技行业肯定会选择不同的道路。我们思考的是,构建硬件平台并且将其部署到市场上。在此平台上,我们能经常升级操作系统。而操作系统允许开发者创造数以百万计的 app,把新功能带给用户。
我们知道,用户期望着产品进行意义的升级,并且是通过无线完成的。当需要对核心硬件进行创新时,科技公司会快速推进,通常是 1 到 2 年的周期。
一个很好的例子是手机。如今,消费者能够快速更新汽车上的移动功能(例如导航),但是,他们通常是从手机上得到的,而不是传统的汽车制造商。
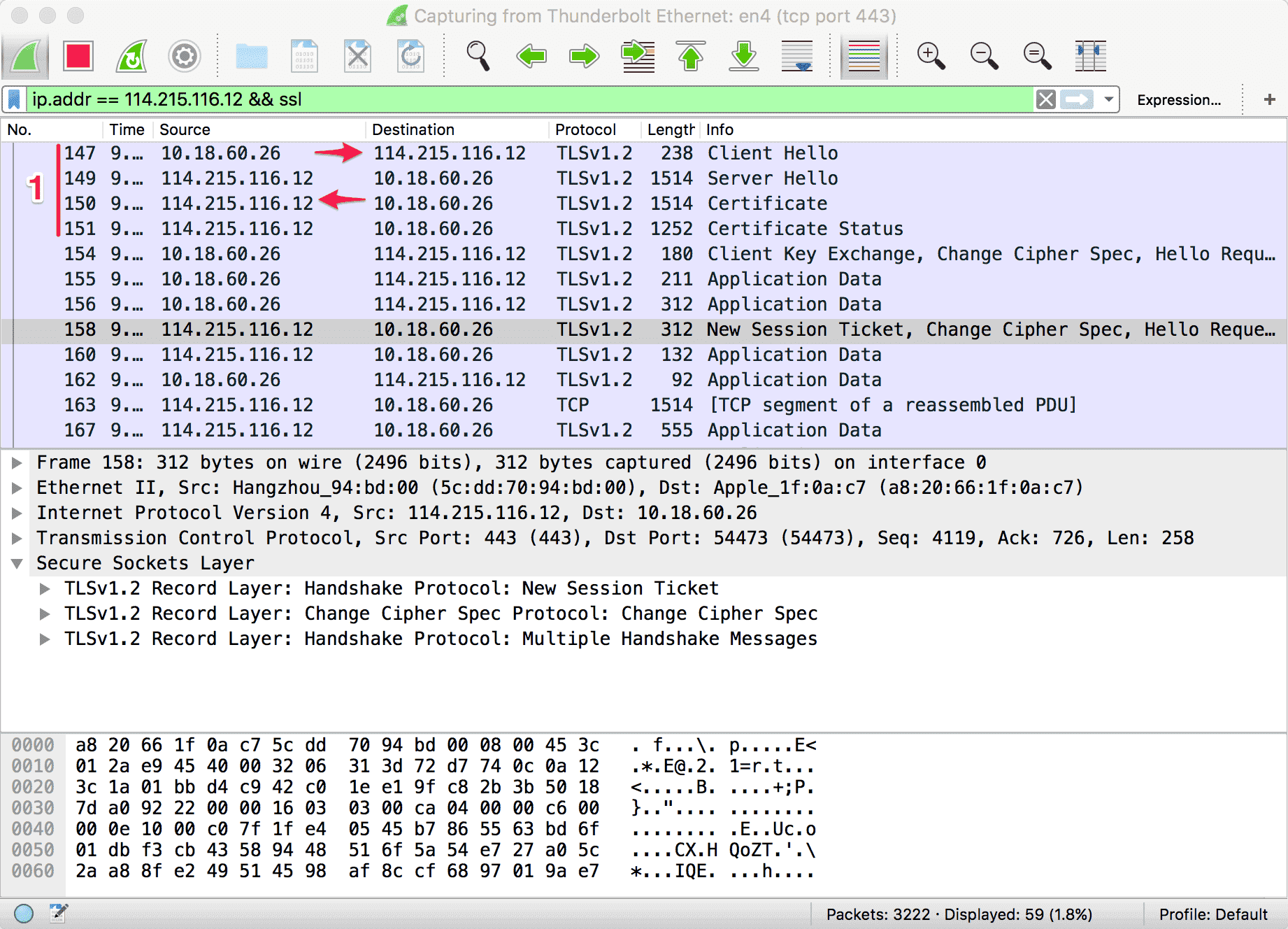
汽车行业进行快速创新的复杂之处在于,汽车制造商基本上是汽车的组装者。它们自己制造的汽车部件很少,相反,几乎所有的关键部件都外包给了一线的供应商,比如博世和大陆集团。看看下面这幅图:

当你产品的大部分都是供应商设计和制造的时候,你或许就会欠缺关键的工程主导地位,无法进行深度和快速的产品创新,难以与竞争对手区别开来。当一个新玩家进入汽车行业后,它们也肯定会从一线或者二线的供应商那里获取大部分的部件,但是,它们很可能会在一些领域进行自主创新,而这些领域是今天的汽车制造商和供应商都不太擅长的。我们下面会谈到这些领域。
(我知道,一些读者会指出,苹果也把大量的 iPhone 部件外包给第三方供应商。尽管如此,苹果自己设计了最重要的部件——CPU、系统和许多内置应用。这篇文章试着去解释为何这是至关重要的。另外,苹果与供应商深度合作,在最有可能让终端用户受益的领域,进行一些直接的开发。而大多数的汽车公司则未能做到这一点。)
2.电动化
特斯拉、Google、苹果和其他新入场的汽车制造商都将它们的设计专注于电动汽车。理由有很多,而最大的是因为电动发动机比传统的内燃发动机简单多了。从某些方面来说,此种复杂性去除后,制造伟大汽车产品的核心技能也被重新定义——与内燃发动机、汽化器、变速箱、排气装置、排放控制系统和燃油经济性管理说再见吧;欢迎电池、电量优化、充电系统和引擎控制器进场。
这些新功能中,一部分是消费电子制造商很熟悉的东西,因为它们在电池续航寿命和电量优化上已经努力一段时间了,尽管是一种很小规模的努力。而且一些汽车公司已经制造出了电动汽车。但是,完全以此(电动车)为基础构建整个组织的话,将会形成一种新的专注和创新的曲线,抛弃掉那些将此当做副项目的公司。
3.软件
或许,汽车行业最重要的转变是它转向了软件。汽车业的未来将很大程度上依赖于软件开发者。没错,现有的内燃发动机汽车确实也有一个包含许多代码的嵌入式系统,能够处理从 HVAC 到自动传动等一切事情。但事实上,把这么多层的软件整合起来是一件复杂的事情,给传统的汽车制造商带来了许多烦恼,毕竟这不是它们的专业领域。除此之外,未来的汽车将会以更深入且不一样的方式利用软件。
