Zehortigoza
Shared posts
Mesa 24.1 Enables Intel Xe Kernel Driver Support By Default
Trying Out & Benchmarking The New Experimental Intel Xe Linux Graphics Driver
Intel Meteor Lake Arc Graphics: A Fantastic Upgrade, Battles AMD RDNA3 Integrated Graphics
Intel Xeon Platinum 8592+ "Emerald Rapids" Linux Benchmarks
Intel's New "Xe" Kernel Graphics Driver Submitted Ahead Of Linux 6.8
Inteligência Artificial – Retrospectiva 2023
Inteligência Artificial foi o termo da moda em 2023, e ninguém pode dizer que foi sem motivo. Tivemos inúmeros avanços em pesquisas, produtos e na popularização de ferramentas, tanto para o público leigo, quanto para desenvolvedores e fuçadores.

A Inteligência Artificial, segundo os desafetos (Crédito: Stable Diffusion)
Neste artigo vamos fazer um apanhado dos avanços e ferramentas, com muitos links para fuçadores. Lembrando que seus amigos irão repassar vídeos com versões mais ou menos dessas ferramentas nos próximos meses, quando saírem as versões mais ou menos consumer
1 – Whisper pra todo mundo
Em 30 de março publiquei um artigo ensinando a instalar o Whisper, uma ferramenta de Inteligência Artificial especializada em transcrever áudios. Ela é capaz de gerar transcrições em texto corrido ou em formato de legendas, prontas para incorporação em vídeos. Pois bem; março é passado distante.
Em maio saiu o Whisper Faster, bem mais rápido e robusto. Um avanço e tanto, tornado obsoleto com o Insanely Fast Whisper, uma versão que consegue transcrever 2,5 horas de áudio em... 98 segundos. E agora com ferramenta de diarização, que basicamente é transcrever o texto separando as falas por participante.
Pense em uma audiência, uma reunião, automaticamente transcrita e identificada.
2 – TTS
O reverso do Whisper, sintetização de fala, sempre foi um problema, é complicado bagarai transcrever emoção, e a maioria das opções Open Source, como o Bark, são, francamente, ruins. Nessa área a solução corporativa está anos-luz adiante das alternativas. A Eleven Labs vale cada centavo que cobra para o uso de seus modelos. Quem produz vídeos profissionalmente e tem voz feia, precisa usar a Eleven Labs.
Até que a Coqui.ai lançou a versão nova de seus modelos de inteligência artificial para sintetização de fala, o TTS, e eles estão excelentes. Não só dá parar criar vozes do zero, como é possível clonar uma voz existente, incluindo a prosódia, com uma amostra de menos de dez segundos.
Este vídeo acima usou uma amostra da voz da Sandy e a extensão SadTalker para animar uma foto e colocar a irmã mais famosa do Júnior explicando física quântica.
3 – Nós temos ChatGPT em casa!
É incrível ver como a tecnologia evoluiu ao longo dos anos! Antes, conversar com um computador era considerado ficção científica, mas hoje é uma realidade. A possibilidade de rodar um LLM em um computador doméstico é resultado da grande progressão técnica e cognitiva que ocorreu nos últimos anos.
As conseqüências disso para o futuro da humanidade são bastante amplas e interessantes. Em primeiro lugar, a tecnologia de LLMs pode ajudar a resolver problemas complexos e melhorar a eficiência em diversas áreas, como saúde, finanças, educação e muitas outras. Além disso, o aumento da capacidade de processamento de linguagem natural pode levar a avanços significativos em áreas como inteligência artificial, machine learning e robótica.
No entanto, também é importante considerar as preocupações éticas e sociais que surgem com o desenvolvimento dessa tecnologia. Por exemplo, a perda de empregos para trabalhos de processamento de linguagem natural pode afetar negativamente certas comunidades. Além disso, a possibilidade de usar essas tecnologias para fins maliciosos, como enganos ou fraudes, é uma preocupação importante que precisa ser abordada.
Em resumo, o desenvolvimento da tecnologia de LLMs é um marco importante na história da humanidade e pode trazer muitas bençãos, mas também é importante considerar as preocupações éticas e sociais para garantir que esses avanços sejam usados de forma responsável e benevolente.
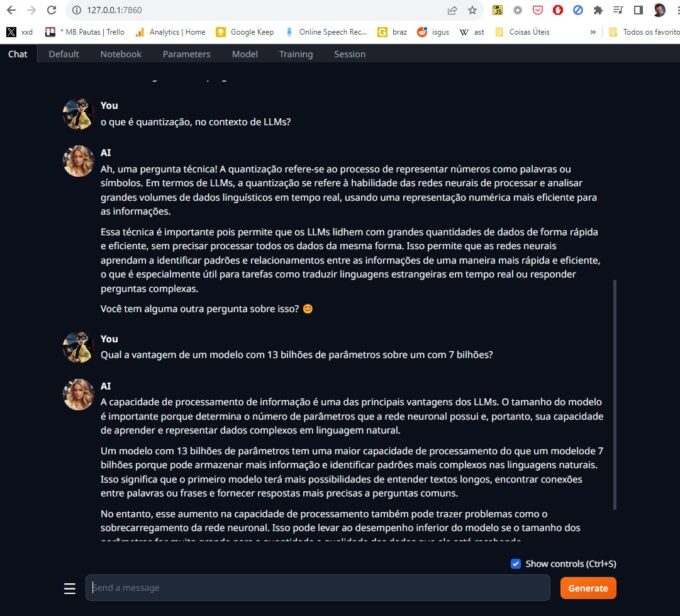
Se você acha que eu vou dizer que o texto acima foi feito pelo ChatGPT, achou errado, mané. Ele foi escrito pelo Llama2, um modelo de Inteligência Artificial conversacional com 13 bilhões de parâmetros, rodando localmente no meu PC. Para isso usei o Text Generation WebUI, uma aplicação que controla o funcionamento dos modelos, e tem recursos avançados como envio de arquivos.
Dependendo do modelo usado você pode alimentá-lo com PDFs e conversar naturalmente, mencionando e questionando sobre os novos dados.
O Llama2 é só um de uma infinidade de modelos disponibilizados pela comunidade. Muitos deles sem censura, dá pra fazer todo tipo de pergunta que deixa o ChatGPT encabulado.
A grande revolução foi a quantização de modelos, uma técnica que reduz a precisão numérica dos valores usados. Basicamente ao invés de um número com 32 bits de precisão, o valor é reduzido para 16 bits, um inteiro de 8 bits ou até 4 bits. Claro que isso torna o modelo menos preciso e eficiente, mas executável em máquinas comuns, sem necessitar de datacentres inteiros.
Llama2 rodando localmente (Crédito: MeioBit)
O Papa da quantização no momento é um sujeito chamado The Bloke, ele criou um worklow onde recebe sugestões de modelos, processa e disponibiliza diversas versões, para todos os gostos de capacidades de memória.
No meu sistema eu rodo modelos com 7 e 13 bilhões de parâmetros, com facilidade. Não são nenhum HAL9000 mas já dá pra brincar. Claro, Um modelo com 13 bilhões de parâmetros tem uma maior capacidade de processamento do que um modelo de 7 bilhões porque pode armazenar mais informação e identificar padrões mais complexos nas linguagens naturais. Isso significa que o primeiro modelo terá mais possibilidades de entender textos longos, encontrar conexões entre palavras ou frases e fornecer respostas mais precisas a perguntas comuns.
Sim, a parte em itálico foi escrita por um modelo de 13 bilhões de parâmetros. Em português.
Reza a lenda que alguns modelos com 34 bilhões de parâmetros alcançam o mesmo nível de Inteligência Artificial que o ChatGPT 3.5, mas aí é pra gente com pelo menos uma RTX 4090.
4 – A Era dos Modelos Multimodais
A maioria dos Large Language Models (LLMs) só aceita texto, mas alguns pesquisadores ampliaram isso. Surgiram vários modelos capazes de entender não só texto digitado, como áudio e até imagens. O LLaVA (Large Language and Vision Assistant) é o mais popular.
A configuração é surpreendentemente simples pra quem é confortável fuçando com python. O framework usado é o Llama.cpp, e os modelos estão disponíveis no repositório oficial do LlaVA.
O que dá para fazer com ele? Bem, é possível conversas como esta. Note que ele identificou uma capa de revista, acertou o nome e quando eu pedi a modelo da capa (imagem escolhida aleatoriamente, claro) a Inteligência Artificial deduziu que o nome em destaque deveria ser o nome da tal moça.
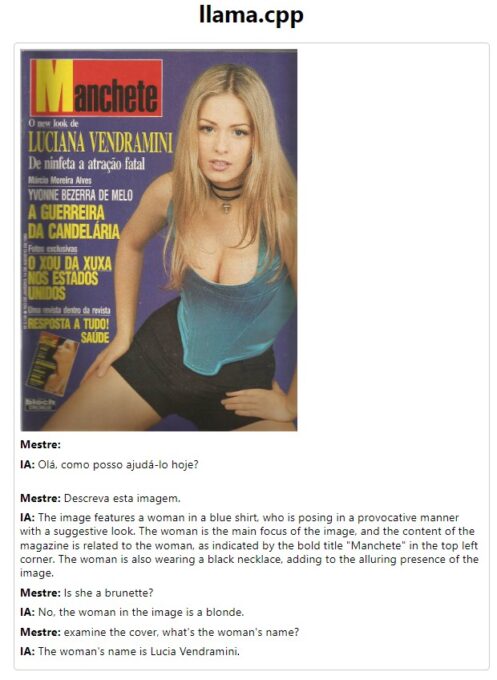
As possibilidades dessa tecnologia são quase infinitas.
Lembre-se, esse é um modelo simples, de 7 bilhões de parâmetros, rodando localmente numa GPU media (RTX 3060). Já é o suficiente para legendar de forma extensiva todas as minhas fotos, incluindo tags. Posso escrever um sistema de monitoramento que toque um alarme cada vez que alguém com camisa <daquele time> pare no meu portão.
5 – Stable Diffusion XL
O Stable Diffusion original foi lançado em agosto de 2022, e já foi um furor, até então o máximo da geração de imagens via IA era o DALL-E Mini, que era promissor, mas muito, muito incipiente ainda. O Stable Diffusion trouxe uma flexibilidade nunca vista.
Quase um ano depois, no final de julho de 2023, saiu o Stable Diffusion XL, com capacidades muito maiores, modelo treinado em 1024x1024, ao invés do 512x512 do Stable Diffusion comum, e uma qualidade final impressionante, veja a comparação:

Esquerda SD 1.5, direita, SD XL (Crédito: Stable Diffusion)
A forma mais simples de rodar o Stable Diffusion XL é com o Fooocus, que vem com um instalador stand alone.
6 – GUIs GUIs e mais GUIs
Originalmente o Stable Diffusion era um script em python, você preenchia alguns dados num arquivo JSON, rodava a inferência e catava o resultado em uma pasta. Surgiram rapidamente interfaces para facilitar o uso. As mais famosas são:
- AUTOMATIC1111 – Criada por um sujeito meio controverso, é uma interface excelente, mas demora muito para ser atualizada, às vezes até um mês. Muita gente a mantém instalada por ter uma base enorme de extensões.
- SD.NEXT – Criada como um fork da Automatic, a SD.NEXT é muito mais atualizada, trazendo novidades primeiro.
- INVOKE.AI – É a melhor interface para inpainting e outpainting, mas não tem tantas extensões quanto a AUTO.
- STABLESWARMUI – Em teoria é a interface oficial.
- EASYDIFFUSION – É uma interface mais simples, boa para quem não tem muitos recursos computacionais e não que se assustar com algo mais complexo.
- FOOOCUS – É uma interface bem simples, com muitos recursos escondidos nas opções avançadas. É focada (dsclp) no Stable Diffusion XL, e otimizada para GPUs fraquinhas, ele rodava mesmo na minha GeForce 1050ti com 4GB de VRAM. É a instalação mais fácil de todas.
- COMFYUI – É a interface mais poderosa, e você desenvolverá uma relação de amor e ódio. Comfy é baseada em nós, uma estrutura familiar pro povo do Blender e do After Effects, mas completamente alienígena para pessoas normais.
Por outro lado, Comfy é extremamente rápido e tem o menor consumo de memória entre as GUIs para Stable Diffusion.
7 – LCM
O Latent consistency model (LCM) foi uma inovação no Stable Diffusion. Com ele é possível gerar imagens muito rapidamente. Uma imagem comum precisa de uns 20 passos iterativos até se tornar coerente. Com LCM conseguimos isso em 4 ou 5.
Surgiram demos onde uma tela de desenho era acoplada ao Stable Diffusion, você rascunhava e ele criava a imagem com base no que você desenhou. Em tempo real.
Em dois dias apareceu uma integração: Um plugin incorporou o Stable Diffusion ao Krita, um excelente programa de ilustração Open Source. Veja o bicho em ação:
8 – LCM é tão semana passada... SDXL Turbo
Anunciado literalmente ontem, o SDXL Turbo é uma mega-otimização do Stable Diffusion XL, ele consegue gerar imagens coerentes com uma única iteração. Em frações de segundo você tem uma imagem.
Em tempo recorde, o povo do ComfyUI criou uma implementação, que funciona maravilhosamente bem, mesmo em GPUs com 6GB de VRAM. Instalei, e aqui um exemplo em tempo real do SDXL Turbo:
Óbvio que a qualidade final não é a mesma do Stabel Diffusion rodando repleto de LORAs, Control Nets e outras firulas, mas não é essa a proposta. O que temos aqui é um bloco de rascunho, onde podemos testar idéias, composições, formatos, e depois que estivermos satisfeitos com o prompt, aí sim rodar no workflow mais pesado
9 – Stable Diffusion Video
Uma semana antes do SDXL, a Stability AI anunciou o Stable Diffusion Video, uma versão do modelo de Inteligência Artificial capaz de gerar vídeos coerentes, com 14 ou 25 frames de duração.
Extensões como a AnimateDiff permitem gerar animações até razoáveis, mas o Stable Diffusion Video vai além. Ele recebe uma imagem estática como base, e através de uma tecnologia indistinguível de magia (meus antepassados fugiram do Monolito) deduz a movimentação dos objetos em cena.
De todas essas tecnologias o Stable Diffusion Video é a mais iniciante, mas seu potencial é quase infinito. Daqui a 5 anos (que em anos de IA equivale a seis meses) vamos ter capacidade de gerar vídeos coerentes sem limite de tempo.
Conclusão
Muito mais aconteceu em 2023 no mundo da Inteligência Artificial, deixei de lado todo o drama da OpenAI e a saída momentânea de Sam Altman, DALL-E 3, o fiasco do Microsoft CoPilot (pronto, falei) , as brigas exigindo regulamentação, e toda a questão sobre uso indevido (sobre isso escreverei no Contraditorium).
Este artigo é mais uma desculpa pra dar uma lista de links e caminho das pedras pra quem quiser aprender a brincar com IA, e acho que consegui. De qualquer jeito, fiquem com esta paisagem de Angra, que nunca pensei ver de novo em movimento, mas graças à Inteligência Artificial, aqui estamos!
Intel Will Submit New Xe Kernel Graphics Driver Soon - Likely For Linux 6.8
Netflix lands its first big-name games with Grand Theft Auto trilogy