当然,我们知道,特斯拉(目前)和苹果(将来)正试图重新想象驾驶员和汽车之间的界面,而且,它们的中控台(很可能)是非常漂亮的,而且将会给那些汽车制造商觉得我们需要看到的、多余的刻度盘带来巨大改进(你上次必须检查最大功率转速和发动机温度是什么时候?)。好的硬件、软件和用户体验设计师会是这一切的根基。
不过,配备了 ADAS 系统以及日益增强的自动化能力的未来汽车将会需要做出数兆亿的驾驶决策,而其根据则是大量的感应器数据。视觉、LiDAR、声纳和其它的感应器将与实时的网络数据、来自其它车辆的数据,甚至是城市环境数据源结合起来。
这些数据将会被实时分析,有可能结合汽车和网络上的计算数据,做出驾驶决策。如此复杂的 AI 系统将会是有适应能力的机器学习系统,它会不断地更新自己的决策模型。
理解这些后,你就不会奇怪于 Google 今天在自动驾驶开发上的领先地位了。Google 的搜索引擎正是此类系统规模效应的实例,而且,Google 的许多核心开发特长是基于云端的预测系统的。
传统的汽车公司可能不擅长于这些领域的主要原因有两个。首先,全球最好的 AI 工程师、数据科学家和云端计算专家们很少在汽车公司工作。尽管这些公司也拥有一些有才华的工程师,而且近年来许多基于硅谷的研究中心是汽车公司创办的,但是,对于特别厉害的技术架构师和数据科学家来说,Google、特斯拉、苹果和 Uber 这样的公司仍然具有极大的吸引力。他们想要用软件颠覆汽车行业。第二个原因则是数据。
4.数据
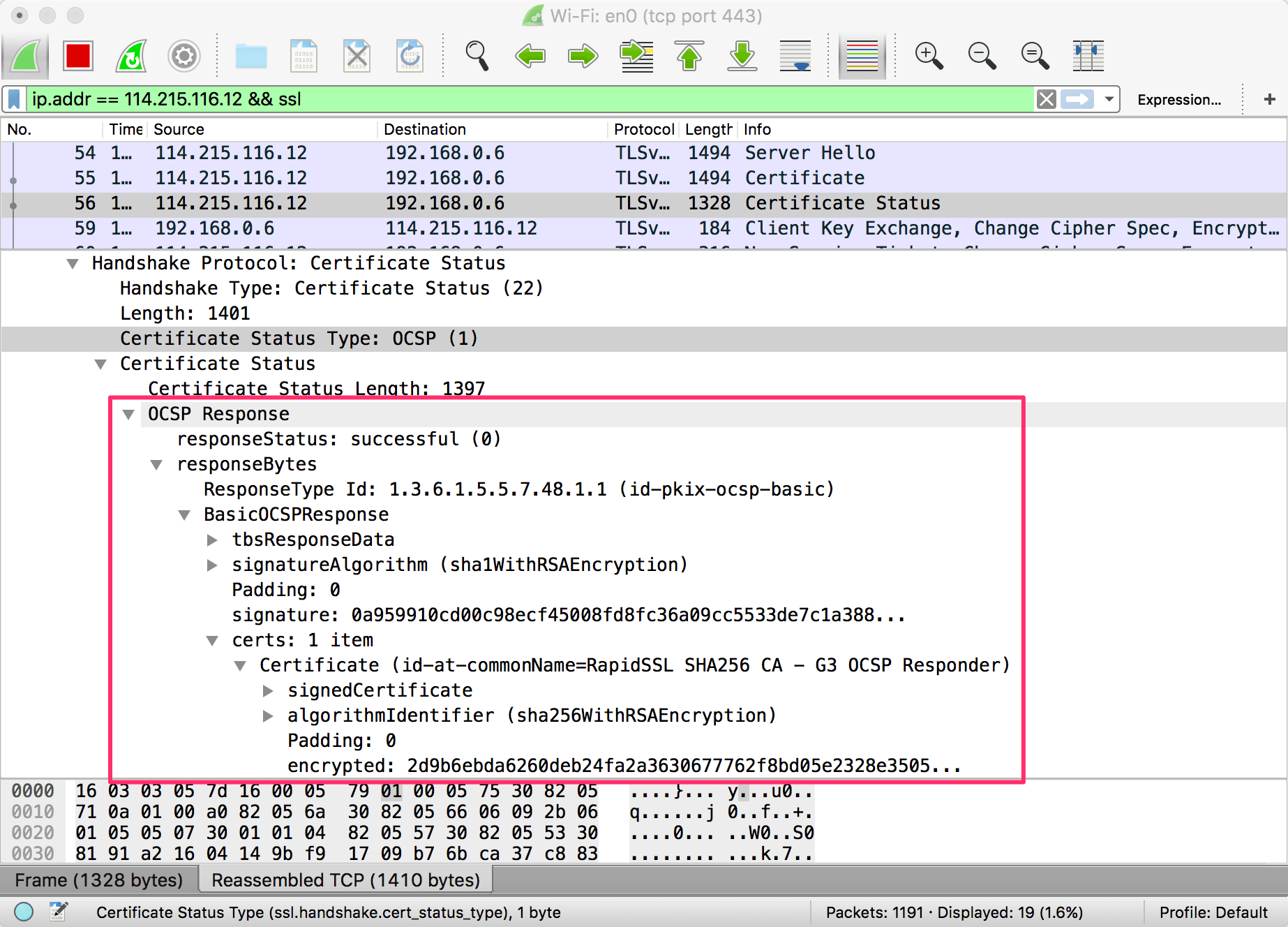
将摄像头、传感器与 Mobileye(此公司主要产品是基于摄像头的高级驾驶辅助系统) 芯片连接起来后,去做一些对齐车道或者自适应巡航控制是非常容易的事情。但要达到真正的无人驾驶则难得多,因为首先要让系统去学习。
我们现在还没有一套可以编程到汽车中的既有规则,让它可以预测和避免可能出现的一切危险情况。高效的自动驾驶程序必须利用机器学习能力去发展出一种复杂的模型,让它可以适应各种不同环境。而要达到最佳的效果,机器学习系统就需要大量的数据。
你还记得 Google 提供的“Free 411”服务吗?实际上,他们这样做并不是出于大方,而是为了收集到数百万的声音和言语模式,以此来调教现在用于 Google Now 的语音识别系统。
Google 习惯于利用大规模数据去达到其他人不能企及的优秀表现。正是这种网络效应使得 Google 搜索的表现依然超越一众竞争者。Google 目前拥有 63% 的搜索市场份额,它就是比任何人的数据都要多。它能看到比任何人更多的点击和搜索动作,并可以此训练自己的算法。