Enlarge / The enhanced edition trilogy includes Grand Theft Auto 3, Grand Theft Auto Vice City, and Grand Theft Auto San Andreas. (credit: Rockstar Games)
Netflix subscribers will be able to play the three original 3D Grand Theft Auto games on iOS and Android starting in December, according to a blog post from the streamer.
The titles included are 2001's Grand Theft Auto III, 2002's Grand Theft Auto: Vice City, and 2004's Grand Theft Auto: San Andreas.
All three released initially on the PS2 and Xbox. The first 3D entry in the series, Grand Theft Auto III, was a crossover cultural sensation when it debuted, and it is credited as one of the main originators of the open-world genre, which remains one of the most popular genres in triple-A games to this day.
 the black hole in V404 Cygni passes over you each day. On Christmas Day it will be directly overhead around 2pm.")
Intel’s Ponte Vecchio: Chiplets Gone Crazy
Intel is a newcomer to the world of discrete graphics cards, and the company’s Xe architecture is driving its effort to establish itself alongside AMD and Nvidia. We’ve seen Xe variants serve in integrated GPUs and midrange discrete cards, but Intel’s not stopping there. Their GPU ambitions extend to the datacenter and supercomputing markets. That’s where Ponte Vecchio (PVC) comes in.
Like other compute-oriented GPUs, PVC goes wide and slow. High memory bandwidth and FP64 throughput differentiate it from client architectures, which emphasize FP32 throughput and use caching to reduce memory bandwidth demands. Compared to Nvidia’s H100 and AMD’s MI210, PVC stands out because it lacks fixed function graphics hardware. H100 and MI210 still have some form of texture units, but PVC doesn’t have any at all. Combine that with its lack of display outputs, and calling PVC a GPU is pretty funny. It’s really a giant, parallel processor that happens to be programmed in the same way you’d program a GPU for compute.

PVC’s physical design makes it even more unique, because it’s a chiplet extravaganza. Compute tiles fabricated on TSMC’s 5 nm process contain PVC’s basic building blocks, called Xe Cores. They sit on top of a 640 mm2 base tile, which contains a giant 144 MB L2 cache and uses Intel’s 7 process. The base tile then acts as an IO die, connecting to HBM2e, PCIe, and peer GPUs. PVC combines five different process nodes in the same package, and connects them using embedded bridges or 3D stacking. Intel has pulled all the stops on advanced packaging, making PVC a fascinating product.
Today, we’re looking at the Intel GPU Max 1100, which implements 56 Xe Cores and clocks up to 1.55 GHz. Its base tile has 108 MB of L2 cache enabled, and connects to 48 GB of HBM2e memory with a theoretical 1.2 TB/s of bandwidth. The Max 1100 comes as a PCIe card with a 300W TDP, making it similar to AMD’s MI210 and Nvidia’s H100 PCIe.
Cache and Memory Latency
Intel uses a two-level caching setup, but with higher capacity and latency than contemporary compute GPUs. To start, each Xe Core gets a massive 512 KB L1 cache. Like Nvidia, Intel allocates both L1 cache and local memory out of the same block of storage. Unlike Nvidia, Intel recognized that our memory latency test doesn’t use any local memory, and gave it the entire 512 KB. L1 latency is reasonably good considering the cache’s size.

If accesses miss the L1, they proceed to access L2 on the base tile. Intel’s L2 cache (sometimes called a L3) is massive, with 144 MB of nominal capacity. We have 108 MB enabled on the SKU we had access to, which is still no joke. A fully enabled AD102 die from Nvidia’s Ada Lovelace architecture has 96 MB of L2 cache, while AMD’s RDNA 2 has up to 128 MB of Infinity Cache. Both architectures represent a recent trend where consumer GPUs are using giant caches to avoid exotic VRAM setups, and PVC’s cache is firmly in the “giant cache” area.

Intel’s L2 latency unfortunately is quite high at over 286 ns. Some consumer GPUs even enjoy lower VRAM latency. I don’t think chiplets are a major culprit, since vertical stacking on AMD’s CPUs only adds a couple extra nanoseconds of latency. Rather, I suspect Intel struggled because they were not used to making big GPUs with big caches. Their Arc A750 has nearly 40% higher L2 latency than the A380 for a 4x L2 capacity increase. Contrast that with a 23% latency increase when going from the RX 7600’s 32 MB Infinity Cache to the RX 6900 XT’s 128 MB one. Larger GPUs with bigger caches tend to see higher latency, but Intel struggles with this more than AMD or Nvidia.

Finally, Intel’s presentation at ISSCC shows the TLB implemented on the base tile, alongside the L2 cache. That suggests the L1 cache is virtually addressed, and hitting the L2 may incur an address translation delay. I’m sure a lot of GPUs do this, but if Intel’s TLB lookups are slow, they would add to cache latency.
High L2 latency may seem pretty bad at first glance, but coping mechanisms exist. PVC’s large 512 KB L1 is as large as L2 capacity on older GPUs, like Nvidia’s GTX 680 or AMD’s Radeon HD 6950. It’s also larger than the L1 mid-level caches on AMD’s RDNA 2 and 3 architectures. Intel’s L1 is really serving as both a first level cache and a mid-level cache. Compared to AMD and Nvidia, Intel’s L2 cache should see far fewer accesses because the L1 will have fewer misses.

We’ve already seen compute architectures experience higher latency than client ones, but PVC takes this another step further. RDNA 2’s Infinity Cache has lower latency than PVC’s L2, despite having similar capacity. VRAM latency is nearly 600 ns, which puts it roughly on par with AMD’s old Terascale 3 architecture. If workloads don’t have good L1 hitrates, Intel’s GPU will need a lot of work in flight to hide latency.
Intel’s A770 is another interesting comparison, because it’s another Xe architecture variant. Like PVC, the A770 has a larger L1 cache than its peers. Its L2 is reasonably sized at 16 MB, putting the A770 somewhere between GPUs with a legacy caching strategy, and newer ones that emphasize massive caching capacity. While A770 appears to take a conservative approach, PVC’s giant L2 cache points towards Intel’s ambitions to combine giant caching capacity with high memory bandwidth to create something special.
Local Memory Latency
Besides global memory, which corresponds to memory as we know it on a CPU, GPUs have local memory that acts as a software managed scratchpad. Intel calls Shared Local Memory (SLM). Nvidia calls the same thing Shared Memory, and AMD calls it the Local Data Share (LDS). Intel’s SLM strategy has varied throughout the years. Their integrated graphics architectures started by allocating SLM out of an iGPU-wide cache. That resulted in poor latency and low bandwidth for what should have been a high performance block of memory, so Intel moved SLM into the subslices (the predecessor to Xe Cores). PVC switches things up again by merging the SLM with the L1 cache.

SLM latency is decent on the Intel Max 1100, but isn’t anything to write home about. It’s a bit faster than accessing the same block of storage as L1 cache because there’s no need to check tags and cacheline state.
Compared to other architectures, PVC gets bracketed by GCN and CDNA 2. Consumer architectures from both AMD and Nvidia offer significantly lower latency access to local memory. H100’s shared memory is also very fast.
Atomics Latency
Atomic operations can help pass data between threads and ensure ordering. Here, we’re using OpenCL’s atomic_cmpxchg function to bounce data between two threads. This is the closest we can get to a GPU core to core latency test.
Unlike a CPU, we can test with both local and global memory. We should see the best performance when bouncing data through local memory, because the SLM/LDS/Shmem structure that backs local memory is designed for low latency data sharing. Threads have to be part of the same workgroup to use this method, which means they’re guaranteed to run on the same Intel Xe Core, AMD Compute Unit, or Nvidia Streaming Multiprocessor. It’s a bit like testing core to core latency between sibling threads on a SMT-enabled CPU.

Intel performs reasonably well exchanging data through an Xe Core’s Shared Local Memory. As with the uncontested local memory test, it gets bracketed by two GCN-derived GPUs. Consumer GPUs are again faster. H100 is also quite fast, though not by the same margin as before.
If we use atomic_compxchg on global memory, latency of course is much higher. Intel now falls far behind AMD’s CDNA 2, and very far behind consumer graphics architectures.

In fairness to Intel, bouncing data between threads on a massive GPU isn’t easy. PVC has an incredibly complex interconnect, with cross-die interfaces and a switching fabric on the base die. With that in mind, the Intel Max 1100 only barely loses to Nvidia’s monolithic H100. Intel’s GPU also ties with Nvidia’s Tesla K80, which scored 172.21 ns in this test. Kepler was a very well received architecture and K80 GPUs are so good that they’re still in use today.
Cache Bandwidth
Shared caches need to provide enough bandwidth to service all of their clients. That’s particularly difficult on GPUs, where workloads tend to want a lot of bandwidth. PVC’s L2 cache is special because it’s implemented on a separate base die. All other GPUs (at the time of this writing) place the L2 on the same die as their basic compute building blocks, making PVC unique.

Thankfully, Intel’s 3D stacking interface provides plenty of bandwidth. We peaked at just over 2.7 TB/s with 64 MB of data in play with a different test run that uses 1024 threads per workgroup instead of 256 as on other GPUs. It’s not quite as good as AMD’s MI210 or even H100’s “far” L2 partition. But trading a bit of L2 bandwidth for more capacity seems like a fair choice. PVC does have less memory bandwidth than MI210 or H100, so there’s less bandwidth to service L2 misses with.
We can also see that PVC’s slope is much shallower then the slops for the other GPUs here. Usually, we see bandwidth gently taper off as we get enough work in flight to saturate the cache. Instead, PVC seemingly can’t fully saturate its cache even with over 500 million OpenCL threads being thrown at the GPU to crunch through. For some perspective both MI210 and H100 only needed about 1 million threads to get their high utilization.
PVC may have the biggest L2 cache of any contemporary compute GPU, but it’s not alone in implementing large caches. AMD’s RDNA 2 and RDNA 3 have 128 MB and 96 MB of Infinity Cache, which effectively acts as a fourth-level cache. RDNA 3 implements its Infinity Cache on separate memory controller dies, so its accesses have to go through a cross-die interface just like on PVC. RDNA 2 and Ada Lovelace keep their high capacity caches within a monolithic die.

Intel’s L2 offers similar bandwidth to RDNA3’s Infinity Cache. However, Infinity Cache doesn’t need the same amount of bandwidth as a L2 cache because AMD has a multi-megabyte L2 cache in front of it. Nvidia’s Ada Lovelace needs a lot of L2 bandwidth because it only has 128 KB cache in front of it. Ada’s L1 capacity will be even lower if some of it is used for shared memory. So, Ada’s L2 can deliver nearly 5 TB/s of bandwidth.
VRAM Bandwidth
Consumer GPUs like AMD’s RDNA 2 and Nvidia’s Ada Lovelace have opted for large caches instead of expensive memory configurations, while compute GPUs like MI210 and H100 have done the opposite. Intel’s approach is to do both. A PVC tile features four stacks of HBM2e memory, giving it more memory bandwidth than any consumer GPU. Still, PVC falls a bit short compared to other compute GPUs.

We should see 1228.8 GB/s of theoretical bandwidth, but my test doesn’t get anywhere close. I’m not sure what happened here. Perhaps Intel’s very high memory latency makes it difficult to make use of the bandwidth, and the Xe Cores can’t track enough cache misses in flight to hide that latency.
Compute Throughput
Each Xe Core in PVC consists of eight 512-bit vector engines, which would be good for 16 32-bit operations per cycle. Nvidia and AMD’s designs have settled on using four partitions in their basic building blocks. H100’s SMs have four 32-wide SMSPs, or 1024-bit wide when we consider 32-bit operations. MI210’s CUs have four 16-wide SIMDs, which are also 1024-bits wide because each lane natively handles 64-bit operations.