同样的数据规模优势也会影响无人驾驶汽车。这就是为什么 Google 让它 48 辆无人驾驶汽车组成的车队行驶 120 万英里的原因——为了收集数据和调教它们的系统。在两辆停放的汽车中缓慢走过的行人?这是一种危险情况。太阳光反射出有一个水坑在你的左边?这并不危险。
而特斯拉也是非常重视数据的。你可以从 VentureBeat 这篇文章窥探一二。
2、关键区分点是“ 车队学习”
特斯拉制造的每一款 Model S——甚至那些缺乏必要感应器,从而无法实现自动导航的版本——会把行驶数据传送给公司,只要汽车主人允许。
数据的增长速度大概是每天 150 万英里,它们来自全球行驶在路上的约 10 万辆 Model S。
这些数据被(以匿名形式)整合到地图之中,让自动导航系统看到汽车应该选择的准确道路,或者不选择那条道路,然后将此覆盖到第三方的道路地图之上。
“每个驾驶员都是训练自动导航的高效专业教练员,” 马斯克解释说。特斯拉汽车网络正不断地了解汽车究竟可以行驶在哪些路段。
因此,系统的能力“将随着时间不断改进,既从那些训练它的所有专业驾驶员,” 他说,“也从软件功能上。”——后者指的是添加新功能。
最好的无人驾驶汽车会是那些处于最大网络或者车队中,和网络内其他成员分享数据并从中学习的汽车。对于现有的汽车生产商来说,这就是一个问题。它们没有任何数据。如果它们要加入这个行列,就需要在现有的车型上加上设备来收集数据,并且回到实验室中调教自己的系统。(我听说 Uber 打算做这件事,它们的驾驶路径数据可是非常大的。)
而且,在那些传统汽车生产商生产的无人驾驶汽车上,几乎所有的零件都来自一级供应商。那些供应商也没有数据。实际上,在收集数据上,它们面临的是更严重的问题,因为它们不能和驾驶者产生直接联系——它们拿不到我们的数据。
5.和消费者建立直接关系
之前我曾经写过,当人们的注意力从主流媒体转移到社交媒体平台,品牌就需要和消费者建立直接的关系。汽车行业最需要颠覆的部分是现有的生产商/经销商模式。在这个模式中,汽车公司把车卖给经销商,然后经销商把车以(高得特别离谱的价格)卖给消费者。这个想法真的已经过时了。
第一家成功地与消费者建立直接关系的汽车品牌是特斯拉。他们做对了。他们没有经销商,而是有展示厅。他们不会对我们乱开价。(我记得有一次听汽车公司为他们这种行为辩解,说是消费者真的喜欢讨价还价。)汽车工业将如何应对这种现代互动方式,让一家汽车公司去真的了解他们的消费者吗?而为了保护经销商,美国某汽车经销商协会还向特斯拉发起了诉讼。
现代汽车公司不会再使用传统的经销商网络。他们会直接把车卖给消费者,并且和他们形成长期关系。