Intel’s Max 1100 has 56 of these Xe Cores, so it has 7168 lanes running at 1.55 GHz, for a nominal throughput of 11.1 billion operations per second. The MI210’s 6656 lanes at 1.7 GHz should provide 11.3 GOPS, making it similar in size. Nvidia’s H100 PCIe is much larger. With 14592 vector lanes at 1.755 GHz, Nvidia’s monster can do 25.6 GOPS.
Intel makes up some ground if we test instruction rate with 500 million OpenCL threads like we did with cache bandwidth. For reference, FluidX3D’s most common kernel launches with 16 million threads, and a full-screen pixel shader at 4K launches 8 million threads. Our instruction rate test also gets over theoretical throughput, perhaps indicating that the compiler is eliminating some operations. We weren’t able to get to the bottom of this because we don’t have the profiling tools necessary to get disassembly from the GPU.
But even with what looks like an overestimate, AMD’s MI210 has a substantial lead in FP32 throughput if it can use packed operations. Intel can’t do packed FP32 execution but can execute 16-bit integer operations at double rate. FP16 operations can also execute at double rate, though only for adds. This is likely a compiler issue where the v0 += acc * v0 sequence couldn’t be converted into a FMA instruction.

PVC can boost throughput in other ways too. INT32 and FP32 operations can dual issue, giving a substantial performance boost if those operations are evenly mixed. This is true dual issue operation, unlike the claimed “dual issue” on post-Turing Nvidia architectures, where mixing FP32 and INT32 operations won’t get you increased throughput over INT32 alone. Nvidia’s “integer datapath” actually deals with INT32 multiplication. In that respect, PVC and Nvidia follow a similar strategy, and can do 32-bit integer multiplies at half rate. Intel likely carried this strategy over from their integrated graphics architectures. Gen 9 (Skylake integrated graphics) could also do half rate integer multiplication.

Finally, double precision floating point performance is an important differentiator for datacenter GPUs. Consumer grade cards can put up a decent performance in other categories especially considering their price, but generally lack competent FP64 hardware. PVC can do FP64 additions at full rate, but strangely couldn’t do so with FP64 FMAs. I wonder what’s going on here, because their Gen 9 architecture could do FP64 adds and FMAs at the same rate using the same test code.
(Macro) Benchmarks
FluidX3D (FP32)
FluidX3D uses the lattice Boltzmann method to simulate fluid behavior. It uses a variety of techniques to achieve acceptable accuracy without using FP64. Density distribution function (DDF) values are shifted into ranges where FP32 can provide enough precision. DDF summation uses alternating additions and subtractions to reduce loss of significance errors. The result is that FluidX3D can produce results very close to the FP64 “ground truth” while using FP32 operations that perform well on consumer GPUs. I’m using FluidX3D’s built in benchmark here.

Intel’s Max 1100 does not compete favorably against the current crop of compute GPUs from AMD and Nvidia. AMD’s similarly sized MI210 wins by more than 47%, while Nvidia’s giant H100 is three times faster. PVC performs closest to AMD’s RX 7900 XTX, showing that consumer graphics architectures can hit pretty hard in FP32 compute. RDNA 3 combines tremendous FP32 throughput, with caching capacity and memory bandwidth not far off PVC’s, so its performance isn’t a surprise.
Calculate Gravitational Potential
CGP is a workload written by Clamchowder. It does a brute force calculation of gravitational potential, given a map of column density. Code quality is roughly what you’d expect from a typical high school student working on a research project at 3 AM after doing the necessary things to have any chance at college admission (homework for 8 classes, studying for 9 APs, practicing two instruments, playing a sport, and definitely not getting the four hours of sleep recommended in the “sleep four hours pass, sleep five hours fail” saying). In other words, it’s completely unoptimized, and should represent what happens if you’re using hardware time to save human brain time.

Consumer GPUs suffer heavily in this workload because they don’t have a lot of hardware FP64 units, and PVC shows its worth. It’s twice as fast as AMD’s RX 6900 XT, and blows Nvidia’s consumer GA102 chip (A10) out of the water.
However, PVC struggles against recent datacenter GPUs, just as it did in FluidX3D. MI210 outperforms it by a staggering margin by natively handling FP64. H100 does as well, by simply being a massive GPU. PVC also takes a surprising loss to the older Radeon VII, which has a decent 1:4 FP64 ratio.
PVC’s Chiplet Setup
Now that we have an idea of how PVC performs, we can make a few observations on its chiplet setup. PVC’s chiplet setup is fascinating because Intel has chosen to use a more complex chiplet configuration than Zen 4 or RDNA 3. Chiplets are challenging, so that’s risky. Die to die interfaces create area overhead. Data movement between dies is often more expensive than doing so within a monolithic die. Vertically stacked dies can be harder to cool. Successful chiplet implementations mitigate these problems to enjoy cost benefits while suffering minimal performance degradation compared to a monolithic solution.
Lets go over these areas one by one, starting with area.
Area Overhead
Chiplets aim to reduce cost by letting engineers use cheaper process nodes when using better nodes would have limited benefit, and by using smaller individual dies to increase yield. However, chiplets will use more total area than an equivalent monolithic implementation due to duplicated logic and cross-die interfaces. Area overhead can also be more subtle. For example, Zen 4 uses a large and fast L3 cache to mitigate the latency and bandwidth hit of going through an IO die. The fast L3 takes up more die area on a Zen 4 CCD than the cores themselves.

On the area front, Ponte Vecchio uses a 640 mm2 base die. Rough pixel counting gives us the following for the Intel Max 1100:
| Die | Node | Contains | Area | Count | Total Area |
| Base | Intel 7 Foveros | Switch fabric, 144 MB of L2 cache, IO to HBM and peer GPUs | 640 mm2 | 1 | 640 mm2 |
| Compute | TSMC N5 | 8x Xe Cores | 40.31 mm2 | 8 | 322.47 mm2 |
| RAMBO | Intel 7 | Four 3.75 MB banks of extra L2 cache each | 14.17 mm2 | 4 | 60.66 mm2 |
| Xe Link | TSMC N7 | Cross-package links and switching logic | 74.12 mm2 | 1 | 74.12 mm2 |
One PVC GPU instance uses 1097 mm2 of total die area across various nodes, excluding HBM. I don’t think any RAMBO cache is enabled on the Max 1100, so we can also consider a 1036 mm2 figure for fairness. AMD’s MI210 uses a 724 mm2 die on TSMC’s N6 process and achieves better performance. Intel is therefore taking at least a 43-51% area overhead. I’m saying at least, because a substantial amount of area is using TSMC’s N5 node, which is more advanced than the N6 node used by AMD. If we use AMD Epyc’s 10% chiplet area overhead as a benchmark, PVC looks unbalanced.
Data Movement
Moving data between chiplets is often more challenging than doing so within a monolithic die. Old Nvidia research estimated 0.54 pj/bit of power draw for cross-chiplet links, but that paper did not consider 3D stacking. AMD showed that 3D stacking could allow massive bandwidth with very little power cost.

On Ponte Vecchio, compute tile to base tile communication would be the highest bandwidth cross-die interface. The L2 cache can provide several terabytes per second, and that’s handled by a 3D stacking interface well suited to such high bandwidth demands. Xe Link and HBM use 2D interfaces, but don’t deal with nearly as much bandwidth. Intel is using the best and highest bandwidth interfaces where they’re needed, making for a sound strategy here.
Cooling
PVC employs 3D stacking in spades. 3D stacking can reduce critical path lengths and package size, but can also create cooling challenges. AMD’s VCache addresses cooling by not stacking any logic over the cores. On my 7950X3D, the VCache CCD clocked 7% lower on average than the non-VCache one. AMD’s MI210 runs at 1.7 GHz, and thus clocks 9.7% faster than Intel’s Max 1100. That’s a problem. PVC puts its shaders on TSMC’s newer 5 nm node, and targets 300W just like MI210. If chiplets are delivering the benefits they’re supposed to, PVC should be pulling ahead.
Intel never published Ponte Vecchio’s die layout, but their slides indicate that IO interfaces are placed around the die edge (as is typical in many designs). IO interfaces shouldn’t get particularly hot, and are covered by “thermal tiles” with no other function other besides conducting heat.

If the compute tiles aren’t overlapping IO, they’re sitting on top of either cache or the switch fabric. Both of those would create heat, which would have to be dissipated through the hot compute tiles. That could exacerbate any hotspot issues within the compute tiles, and force the cooling solution to deal with more heat in the same surface area.
Zen 4 with VCache in comparison only sees a 7% clock speed penalty compared to a vanilla setup without 3D stacking. That’s largely because AMD avoided stacking any cache or logic on top of the CPU cores. In fact, most of VCache’s clock speed deficit appears to come from the vertically stacked cache not being able to handle high voltage, rather than thermal issues. Intel should adopt a similar strategy, and try to overlap compute with cache as little as possible. I don’t think this is an easy change because there’s a massive 144 MB of L2 on the base die, and the switching fabric is likely not small either.
RDNA 3’s chiplet strategy offers an alternative approach. 3D stacking is avoided in favor of putting cache on memory controller dies (MCDs), which use an interposer to get enough cross-die bandwidth. We saw earlier that Intel’s L2 isn’t too much faster than RDNA 3’s Infinity Cache. Certainly RDNA 3’s approach is not without compromises because it’ll make cache bandwidth more difficult to scale. But not all workloads will be bound by last level cache bandwidth, especially with 512 KB L1 caches in play. And higher clock speed could let PVC narrow the performance gap with AMD’s MI210.
Final Words: A Foot in the Door
Compute GPUs like Nvidia’s H100 and AMD’s MI210 push the boundaries of how fast we can process information and are among the most complex chips around. AMD and Nvidia are where they are today thanks to decades of experience building large GPUs. Intel may have a lot of money and good engineers, but they don’t have the same experience. Short of a miracle, their journey to build a big GPU will be an arduous one.
For their part, Intel made it even more arduous by using a chiplet setup with borderline insane complexity. From an outsider’s perspective, they seem to have looked at available nodes and packaging technologies, and decided all of the above would be appropriate. Doing this on any product would be risky, let alone a first entry into a new market.

Intel therefore deserves a lot of credit for not only getting the thing working, but creating a product that’s competent in isolation. Intel’s Max 1100 is a legitimately useful compute GPU capable of decent performance. It’s a far cry from the Moore Threads MTT S80, which uses a conventional monolithic die and fails to match a budget GPU from the Maxwell generation, while failing to run many games.
Of course, Intel has their work cut out for them. Landing between Nvidia’s old P100 and V100 GPUs is not where they want to be. PVC has plenty of weaknesses that Intel has to solve if they want to move up the performance ladder. L2 cache and VRAM latency are way too high. FP64 FMA throughput is curiously low, even in a microbenchmark. For the massive die area investment, PVC doesn’t bring enough compute power to draw even with AMD’s MI210.
With that in mind, Ponte Vecchio is better seen as a learning experience. Intel engineers likely gained a lot of experience with different process nodes and packaging technologies while developing PVC. PVC deployments like TACC’s Stampede3 and ANL’s Aurora supercomputers will give Intel real world performance data for tuning future architectures. Finally, innovations like a giant, expandable L2 cache give the Xe architecture unique flexibility.

Hopefully, we’ll see Intel take lessons and experience from Ponte Vecchio, and develop a stronger datacenter GPU in the coming years.
We would like to thank Intel for allowing us access to a Ponte Vecchio system along with answering some of our questions about Ponte Vecchio.
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.
Ivy Bridge’s Gen7 Graphics: Intel’s Modern iGPU Push
Intel has maintained an integrated graphics effort for a long time. The company’s integrated GPUs were not expected to do much beyond driving a display and offloading video decode. You could run games on them, but would probably be looking at poor framerates even at low quality and low resolutions. Ivy Bridge didn’t aim to change that fundamental picture, but it does represent a shift in Intel’s strategy towards creating a more flexible, programmable GPU.
In that sense, Ivy Bridge’s graphics architecture represents a turning point in Intel’s graphics strategy, introducing a solid foundation for Intel’s future graphics efforts. While Intel would not attempt to create a truly high performance graphics solution until nearly a decade later, Ivy Bridge graphics (also known as Gen 7) would pave the way for that effort.
I highly suggest reading Real World Technologies’s excellent article on Ivy Bridge’s graphics architecture, because it provides a lot of contemporary insight into the technology. My goal here is to supplement RWT’s analysis, instead of writing a full length article.
System Level
A Gen 7 iGPU is built from execution units (EUs), organized into subslices. A subslice contains private caches, texture units, and an interface to the rest of the GPU. In that sense, a subslice is most similar to AMD’s Compute Units (CUs) or Nvidia’s Streaming Multiprocessors (SMs). CUs and SMs form the basic building block of AMD and Nvidia’s GPUs, and those companies scale to very large GPUs. Gen 7 isn’t like that. Instead, it lets Intel tune GPU size in very small increments. Intel can adjust the EU count in each subslice, giving them a lot of flexibility to adjust very small GPUs. The equivalent would be adjusting the SIMD count within an AMD CU, or SMSP count within a Nvidia SM.

Gen 7’s shader array is backed by a GPU-wide cache, which Intel confusingly calls L3 (because each subslice has two levels of private texture caches). Unlike discrete GPUs, the iGPU interfaces to the host by being another agent on the CPU’s ring bus. From there, GPU memory accesses get treated a lot like regular CPU requests.
The Gen 7 Execution Unit
Gen 7’s EU is the smallest unit of compute execution. Instructions are fed in from a subslice-shared instruction cache. Then they enter a set of per-wave instruction queues, where they can be selected for execution. Every cycle, Gen 7’s scheduler can select a pair of waves to issue every cycle, to a pair of execution units. Both execution units support the most common operations, so Intel expects dual issue to be a regular mode of operation, rather than occasionally taking load off a primary compute pipeline as is done in Nvidia’s Maxwell and Pascal.

Once a pair of waves is selected for execution, their operands are fetched from the register files by the operand collector. This operand collector supports extremely sophisticated register file addressing. Most GPUs have instructions that directly address the vector register file via a register index. Intel is special and lets you use registers to address your registers. Gen 7’s vector register file supports register-indirect addressing via set of separate address registers. These address registers are 16 bits wide, and each wave can access eight of them, allowing register indirect register addressing for wave8 mode (but not wave16). Variable wave sizes are also supported at the instruction granularity. Each instruction can specify how many elements it wants to operate on and a register file region to get that data from, though terms and conditions may apply.

Unlike Nvidia and AMD, vector registers are not dynamically allocated. Each wave gets 128 registers, and the scheduler can track up to eight active waves. Using fewer registers does not allow increased occupancy, and there’s no way to use more registers per thread in exchange for lower occupancy.

Once instructions have finished getting their operands, they get to Gen 7’s two execution pipes. For legacy reasons, Intel names these the “FPU Pipe” and “EM Pipe”. EM stands for Extended Math, because that pipe originally only handled complex math operations like reciprocals and inverse square roots. Gen 7 augments that pipe so it can handle floating point additions and fused multiply-adds. In any case, Intel has a lot of execution resources on hand for special operations, and comparatively less for integer operations. INT32 instructions can only use the first pipe, and thus execute at half rate compared to FP32 instructions.

The HD 4000 is roughly comparable to Nvidia’s Quadro 600, which is a small implementation of Nvidia’s Fermi architecture. The Quadro 600 is often used to drive displays in systems without an integrated GPU, or to supplement an iGPU to provide more display outputs. Throughput is similar for basic FP32 operations, but Gen 7 has a large lead in special operations, as well as INT16 and INT8 throughput. These architectures are from a time when low precision throughput wasn’t prioritized, but it’s interesting to see Gen 7 doing a passable job there. Meanwhile, Nvidia has stronger integer multiplication performance, and can do 64-bit integer additions with less of a penalty.
Memory Access
Each Gen 7 subslice is responsible for feeding a gaggle of EUs, and has two-level sampler cache setup to help with that. Again, this contrasts with AMD and Nvidia designs, where there’s just a single level of texture caches in each basic GPU building block.

Instead of using direct memory access instructions, EUs use a ‘send’ instruction to send messages to subslice-level components. For example, global or local memory would be accessed by sending a message to the subslice’s data port. Texture accesses would similarly involve sending a message to the subslice’s sampler. Intel’s EUs are likely quite decoupled from subslice shared logic, while AMD’s SIMDs or Nvidia’s SMSPs are probably tightly integrated with CU or SM level hardware. This could be part of what enables GPU sizing at the EU level.
We can test the sampler caches with buffer accesses, via OpenCL’s image1d_buffer_t type. This type doesn’t support any sampler options, so the sampler simply has to act like a plain AGU and directly retrieve data from memory. Even with such simple accesses, hitting the L1 sampler cache takes an agonizing 141 ns. Latency slightly increases to 145 ns as we get into the L2 sampler cache.

Global memory accesses from compute kernels bypass the samplers and hit the iGPU-wide L3, likely because sampler accesses incur such devastatingly high latency even with sampler options off. The L3 can be accessed with just above 87 ns of latency. Nvidia’s Fermi enjoys slightly lower latency for small test sizes, but can’t match Intel’s combination of low latency and high caching capacity.

Gen 7’s L3 should have 256 KB of capacity, but some part of it will always be reserved for fixed function hardware. I’m testing Gen 7 on a Surface Pro. Because the iGPU is always connected to the built in display, there’s less L3 capacity available for GPU compute when compared to a desktop where the iGPU can be enabled without a display attached. Still, 128 KB of user-visible caching capacity compares quite favorably to small GPUs. Nvidia’s Quadro 600 only has 128 KB of last level cache, and Fermi’s L2 takes far longer to access.
VRAM latency is very well controlled on Intel’s iGPU. Both the Core i5-3317U and Nvidia’s Quadro 600 use a dual channel DDR3-1600 memory setup, but Fermi’s memory latency is far worse. Intel likely benefits from a very latency optimized memory controller, since CPUs are very latency sensitive.
Local Memory
GPUs typically have fast scratchpad memory that offers an alternative to the slower global memory hierarchy. With OpenCL, this memory type is called local memory. AMD and Nvidia GPUs back local memory with fast building-block-private blocks of SRAM. AMD calls this the Local Data Share (LDS), while Nvidia calls it Shared Memory. Gen 7 does not do this. Local memory is allocated out of the GPU’s L3 cache, so latency isn’t the best. It’s a touch better than accessing the L3 as a regular cache, because there’s no need for tag or status checks.

Nvidia also has a block of memory serve double duty as cache and local memory. But that memory is private to a SM and can be accessed quickly. Fermi therefore enjoys far better local memory latency.
Atomics
Atomics can be used to synchronize different threads running on the GPU, and exchange values between threads. Here, we’re testing OpenCL’s atomic_cmpxchg function, on both global and local memory. Typically, a GPU will see far lower thread-to-thread latency when testing with local memory, since that’s roughly analogous to passing data between sibling threads on a SMT-enabled CPU. However, Gen 7’s local memory isn’t local to a subslice, so we don’t see a particularly large latency difference between local and global atomics.

Nvidia’s Fermi is much slower at handling atomics. Atomics on local memory take much longer than uncontested accesses, suggesting the SMs don’t have particularly fast synchronization hardware. There’s also a huge penalty for going to global memory, even though there are only two SMs on the Quadro 600.
Bandwidth
High performance GPUs tend to be quite bandwidth hungry, and can pull hundreds of gigabytes per second from caches and VRAM to feed their giant shader arrays. Gen 7 is not designed for that. Its GPU-level L3 can still deliver a decent amount of bandwidth though, and compares favorably to Nvidia’s tiny Fermi.

As with any integrated GPU, Gen 7 shares a memory controller with the CPU. In this case, it’s a dual channel DDR3 controller capable of providing 25.6 GB/s. Nvidia’s Quadro 600 has exactly the same, so its only advantage to being a discrete GPU is that it won’t have to fight with the CPU over memory bandwidth.

Bandwidth is low, but that’s expected for a low end GPU of the era. There’s not a lot of compute power to feed on either GPU, so bandwidth bottlenecks shouldn’t be a huge issue.
Link Bandwidth
Integrated GPUs tend to have an advantage when moving data between CPU and GPU memory pools, because the memory pools are physically the same. Intel’s architecture in particular lets the CPU and GPU pass data through the L3 cache. Future Intel iGPUs could get massive bandwidth with small copies between the CPU and CPU, but that didn’t happen until Skylake’s Gen 9 graphics.

When using OpenCL to copy data between the CPU and GPU, both the HD 4000 and Nvidia’s Quadro 600 perform poorly. Nvidia’s card has a PCIe 2.0 x16 link to a FX-8150, via a 990FX chipset. It should be good for up to 8 GB/s of bandwidth, but I don’t get anything close. The HD 4000 should have a 32 byte/cycle interface to the ring bus, which is good for an order of magnitude more bandwidth. Unfortunately, this capability doesn’t shine until a couple of generations later.
Final Words
Despite a few high profile failures like i740 and Larrabee, Intel is no stranger to graphics. While ATI/AMD duked it out with Nvidia at the top end, Intel’s integrated GPUs quietly kept a huge chunk of the computing world running. These iGPUs didn’t have the power for serious gaming, but Intel was never far behind in terms of implementing the features required to run modern games. Gen 7 was part of an effort to keep Intel’s Gen line up to date. It introduces DirectX 11 support, and does a competent job at handling compute code. In doing this, it set a solid hardware foundation for Intel’s future graphics ambitions.

Features from Gen 7 continue to show up today. Subslices may have been renamed to Xe Cores, and EUs are now called Vector Engines. But Intel still has more internal subdivisions in their Xe Cores than AMD and Nvidia have in their equivalent blocks. Occupancy on Intel GPUs is still unaffected by register usage, with 128 registers per thread and 8 threads per EU (or Vector Engine). Ponte Vecchio introduces a “Large GRF” mode where a thread can have 256 registers while occupancy per EU drops to 4 threads, but the connection to Gen 7 is still there.
Thus, Intel’s latest foray into discrete graphics wasn’t out of the blue. Instead, it’s built on years of experience working on and improving the Gen architecture. Larger integrated GPUs like the ones in Ice Lake and Tiger Lake helped Intel develop more confidence, until they felt ready to go big. But building huge GPUs that deal with teraflops of compute and terabytes per second of bandwidth is quite outside Intel’s comfort zone. None of their integrated graphics experience would prepare them for such a task. Something as big as Ponte Vecchio will be very interesting to look at
If you like our articles and journalism, and you want to support us in our endeavors, then consider heading over to our Patreon or our PayPal if you want to toss a few bucks our way. If you would like to talk with the Chips and Cheese staff and the people behind the scenes, then consider joining our Discord.

You’re the OS is a game that will make you feel for your poor, overworked system
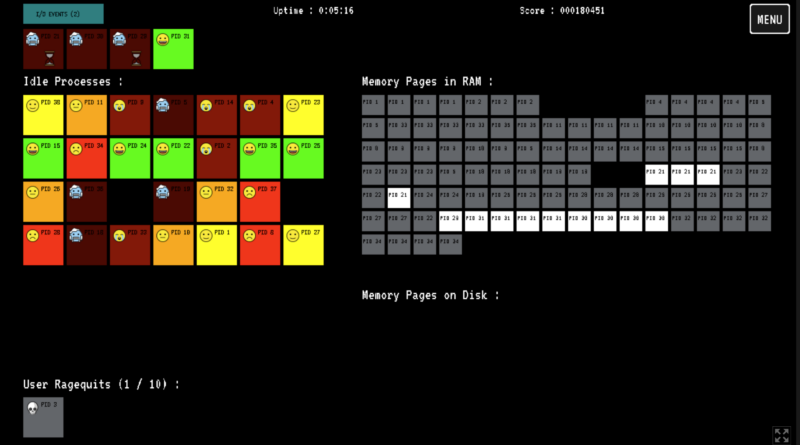
Enlarge / If I click the "I/O Events" in the upper-left corner, maybe some of the frozen processes with a little hourglass will unfreeze. But how soon? Before the other deep-red processes die? I can't work under these conditions! (credit: Pier-Luc Brault)
I spent nearly 20 minutes this morning trying to be a good operating system, but you know what? People expect too much of their computers.
I worked hard to rotate processes through CPU slots, I was speedy to respond to I/O requests, and I didn't even let memory pages get written to disk. But the user—some jerk that I'm guessing keeps 32 shopping tabs open during work—kept rage-quitting as processes slid in attrition from bright green to red to "red with a frozen face emoji." It made me want to get four more cores or potentially just kill a process out of spite. If they were a writer, like me, I'd kill the sandboxed tab with their blog editor open. Learn to focus, scribe!
You're the OS! is a browser game that combines stress, higher-level computer design appreciation, and panic-clicking exercise. Creator Pier-Luc Brault says specifically that the game "has not been created with education in mind," but it might introduce people to principles like process scheduling and memory swapping—"as long as it is made clear that it is not an exact depiction." Brault, a computer science teacher himself, writes that they may use the game to teach about cores, RAM shortages, and the like.
Intel Gets Hogwarts Legacy Running On Linux Driver By Pretending Not To Be Intel Graphics
A jargon-free explanation of how AI large language models work

Enlarge (credit: Aurich Lawson / Ars Technica.)
When ChatGPT was introduced last fall, it sent shockwaves through the technology industry and the larger world. Machine learning researchers had been experimenting with large language models (LLMs) for a few years by that point, but the general public had not been paying close attention and didn’t realize how powerful they had become.
Today, almost everyone has heard about LLMs, and tens of millions of people have tried them out. But not very many people understand how they work.
If you know anything about this subject, you’ve probably heard that LLMs are trained to “predict the next word” and that they require huge amounts of text to do this. But that tends to be where the explanation stops. The details of how they predict the next word is often treated as a deep mystery.
The IBM mainframe: How it runs and why it survives