6.高层的轻视
从那些汽车公司最有影响力的执行官口中,我们听到了汽车公司不会把我们带到美好未来的最后一个信号:
“我觉得,就像非常多的硅谷科技公司,他们觉得自己比世界上的汽车公司聪明,可以做得更好。这是不可能的事。”
“没有任何理由相信苹果会在电动汽车上取得财务上的成功。电动车会是亏本买卖。如果我是股东,我会坐立不安的。”
-Bob Lutz,通用汽车前副主席
“我完全想不到谁会成为第一个售卖无人驾驶汽车的人。”-Mark Fields,福特 CEO
“今天处于汽车行业中的是我们,而不是他们。”-Mark Reuss,通用产品开发总监(当谈到 Google 的时候)
你可能还记得黑莓联合 CEO(Jim Balsillie)说的这些话:
[苹果和 iPhone]是进入这个已经竞争激烈的行业的新手,在这个行业中,消费者有非常多的选择……但是说这将会给黑莓带来重大改变,我觉得这是夸张了。(2007.2)
苹果 iPhone 是很好,但确实是给用户带来了真正的挑战。试试在 iPhone 的触摸屏上打一下网页关键词,那真的是一个挑战。你看不到你打的是什么。(2007.11)
确实,苹果、Google、Uber 还有其他从事未来汽车的新公司对已经持续 107 年的汽车行业一窍不通。但关键在于,未来的汽车行业将会完全不同于过去。
我相信,现有的很多汽车厂商会生产出有自动驾驶功能的汽车,而且还会有非常优秀的产品。逐渐地,他们会生产出可以完全自动驾驶的汽车。与此同时,许多超级强大且有想法的企业家会带来更多不可思议的硬件和软件体验。他们会努力从根本上重新定义消费者对汽车的期望。
创新和颠覆的历史告诉我们,在重要的技术平台变革的拐点,新玩家会出现,并且从现有玩家那里夺取相当多的市场份额和利润。我们觉得,我们已经到了这种变革的浪尖 。合理的做法是严肃对待此种转变。我知道,我们正是这样做的。
本文全文译自 Medium,原文标题 The Auto Industry Won’t Create The Future。作者 David Pakman。这篇文章描述了电动车和无人驾驶技术的到来给传统汽车行业带来的颠覆性改变,科技公司,而不是传统汽车公司将在此领域大有作为。爱范儿积木、黄美菁翻译出品。
题图来自:YouTube
插图来自:Medium
#欢迎关注爱范儿认证微信公众号:AppSolution(微信号:appsolution),发现新酷精华应用。

 0
0
 0
0
























































{kind=link}
{kind=link}