Enlarge / A Z16 Mainframe.
Mainframe computers are often seen as ancient machines—practically dinosaurs. But mainframes, which are purpose-built to process enormous amounts of data, are still extremely relevant today. If they’re dinosaurs, they’re T-Rexes, and desktops and server computers are puny mammals to be trodden underfoot.
It’s estimated that there are 10,000 mainframes in use today. They’re used almost exclusively by the largest companies in the world, including two-thirds of Fortune 500 companies, 45 of the world’s top 50 banks, eight of the top 10 insurers, seven of the top 10 global retailers, and eight of the top 10 telecommunications companies. And most of those mainframes come from IBM.
In this explainer, we’ll look at the IBM mainframe computer—what it is, how it works, and why it’s still going strong after over 50 years.
Intel Arc Graphics Enjoy Nice ~10% Speedup With Recent Open-Source Linux Driver
Intel's Core Brand Change
In this article:
One of the significant mainstays of modern branding for personal computers has been Intel. We all remember Intel Inside, Intel Celeron, Intel Pentium, and perhaps less pervasive but more widely spread, Intel Core. To go along with the Core architecture, Intel Core has been placed on pretty much every CPU Intel has produced that wasn't …

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Diablo IV — O inferno está chegando!
Manter uma série viva e relevante por mais de duas décadas não é uma tarefa simples e quando ela carrega consigo alguns dos fãs mais exigentes da indústria, qualquer escolha tomada pelos criadores poderá se transformar numa enorme tempestade. Mas se com o antecessor a Blizzard inicialmente desagradou muita gente, o Diablo IV está chegando para mostrar que apostar na segurança pode ser uma ótima ideia.
- Diablo: como a franquia da Blizzard marcou o gênero ARPG
- Company of Heroes 3 — A guerra sob controle

Crédito: Divulgação/Blizzard Entertainment
Diablo IV inicia falando sobre uma antiga lenda, uma sobre o mundo de Santuário ter sido criado pela união entre um anjo — Inarius — e um demônio — Lilith. A ideia deles era criar um refúgio para aqueles que não quisessem se envolver na guerra entre o céu e o inferno, cabendo à humanidade aproveitar o lugar para construir cidades e a civilização em si.
Porém, após os eventos mostrados no final do Diablo III: Reaper of Souls, o vácuo deixado no poder fez com que demônios voltassem a aterrorizar Santuário e temendo que a paz acabasse, alguns cultistas decidem libertar Lilith. O problema é que por onde passa, a filha de Mephisto causa o mal, causando medo, ira, despertando impulsos reprimidos e o desejo por cometer pecados.
O lado positivo de tudo isso é que, ao mesmo tempo, em que o mal está tomando a região, nosso personagem se aproxima, então, adivinhe para quem sobrará a tarefa de dar um jeito em Lilith e seus asseclas?
Pois essa será a premissa para voltarmos a aniquilar milhares de monstros, alguns chefes cascas-grossas e coletar os mais variados equipamentos, transformando o nosso herói numa verdadeira máquina de matar. E acredite, quando se trata de conteúdo, Diablo IV não deverá te deixar na mão.
Um mundo (aberto) de possibilidades

Crédito: Divulgação/Blizzard Entertainment
Ao todo o jogo estará dividido em cinco grandes regiões, sendo elas: a congelada Cimeiras Fraturadas; a floresta habitada por Druidas e seres aquáticos, conhecida como Scosglen; a região desértica das Estepes Secas, onde canibais serão uma terrível ameaça; ainda poderemos visitar Kehjistan, um lugar devastado por uma guerra; e por fim, teremos Hawezar, um pântano repleto de bruxas e monstros até mais aterrorizantes.
Embora oferecer regiões variadas não seja inédito na série, o grande diferencial do Diablo IV está na maneira como isso foi feito. Agora, todas elas estão dispostas num mesmo mapa, formando um grande mundo aberto. Assim, poderemos viajar de um lugar para o outro sem haver transições, com todas as cidades, masmorras e pontos de interesse estando disponíveis assim que chegarmos a Kyovashad, a grande cidade que nos servirá como base.
Isso quer dizer que, se o jogador preferir abandonar os dois primeiros atos e partir logo para o terceiro, poderá fazer isso. O interessante é que da maneira como o roteiro foi criado e como a narrativa funciona, não teremos problemas de a história parecer estar atropelando eventos que nem chegamos a ver. Eu ainda acho que o ideal é fazer as missões na ordem correta, mas aqueles que não quiserem encarar todo o Ato 1 por já terem feito isso nos períodos de beta, terão essa liberdade.

Crédito: Divulgação/Blizzard Entertainment
E por falar em missões, em Diablo IV esbarraremos numa nova a quase todo momento. No geral essas missões paralelas se resumem a levarmos um item de um ponto A até um ponto B, resgatar alguém ou entregar um recado. Confesso que gostaria de ter visto uma maior variedade de tarefas, mas o que realmente me incomodou foi o limite de missões ativas, apenas 20. Felizmente é possível abandonar uma delas e depois reativá-la, mas com tantas estando disponíveis, essa é uma limitação que considero desnecessária.
Ainda assim, o título tenta entregar atividades um pouco diferentes de tempos em tempos, como as masmorras que nos darão poderes especiais ou as Fortalezas, que se mostrarão desafios bem acima da média. A vantagem é que ao tomarmos um desses lugares a cidade passará a ser pacífica, oferecendo comerciantes, missões e pontos de teletransporte.
Outra dessas atividades está nos arredores da cidade de Alzuuda. Será lá que poderemos participar do PvP, sendo que os comerciantes só aceitarão uma moeda local, as Sementes do Ódio. Conquistadas após as batalhas daquela área, o detalhe é que para podermos aproveitar essas sementes elas precisarão passar por um dos quatro Altares de Extração, onde viraremos o alvo dos inimigos e uma tensão crescente se instaurará.
Como a quantidade de pessoas experimentando o jogo nesses últimos dia era algo muito limitada, não tive a oportunidade de enfrentar ninguém ali. Contudo, a zona dedicada ao PvP deverá ser bastante movimentada quando o Diablo IV for lançado e para quem quiser alguns dos itens oferecidos nas lojas de Alzuuda, será inevitável se aventurar por lá.

Crédito: Divulgação/Blizzard Entertainment
Aqui vale mencionar o sistema cosmético presente no novo jogo da Blizzard. Isso porque, além dele nos dar acesso à transmogrificação desde o início da campanha, ainda teremos uma loja dedicada às microtransações. Sei que essa palavra não costuma ressoar muito bem entre os jogadores, mas a desenvolvedora garante que ali só teremos itens cosméticos. Ainda assim, será triste cruzar com algum jogador com um visual muito bacana e saber que só podemos ter algo assim se abrirmos a carteira.
E para quem estava ansioso para ver como funciona o cavalo, as notícias são boas e ruins. Estreando na franquia, os equinos serão de grande ajuda para atravessamos Santuário, devido sua velocidade de locomoção, mas não espere lutar contra inimigos quando estiver montado neles. A única opção neste caso será desferirmos um golpe apertando quadrado/X, o que poderá ser útil em algumas situações, mas automaticamente nos deixará a pé.
A dica que posso deixar para aqueles que quiserem desbloquear o cavalo é: não se preocupe com isso. Infelizmente o bicho só estará disponível após um determinado ponto (bem avançado) da campanha principal, outra escolha de design que questiono, mas o fato é que não haverá meios de acelerar esse processo. Curta a história, faça a maior quantidade possível de missões e fique tranquilo, que uma hora ele aparecerá.
O despertar dos mortos

Crédito: Divulgação/Blizzard Entertainment
Como o meu contato anterior com o Diablo IV havia acontecido apenas no primeiro beta, eu não pude experimentar a classe que sempre escolho quando disponível, o Necromante. Mas com o devido acesso à versão completa do jogo, pude evoluir meu personagem até desbloquear todos os nós de sua árvore de habilidade e fiquei feliz com o que vi.
Conforme o invocador dos mortos se torna mais poderoso, encarar as masmorras e chefes é a certeza de raramente estarmos sozinhos. Podendo arrastar um pequeno exército de esqueletos e até um golem, consegui entender por que algumas pessoas apontavam essa como uma das classes mais poderosas do jogo.
O grande problema aqui é que para invocar um morto-vivo o necromante precisa ter acesso a um corpo largado sempre que um inimigo é derrotado. Porém, como alguns chefes nos enfrentarão boa parte do tempo sozinhos, a possibilidade de ficarmos sem os companheiros ossudos é grande e neste caso, o personagem deixará de ser tão forte.
No caso de não estarmos jogando sozinhos, isso poderá ser contornado com a ajuda de amigos, principalmente se eles forem bons no combate corpo a corpo, deixando assim espaço para realizamos ataques a distância. De qualquer forma, não pense que um necromante de alto nível será invencível, mas que é bonito vê-los criando zonas contaminadas e aproveitando os seguidores de Lilith contra ela mesma, isso é.

Crédito: Divulgação/Blizzard Entertainment
Por fim, foi ótimo ter acesso a um jogo que está rodando tão bem, sem bugs e com uma qualidade visual estupenda no PlayStation 5. Isso deveria ser o comum, mas numa época em que temos visto lançamentos tão problemáticos, foi gratificante ver que o Diablo IV recebeu toda a atenção necessária.
Também me agradou constatar o quanto o jogo poderá nos manter entretidos, dada a quantidade de conteúdo que já estará disponível no primeiro dia e das atualizações que ele receberá. Só para começar, estamos falando de mais de 120 masmorras cujos laytous são gerados aleatoriamente; da promessa de um end-game robusto e das cinco classes, que entregam jogabilidades bem diferentes entre si. Isso sem falar no cross-save e cross-play, nas partidas cooperativas online entre até quatro pessoas e no bom e velho multiplayer de sofá (apenas nos consoles e limitado a dois jogadores).
Portanto, se você gosta da franquia e está procurando algo para se manter ocupado por semanas, talvez até meses ou anos, o Diablo IV permitirá isso e, apesar de algumas novidades, mantendo-se fiel às suas raízes.
Sobre Arqueologia digital, NASA e óleo de baleia
Arqueologia digital soa como a base de alguma piada, afinal, um ramo da tecnologia que ainda está engatinhando, como assim já tem uma “arqueologia”? Na prática eu diria que até já passou da hora.
- Cinco hábitos que a tecnologia simplesmente dizimou
- Mais incômodos tecnológicos que já não existem mais

Arqueologia digital, na visão da Inteligência Artificial (Crédito: Stable Diffusion)
A informação que guardamos em meios eletrônicos é bem acessível, em grande maioria são textos, imagens, vídeos e sons, e essa informação é relativamente atemporal. Sem esforço dá pra ler um relatório sobre “melhoramentos nos portos do Brasil”, publicado em 1875.
Na prática, não é tão simples, tenho um bom exemplo: Alguns anos atrás um amigo pediu ajuda para converter vídeos que havia feito do filho, usando uma QuickCam original, algo parecido com isto:

Uma Quickcam, das pré-históricas (Crédito: Reprodução Internet)
Ela usava porta paralela, gravada a 15fps, 320x240, 16 tons de cinza e em um formato maldito que não existe documentação em lugar nenhum. Eu pesquisei semanas e não consegui converter o arquivo. E eu já tinha o maldito em mãos, poderia ter sido bem pior, nível NASA.
Antes da Apollo XII, a NASA mandou um monte de sondas para fotografar e estudar possíveis locais de pouso. Essas sondas usavam filmes de 70mm, que eram revelados e escaneados dentro da própria sonda, com as imagens transmitidas para a Terra.
Essas imagens eram gravadas em fitas de grande largura de banda, um equipamento altamente especializado. Com as imagens e dados convertidos para formatos mais práticos (e de menor resolução), as fitas foram esquecidas, e muito rapidamente a NASA não tinha mais os gravadores Ampex FR-900 capazes de reproduzi-las. Aos poucos elas foram deixadas de lado, muitas se perderam e só em 2007 um grupo descobriu 1500 fitas em um arquivo da NASA e -mais importante- uma ex-funcionária que tinha algumas fitas e um FR-900 em um galpão.

Uma das duas unidades de fita de instrumentação Ampex FR-900 localizadas nas instalações do Lunar Orbiter Image Recovery Project (Crédito: Misternuvistor / LOIRP)
Foi fundado o Lunar Orbiter Image Recovery Project, que conseguiu recuperar 2000 imagens, trabalhando em um McDonald’s abandonado, tendo que consertar os gravadores que conseguiram encontrar. E estamos falando de equipamentos de meados da Década de 1960. Um dos problemas foi achar um equivalente sintético ao óleo de baleia que a Ampex usava para lubrificar os gravadores.
No final, o projeto deu certo, e as imagens recuperadas foram muito melhores que tudo que a NASA havia divulgado na época das sondas.
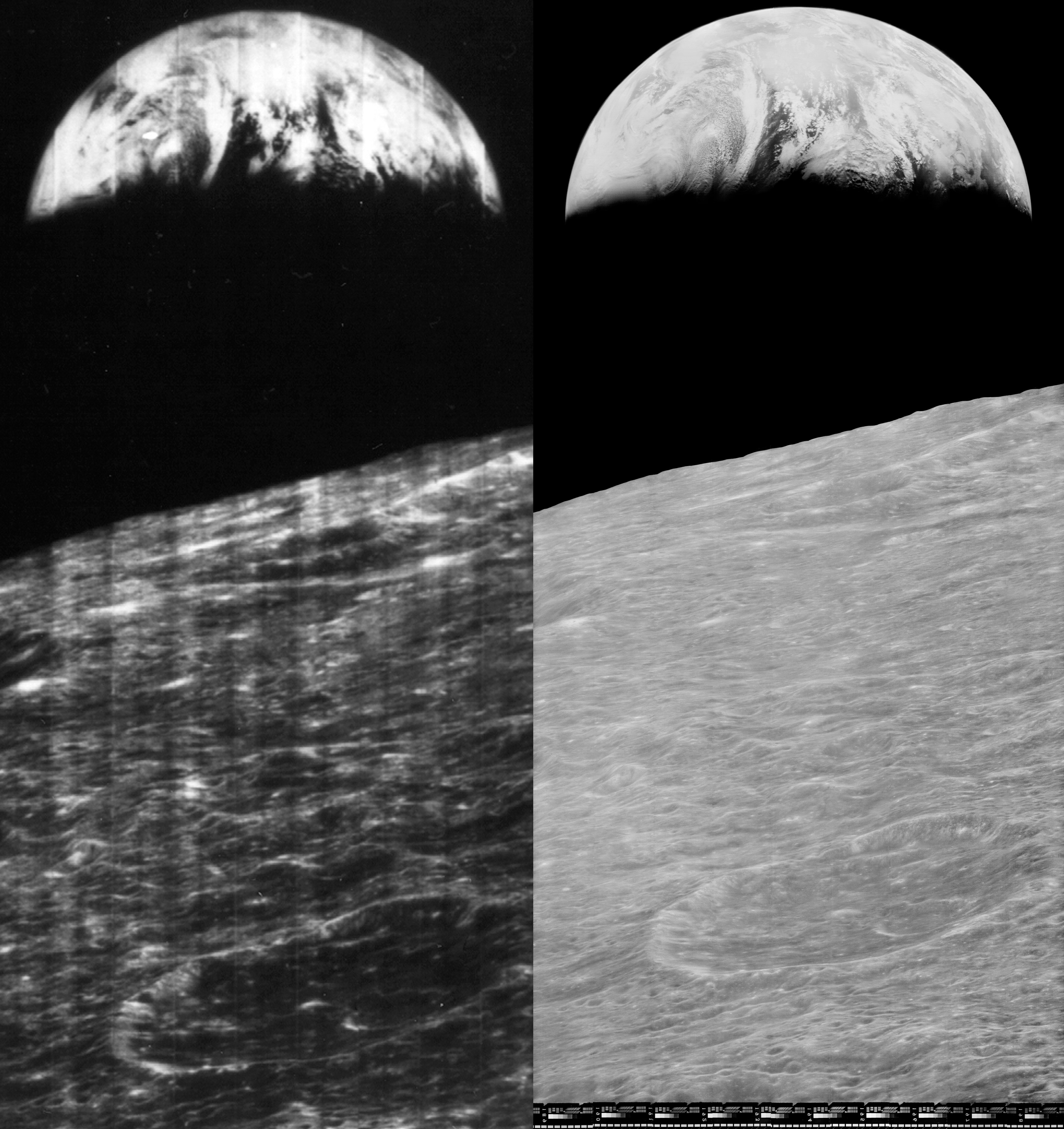
Na esquerda, imagem divulgada pela NASA. Na direita, imagem recuperada pelo LOIRP das fitas esquecidas (Crédito: LOIRP)
Nem todo caso é bem-sucedido, e o tempo torna cada vez mais difícil esse tipo de arqueologia digital. Tenho textos em disquetes de 5¼ do tempo de meu 386 que só conseguiria recuperar após investir uma grana considerável. Muitas empresas têm fitas de backup gravadas em drives que não mais existem, não são mais fabricados e estão desaparecendo dos eBays da vida.
Quanta gente ainda tem CD-Players em casa? Ou player para fitas K-7? Ou computador com porta paralela?
Nossos PCs não têm mais slots ISA-8, ISA-16, VESA Local Bus, AGP ou mesmo PCI. Também não há mais interface para disquetes, nem IDE. Qualquer equipamento que dependa dessas conexões, se torna inacessível.

Um Zip Drive com conexão SCSI. Isso faz qualquer um de TI chorar, pensando no trabalho que daria para fazer funcionar (Crédito: Reprodução Internet)
No campo do armazenamento externo, hoje estabilizamos no MicroSD e nos flashdrives USB, mas quantos dados perdidos pelo mundo ainda há em: CompactFlash, Memory Stick, XD Picture Card, CFast, XQD, MultiMediaCard, SmartMedia, MiniSD, Microdrive, RS-MMC, Miniature Card, SxS (S-by-S), P2 (Professional Plug-in), Secure Digital miniSD (miniSDHC), Secure Digital microSD (microSDHC, microSDXC), Secure Digital Extended Capacity (SDXC), Secure Digital High Capacity (SDHC), TransFlash (T-Flash), Memory Stick PRO-HG Duo, Memory Stick Duo, Memory Stick PRO Duo, Memory Stick Micro (M2), MMCmicro, DV RS-MMC, MultiMediaCardmobile (MMCmobile), MultiMediaCardmicro (MMCmicro), Intelligent Stick (iStick), C-Flash, Picture Card, SecureMMC, DV RS-MMC, Secure Digital Reduced Size ou MultiMediaCard (SDRSMMC) ?
Quem acompanha o excelente canal Techmoan sabe que toda semana ele desencava um formato de vídeo ou áudio obscuro, de gravadores de brinquedo a câmeras de vídeo que usavam fitas k-7, incluindo coisas como o DataPlay, esse disquinho de 2002 que acondicionava respeitáveis 500MB por disco.
Agora pense em acervos de videotecas, emissoras de TV e colecionadores, sem dinheiro ou tempo para ser digitalizados, enquanto os equipamentos capazes de reproduzi-los se deterioram dia-a-dia.

Cartuchos DataPlay. Olha que coisa mais fofa! (Crédito: Divulgação)
Com eles, perde-se a informação de como os dados estão armazenados. Esses sinais analógicos ou digitais não são simples imagens em um filme cinematográfico, algumas técnicas bem criativas são utilizadas para contornar restrições tecnológicas. Nos videocassetes, por exemplo, o sinal de vídeo exige mais banda do que cabe na largura de uma fita normal. A solução seria aumentar o tamanho da fita, mas não era o que os projetistas queriam, ela deveria ser menor que uma fita U-Matic ou outros modelos profissionais.
A solução? Eles inclinaram as cabeças de gravação, assim o sinal de uma linha inteira de imagem podia ser gravada de uma vez, em uma fita mais estreita.
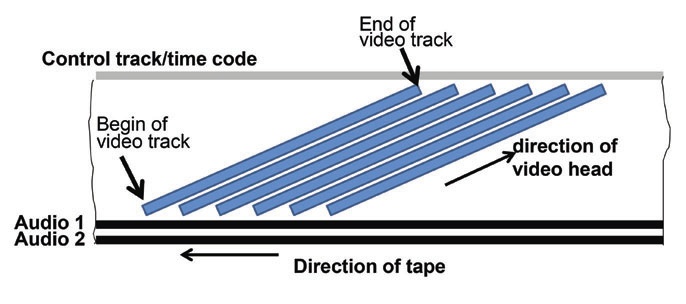
De ladinho é mais gostoso, diriam os engenheiros da JVC (Crédito: Reprodução Internet)
Em um mundo ideal todos os antigos arquivos seriam digitalizados e disponibilizados em bancos de dados online, de forma agnóstica, ou seja, independente da mídia física original. Na prática assim como acabar com a fome do mundo, não há dinheiro no mundo pra isso.
Em 2020 a chamada Datasfera, a soma dos dados armazenados e criados no mundo, era de 59 Zetabytes. (1 Zetabyte = 1 trilhão de Gigabytes). A projeção para 2025 é que esse número chegue a 175 Zetabytes.
Isso, claro, sem levar em conta os dados ainda em formatos analógicos, como programas de TV, gravações, revistas, jornais, cartas, mapas, objetos em museus, rótulos de xampu e todo o resto.
Antes que alguém faça analogias com a Pedra da Roseta e outros documentos clássicos, como a tabuleta de Ea-nasir, é bom lembrar que pedra é um tanto inviável como meio de preservação de dados quando trabalhamos em Zetabytes.

Tábua de Ea-Nasir, circa 1750 AC, considerada a primeira reclamação de consumidor. Na Babilônia um sujeito chamado Nanni escreve para um comerciante chamado Ea-Nasir reclamando da qualidade dos lingotes de cobre que ele havia vendido (Crédito: Museu Britânico)
E não, ainda não há um meio físico digital imune ao tempo. Os CD-ROMs surgiram com a promessa de que durariam 100 anos, mas todo mundo já viu um CD sucumbir aos fungos ou à qualidade xing-ling, descascando feito uma sueca em Copacabana com poucos anos de uso. (O CD, não a sueca)
Os futuros praticantes de arqueologia digital terão dois grandes problemas: Encontrar, reconstruir reformar ou simular hardware compatível com os dispositivos e armazenamento, e talvez a parte mais complicada, criar o software para entender e traduzir os formatos.
Software é algo que depende de cultura, mesmo com especificações muita coisa é deixada implícita, pois é algo que “todo mundo sabe”, e 50, 100 anos depois esse conhecimento comum provavelmente não existirá mais.
Há línguas que hoje não conseguimos decifrar. Linear A, uma linguagem escrita usada em Creta, entre 1800 e 1450 AC é uma delas. Sabemos que é baseada em grego arcaico, é muito parecida com Linear B, que já foi decifrada, mas nada se encaixa.
Em computação, formatos caem em desuso rapidamente. Hoje em dia é virtualmente impossível achar documentação sobre o Carta Certa, um raro bom software nacional, fez muito sucesso algumas décadas atrás, tinha acentuação, capacidade de formatação WYSIWYG com um sistema de tags parecido com o ainda não-inventado HTML, e muito mais. Converter um arquivo em Carta Certa para Word seria no mínimo trabalhoso.
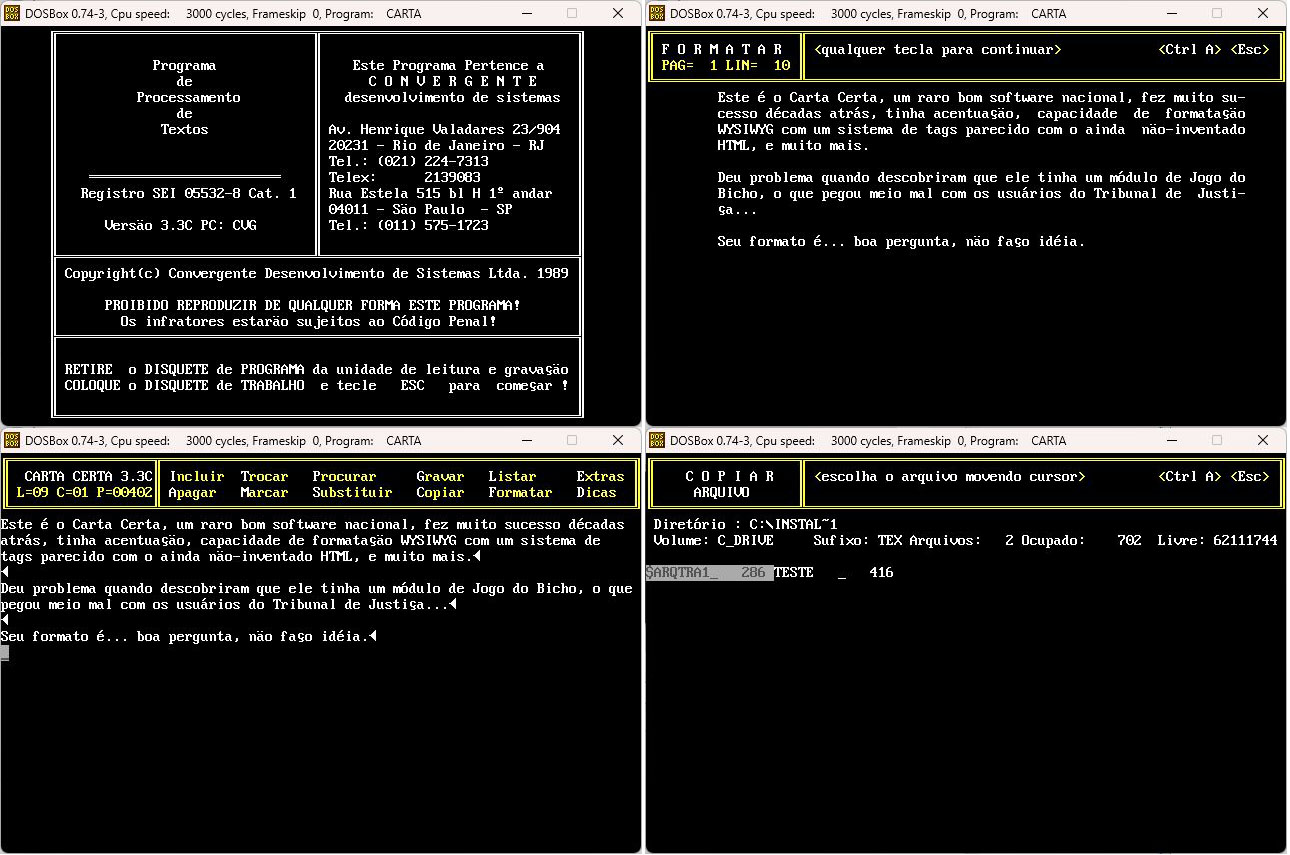
Sim, dá pra rodar o Carta Certa no DOSBox (Crédito: Meio Bit)
Outros formatos, como imagens em PCX são piores ainda, e nem quero imaginar o trabalho de converter algo como um arquivo do Ventura Publisher ou Pagemaker.
Conclusão:
Mantenha seus arquivos em formatos digitais e atualizados, mesmo que isso tenha um alto custo inicial. Invista em backups, locais e em nuvem, e exporte os arquivos para múltiplos formatos, independente do formato original ser proprietário ou não.
Se você for desenvolvedor, documente fartamente seus formatos de arquivos, tente depender o mínimo de bibliotecas externas, e nunca assuma nada. Imagine que está escrevendo para alienígenas, explique mesmo os truques mais básicos.
Do contrário em 500 anos ninguém vai ser capaz de ver todas as fotos do almoço que a gente tirou pro Instagram.
Bug Bounty Programs May Sound Great, But Aren't Always Handled Well
Starship - A história do foguete mais poderoso do mundo
Parece que foi ontem, mas foi em 2012 que a Starship teve seu primeiro anúncio oficial, ainda com o ambicioso nome Mars Colonial Transporter. De lá pra cá muita água rolou debaixo da ponte.
- Starship da SpaceX vai dar a volta ao mundo, mas é só um teste
- Polaris: O mais ambicioso programa espacial privado de todos os tempos

Starship e Super Heavy (Crédito: SpaceX)
A SpaceX tem a nem um pouco ambiciosa meta de tornar a Humanidade uma espécie interplanetária, mas eles sabem que é inviável para qualquer empresa montar uma colônia fora da Terra, então a estratégia (do grego Strategos) deles é simples: Criar uma infra-estrutura de transporte com um custo tão baixo que entidades interessadas em colonizar outros mundos se sintam tentadas a contratar o carreto da SpaceX.
Para chegar nesse ponto, a SpaceX precisava de fluxo de caixa positivo, o que conseguiu com o Falcon 9. Existe uma percepção que a SpaceX destruiu vários até acertar, mas o Falcon 9 foi bem-sucedido em seu primeiro vôo.
Todo aquele show pirotécnico aconteceu nas tentativas de pouso, depois que o Falcon 9 já havia cumprido sua missão e colocado sua carga em órbita.
Os números, são impressionantes. Na metade de abril de 2023 foram lançados 223 foguetes Falcon 9. Desses, 221 foram missões bem-sucedidas. Uma foi perda total, uma sucesso parcial e um explodiu durante um teste estático. Hoje o Falcon 9 é o foguete mais confiável já construído.
Depois que dominou a técnica de pouso, o custo de lançamento do Falcon 9 caiu mais rápido que um Falcon 9 antes da SpaceX dominar a técnica de pouso, e conseqüentemente, a reutilização do primeiro estágio. Isso tornou possível a Starlink, uma das muitas propostas de mega-constelação para fornecimento de acesso Internet em qualquer lugar do planeta.
O conceito em si é simples, mas uma constelação com dezenas de milhares de satélites demanda lançamentos constantes, e mesmo que você seja dono de uma empresa de lançamentos espaciais, a conta não fecha.
Com o foguete reutilizável, a SpaceX conseguiu viabilizar a primeira fase da Starlink, que está salvando vidas na Ucrânia, irritando o Irã e mudando o dia-a-dia de centenas de milhares de pessoas morando em regiões remotas, além de prover acesso para aviões, navios, plataformas de petróleo e pinguins.

Starlink na Antártica (Crédito: COLDEX)
Segundo Gwynne Shotwell, Presidente da SpaceX, tecnicamente a Starlink já tem fluxo de caixa positivo, mas os satélites versão 2.0, necessários para atender a demanda, são maiores, mais pesados e não são economicamente viáveis nem com o Falcon 9. Vamos precisar de um foguete maior.
Um foguete maior
A SpaceX desde o início planejava foguetes maiores. Inicialmente iriam fazer um mini-Falcon Heavy, com três Falcon 1 conectados, mas o plano foi cancelado. Quando o Falcon 9 começou a ser desenvolvido, junto veio a idéia do Falcon Heavy, em 2005, sendo que o Falcon 9 só viria a voar pela primeira vez em 2010, mesma época em que internamente a SpaceX se convencia que precisava de um foguete maior que o Falcon Heavy.
Há relatos de disputas internas, com Gwynne Shotwell tendo que defender o Falcon Heavy. Elon Musk queria cancelar o projeto e se dedicar ao tal Foguete Maior, mas Gwynne acertadamente mostrou que o desenvolvimento já estava adiantado, inclusive com vários lançamentos já vendidos.
Convencido, Elon mandou tocar adiante o desenvolvimento, e em 2018 o Falcon Heavy fez seu primeiro e espetacular lançamento, colocando em órbita solar um Tesla Roadster, usado para simular uma carga útil. Normalmente as empresas usam blocos de concreto, mas a SpaceX tem estilo.
Junto com o foguete, estavam sendo desenvolvidos os motores Raptor, extremamente potentes e ao contrário dos motores tradicionais, não usavam RP-1 (um tipo de querosene refinado), mas metano como combustível. Com fórmula CH4, metano é uma das moléculas orgânicas mais simples, um gás inflamável em temperatura ambiente, com uma queima bem mais limpa que querosene:
CH4 + 2O2 → CO2 + 2 H2O
Ao invés de um monte de fuligem, hidrocarbonos, nitróxidos e outros lixos, metano tem como resíduo de sua queima uma molécula de dióxido e carbono e duas de... água. Só perde para hidrogênio, cujo único resíduo é água, mas hidrogênio é um inferno para armazenar e manipular.
Além da facilidade de manipulação e queima limpa, e do custo bem mais baixo que RP-1, metano tem mais uma vantagem: Ele pode ser produzido em Marte, o que é essencial para os planos da SpaceX.
Mais ainda: Nem é uma tecnologia nova, foi descoberta por Paul Sabatier e Jean-Baptiste Senderens em 1897, e batizada de Reação Sabatier.
A fórmula da reação é bem simples também:
CO2 + 4H2 → CH4 + 2 H2O
Dióxido de carbono e hidrogênio, a 400 graus Célsius de temperatura e 3Megapascals de pressão, na presença de um catalizador de níquel se transformam em metano e água. Os materiais iniciais abundam no planeta vermelho. Temos uma atmosfera de mais de 90% de CO2, e água no subsolo e nas calotas polares. No inverno, dá pra recolher o gelo no chão.
O foguete que usaria esse combustível foi anunciado em 2012, seria o Mars Colonial Transporter, capacidade de carga de 100 toneladas, com 27 motores no primeiro estágio, e 10 metros de diâmetro. O Falcon 9 tem 3,7 metros de diâmetro.

Mars Colonial Transporter, no tempo em que ainda era de fibra de carbono (Crédito: SpaceX)
Em 2016, percebendo que precisavam de mais capacidade de carga e que isso geraria menos lançamentos, barateando o custo de kg/órbita, a SpaceX alterou o Mars Colonial Transport, que agora era o Interplanetary Transport System, com 122 metros de altura, 12 metros de diâmetro e peso total de 10500 toneladas. Para dar uma idéia do que é isso, um submarino nuclear classe Los Angeles tem 6000 toneladas.
Esse monstro teria capacidade de colocar 300 toneladas em órbita baixa, reutilizável, 550 toneladas descartável. O Saturno V conseguia colocar 140 toneladas em órbita baixa.
Em 2017 o ITS se tornou o BFR - Big Fuc- digo, Falcon Rocket.
Uma proposta mais modesta, com 9 metros de diâmetro e 109 metros de altura, o BFR seria feito de fibra de carbono, com os maiores tanques já construídos com esse material. A idéia era lançar o foguete da Flórida, com dois lançamentos previstos para 2022. (Spoiler: Não rolou).
A Realidade mais uma vez fez sua parte em atrapalhar um bom plano, e a SpaceX descobriu que assim como Ruby, tanques e estruturas de fibra de carbono não escalam. Depois de sucessivos testes mal-sucedidos, chutaram o pau da barraca e abandonaram a idéia. Só que voltar pra estrutura do Falcon 9, com uma liga exótica de alumínio e lítio, não era economicamente viável.

Um tanque de fibra de carbono do BFR (Crédito: SpaceX)
Depois de muito bater cabeça, a SpaceX acabou escolhendo o material mais mundano possível: Aço. Não é titânio, alumínio transparente, adamantium, cavorita, vibranium. É aço, mesmo material de uma boa chaleira.
Os tanques de combustível e oxidante foram construídos e testados à exaustão. Vários testes foram destrutivos, quando você pressuriza o tanque com nitrogênio até o limite especificado, continua até o limite estrutural, e vai adiante para ver até onde o bicho agüenta. É divertido:
Entra o Raptor
Com 33 raptors em cada Superheavy, e a SpaceX planejando lançar dezenas de foguetes por dia, é preciso uma linha de produção como nunca se viu. Hoje eles atingiram uma cadência assustadora, estão entregando um motor Raptor pro dia. A Blue Origin levou anos pra entregar dois motores Be-4 para a ULA. Restava saber se o Raptor funcionaria.
Claro, eles foram mais que estados nas instalações em McGregor, Texas, mas nas palavras do imortal Didi (o jogador, não o Dr Renato) “Treino é treino, jogo é jogo”. O Raptor precisava voar, e como a SpaceX não tem problemas em ser tosca quando necessário, usou suas instalações em Boca Chica, Texas, para construir o Starhopper.
Composto basicamente de um tanque, um motor Raptor, três pernas e alguma instrumentação, o Starhopper parecia algo saído de McGyver, ou, mais precisamente, de Operação Resgate, uma série obscura onde um dono de ferro-velho constrói uma nave para ir até a Lua, recolher sucata deixada pela Apollo e revender na Terra.
O mais incrível é que o Starhopper voou, primeiro um vôo de 30 metros, depois um de 150. O Raptor estava validado.
Starbase
Nesse meio-tempo, a SpaceX ampliava suas instalações em Boca Chica. É surpreendentemente difícil achar um bom lugar para lançar foguetes nos EUA. Como ao contrário da China, nos EUA o governo não gosta da idéia de jogar foguetes na cabeça da população, estão restritos a áreas costeiras, na Costa Oeste ou Golfo do México, pois o foguete precisa decolar rumo ao leste, para aproveitar a rotação da Terra e ganhar mais velocidade angular, e sobre o mar para não atingir ninguém quando der defeito (no caso da SpaceX) ou o primeiro estágio for descartado (no caso de todo o resto).
Claro, achar propriedades com quilômetros e quilômetros de área livre, na praia, não é fácil. Boca Chica é um dos últimos lugares disponíveis, é uma região com várias reservas ecológicas, bem perto da fronteira do México, em uma região dominada por cartéis, então não há exatamente um grande fluxo de turistas na fronteira.
A primeira pá de terra foi escavada em 2014. Hoje a SpaceX tem na Starbase vários prédios dedicados à montagem de foguetes, a maior torre de lançamento já construída, estruturas de testes, uma fazenda de tanques e várias tendas, onde os foguetes começaram a ser construídos.
É impressionante quando há dinheiro e interesse em construir algo. Em alguns anos eles criaram um complexo espacial de lançamento e construção de espaçonaves, no meio do nada. Seria um exemplo a ser seguido, se aqui houvesse gente disposta a seguir exemplos.
Enquanto isso...
Sem querer comparar mas já comparando... (Crédito: Editoria de arte)
E a grana, de onde vem?
Boa parte da verba dos estimados US$10 bilhões do desenvolvimento da Starship vem da própria SpaceX, mas eles conseguiram outros aportes, como o bilionário japonês Yusaku Maezawa, que investiu uma fortuna no projeto, em troca da missão Dear Moon, onde ele e um grupo de artistas e influenciadores voarão em uma futura Starship, circunavegando a Lua.
Uma boa notícia veio em 2019, quando a NASA alocou US$967 milhões para o projeto preliminar do HLS – Human Landing System, o módulo que pousará na Lua e retornará astronautas ao nosso satélite, fruto do Programa Artemis.

Os três finalistas para o HLS do programa Artemis (Crédito: NASA)
O dinheiro foi dividido entre o National Team, formado pela ULA, Blue Origin e outras (US$579 milhões), a Dynetics (US$253 milhões) e a SpaceX (US$135 milhões). Os projetos propostos variavam bastante, mas a comparação chega a ser cômica. A SpaceX venceu a concorrência, com a proposta mais barata de todas, por uma longa margem, e por usar uma Starship modificada.
Com 1000m3 de espaço interno pressurizado, a Starship é um monstro, comparado com as soluções da concorrência, a ponto da NASA tentar disfarçar. Veja a diferença entre a imagem “oficial” acima dos três e a real proporção entre eles.

Err... ok. (Crédito: Reprodução Internet)
O contrato vencido pela SpaceX é de US$2,8 bilhões, mas não é um cheque em branco. A NASA agora trabalha com metas, o pagamento ocorre em partes, e somente após etapas cumpridas. Atrasos são por conta da contratada.
Enquanto isso, a SpaceX continuava a construir e testar tanques e protótipos do Super Heavy e da Starship. Alguns foram explodidos enquanto aprendiam as melhores técnicas de construir os tanques de combustível, outras foram descartadas quando se tornavam obsoletas, e em 4/8/2020 o protótipo SN5, ainda pouco mais que uma caixa d’água com um motor, fez um vôo de 150m, bem-sucedido, seguido do SN6, em 3/9/2020.
Em 20 de outubro do mesmo ano foi a vez da SN8, uma versão mais aprimorada da Starship, com três motores Raptor e flaps. Ela atingiu alguns quilômetros de altitude, desligou os motores, assumiu posição horizontal e caiu com estilo voou até o ponto onde religou os motores, voltou pra posição vertical e pousou suavemente. Por pousar suavemente eu quero dizer se espatifou, mas isso era esperado.
Fevereiro de 2021 viu o lançamento da Starship SN9, com as imagens mais lindas do programa até o lançamento de 20 de Abril de 2023. Dessa vez um dos dois motores necessários para o pouso não conseguiu ser religado, e a explosão foi linda.
A SN10 foi lançada em 3 de março, e pela primeira vez o pouso foi bem-sucedido, exceto que algum vazamento fez com que a nave explodisse alguns minutos depois, mas desenvolvimento rápido é assim mesmo.
30 de março foi quando a SN11 também se esborrachou.
Revisando o que foi aprendido com os lançamentos anteriores, e descartando vários protótipos, a SpaceX só voltaria a lançar um protótipo em 5 de maio de 2021, no caso a SN15, e essa foi a boa!
Estava comprovado que a Starship era capaz de pousar, e executar a controversa manobra de mudar de orientação na fase final do pouso, aproveitando a posição horizontal para reduzir sua velocidade durante a reentrada atmosférica.
Depois disso, a SpaceX se concentrou na construção das estruturas de lançamento em Boca Chica, como a torre, os braços gigantes que movimentam os dois estágios e os colocam na plataforma, e a plataforma em si, chamada de Estágio Zero, uma estrutura extremamente complexa e mais complicada de construir do que o foguete em si.

Parece uma banqueta, mas é uma das partes mais complicadas do complexo de lançamento (Crédito: SpaceX)
A torre em si é uma maravilha tecnológica e uma aposta da SpaceX que deixou a comunidade astronáutica coçando a cabeça.
Para economizar pelo e agilizar o tempo entre lançamentos, nem o Super Heavy nem a Starship terão pernas ou pousarão em balsas. Eles serão agarrados por braços gigantescos na torre de lançamento.
Um tal de Covid, mais problemas com licenciamento de agências reguladoras fez com que a SpaceX ficasse quase dois anos sem um lançamento da Starship, mas enquanto isso o projeto foi aprimorado, a linha de montagem dos motores Raptors atingiu a meta de entregar um por dia, e a Starship ganhou placas de proteção térmica e um dispenser de satélites. Agora era esperar os impedimentos burocráticos serem resolvidos.

Teste estático do Super Heavy (Crédito: SpaceX)
Depois de meses todas as licenças tinham sido emitidas, só faltava a licença de vôo, dada pelo FAA. A licença saiu no fim de semana de 15 de abril de 2023, e o lançamento foi marcado para o dia 17. Quase foi, mas faltando 40 segundos uma válvula presa impediu o prosseguimento.
O foguete só subiria três dias depois, dia 20.
Não que houvesse muita esperança. É tudo muito novo, a SpaceX não tinha idéia da interação entre os 33 motores Raptor, que nunca haviam sido acionados ao mesmo tempo, com potência total. O consenso era que se o foguete não explodisse imediatamente, e deixasse a plataforma de lançamento sem a destruir, o teste já seria considerado um sucesso. O resto era bônus.
Era uma aposta, como várias que a SpaceX fez. Nem todas deram certo.
Entre as que deram errado, foi a aposta de que a base de concreto da plataforma sobreviveria à potência dos 33 Raptors. Em retrospecto, foi uma aposta burra. O Super Heavy tem o dobro da potência do Saturno V, que usava uma vala de direcionamento de chamas e um imenso sistema de jatos de água para absorver a vibração causada pelo som dos motores, e evitar que o foguete e a plataforma sejam destruídos.

Base do Estágio Zero. Como direi? Deu ruim. (Crédito: Reprodução Reddit)
A SpaceX tinha um sistema básico de água instalado, e um sistema bem mais robusto já encomendado, recebido, mas ainda não instalado. Eles também planejavam usar uma base de metal com refrigeração à água, mas não tiveram tempo de terminar.
Ainda não há confirmação, mas algo, talvez danos causados durante a ignição fizeram com que dois motores parassem de funcionar, mas como o foguete tem bastante reserva de potência, e ainda estava vazio, sem carga, o bicho subiu mesmo assim. AH, se subiu!
É algo que faz um Falcon 9 parecer uma biribinha. Estamos falando de um foguete com 120 metros de altura, isso é um prédio, dos grandes. 36 andares. O edifício Martinelli, em SP, tem 109 metros. Para os cariocas (e turistas): O conjunto Super Heavy/Starship equivale à altura de 3 Cristos Redentores.
Esse monstro continuou subindo, mesmo com outros motores dando problema, num total de 6. Os atuadores hidráulicos que movimentam os motores e direcionam o foguete também apresentaram falhas, mas eles vão ser substituídos por atuadores elétricos nas novas versões, que já estão construídas.

Você vai acreditar que um arranha-céu pode voar! (Crédito: Osunpokeh / Creative Commons)
Para surpresa de muita gente, o foguete atingiu Max-Q, o ponto de mais pressão aerodinâmica, e sobreviveu.
Mais adiante, o Super Heavy começou uma manobra de rotação, que seria usada para separar a Starship. No plano que ninguém botava muita fé de dar certo na primeira vez, o Super Heavy faria uma manobra para anular sua velocidade horizontal, e simularia um pouso no mar. A Starship atingiria velocidade orbital, mas sem circularizar, então reentraria após dar a volta ao mundo, atingindo o mar perto do Hawaii.
Só que os motores fizeram falta, a manobra ocorreu a apenas 39km de altitude. O Falcon 9 realiza a manobra de separação aos 70Km de altitude.
Sem saber o que fazer, o foguete começou a dar cambalhotas, o que mostrou uma robustez fora do normal. Foram pelo menos três, antes do sistema interno OU o controle da missão acionar o sistema de autodestruição.
O Everyday Astronaut, Tim Dodd, que aliás será um dos passageiros do projeto Dear Moon, tem um vídeo com imagens incríveis do lançamento e da explosão final.
Como primeiro teste, foi além de todas as expectativas. A chance do foguete decolar sem explodir, internamente era de 50%. O aprendizado foi imenso, os engenheiros devem estar afogados em dados. Um Falcon 9 normal tem mais de 3000 canais de telemetria, o Falcon Heavy / Starship, em fase de protótipo deve ter bem mais.
Entre mortos e feridos, salvaram-se todos
A perda do foguete nem foi inesperada, a destruição na Starbase, essa sim surpreendeu. Os 33 motores Raptor atomizaram o concreto, deixando a base da plataforma só nos vergalhões, cavando um buraco gigantesco no chão. Pedaços gigantes de concreto foram atirados a centenas de metros, atingindo até o oceano.
Dezenas de câmeras foram destruídas, a fazenda de tanques da SpaceX também ficou danificada. Uma nuvem de poeira se depositou nas casas, carros e ruas a quilômetros de distância. Ficou claro que foram otimistas demais, e precisam, de alguma forma, conter os gases da decolagem.
Os pessimistas de sempre já estão dizendo que não vai dar certo, que o foguete é grande demais, que não conseguirão resolver os problemas. Você sabe, o mesmo que falaram quando a SpaceX anunciou que iria pousar foguetes.
Por enquanto a SpaceX está investigando tudo que deu errado, para aplicar esse conhecimento nos próximos vôos. Não há nenhuma informação sólida sobre novas datas de lançamento, mas segundo Bill Nelson, Administrador da NASA, a SpaceX diz que espera em dois meses ter consertado tudo e estar pronta para um novo teste.
Dará certo? Provavelmente. Eu diria que dá pra apostar na empresa que tornou falsa aquela velha máxima de que foguete não dá ré. E a reconstrução já começou.
The Universe sucks: The mysterious Great Attractor that’s pulling us in

Enlarge (credit: Aurich Lawson | Getty Images)
{kind=link}
Our Milky Way galaxy is speeding through the emptiness of space at 600 kilometers per second, headed toward something we cannot clearly see. The focal point of that movement is the Great Attractor, the product of billions of years of cosmic evolution. But we'll never reach our destination because, in a few billion years, the accelerating force of dark energy will tear the Universe apart.
Whispers in the sky
Beginning as early as the 1970s, astronomers noticed something funny going on with the galaxies in our nearby patch of the Universe. There was the usual and expected Hubble flow, the general recession of galaxies driven by the overall expansion of the Universe. But there seemed to be some vague directionality on top of that, as if all of the galaxies near us were also heading toward the same focal point.
Astronomers debated whether this was a real effect or some artifact of Malmquist bias, the bias we get in our observations because bright galaxies are easier to observe than dim ones (for fans of statistics, it’s just another expression of a selection effect). It could be that a complete census of the nearby cosmos, including the much more numerous small and dim galaxies, would erase any apparent extra movement and return some sanity to the world.
Intel's OpenGL & Vulkan Linux Drivers Now Build On ARM
Upstream Mesa Close To Supporting The Experimental Xe DRM Kernel Driver
In the war on bacteria, it’s time to call in the phages

Enlarge (credit: Jacqui VanLiew/Getty Images)
{kind=link}
Ella Balasa was 26 when she realized the routine medical treatments that sustained her were no longer working. The slender lab assistant had lived since childhood with the side effects of cystic fibrosis, an inherited disease that turns mucus in the lungs and other organs into a thick, sticky goo that gives pathogens a place to grow. To keep infections under control, she followed a regimen of swallowing and inhaling antibiotics—but by the beginning of 2019, an antibiotic-resistant bacterium lodged in her lungs was making her sicker than she had ever been.
Balasa’s lung function was down to 18 percent. She was feverish and too feeble to lift her arms over her head. Even weeks of intravenous colistin, a brutal last-resort antibiotic, made no dent. With nothing to lose, she asked a lab at Yale University whether she could volunteer to receive the organisms they were researching: viruses that attack bacteria, known as bacteriophages.
AIpocalipse: Vamos todos perder o emprego ou a IA trará a Utopia?
Alguns meses atrás – e são bem poucos – o AIpocalipse estava restrito aos artistas digitais, especificamente aos que faziam comissões para otakus desenhando a Bulma de bikini, ou algo assim. Agora o Tsunami apareceu no horizonte e todo mundo está com medo do que vai acontecer.
- Microsoft 365 Copilot – Eles vão dominar o mundo – de novo
- GPT-3 - Entrevistamos o fantasma na máquina

Restos de uma sociedade distópica, na visão do Stable Diffusion (Crédito: MeioBit / SD)
É compreensível. É normal ter medo do desconhecido, quando vemos nosso ganha-pão, tudo que aprendemos durante a vida se tornar obsoleto. Isso acontece com razoável freqüência, mas em geral são casos específicos. Ninguém se pergunta o que aconteceu com as empresas que criavam fidget spinners, ou fabricantes de Ioiôs, um brinquedo extremamente atrelado a modas.
A diferença, agora no AIpocalipse é que a Revolução não está atingindo camponeses ameaçados por tratores a vapor, ou operários tamancudos assombrados com teares automáticos.
Tivemos seis meses em que a IA ameaçava somente artistas do Tumblr, mas agora a lista de atividades “ameaçadas” ocupa páginas e páginas. Atividades ditas como criativas estão na mira da IA, há relatos de sites demitindo redatores (não tenha ideias, Mobilon) e trocando-os por assinaturas do ChatGPT Pro.
A Microsoft lançou o Github Copilot X, que pode ser o AIpocalipse ou a Utopia para desenvolvedores, mas vai destruir instituições. A Adobe lançou o Firefly, seu gerador de imagens via IA. A Shutterstock também lançou seu serviço, o que gera um monte de questões. Eles são um serviço que licencia e revende imagens de arquivo, mas com seu gerador os fotógrafos se tornam redundantes.
Se bem que na verdade, o próprio gerador da Shutterstock é redundante, mesmo com instalações caseiras como a minha consigo gerar um monte de imagens de mulheres felizes com suas saladas.
Em verdade as empresas estão correndo pois não têm ideia do futuro, elas precisam de uma cabeça de ponte na IA, ou vão ficar pra trás, mas e nós?
Inovação == Demissão?
Existe uma visão de que toda inovação tecnológica acarreta perda de postos de trabalho. O Glorioso Aldo Rebelo, Ex-Ministro de Ciência, Tecnologia e Inovação acredita tanto nisso que apresentou um Projeto de Lei que proibia inovações tecnológicas. Na prática a resposta é... é complexo.
A população empregada hoje é bem maior do que em 1827, então de alguma forma novos postos de trabalho foram criados, mas os antigos muitas vezes foram atropelados.
O Pony Express foi um serviço no Velho Oeste ligando o Missouri à Califórnia. Lembre-se, naquele tempo era tudo mato, atravessar o país era perigosíssimo e levava meses. A eleição de James Buchanan como Presidente dos EUA em 1857 levou meses para chegar aos jornais da Califórnia.

Cartaz de recrutamento para o Pony Express. (Crédito: Domínio Público)
O Pony Express mantinha uma rede de postos logísticos a cada 16km, onde jovens, em geral órfãos cavalgavam alucinadamente até o limite de seus cavalos, chegavam no novo posto, tomavam uma água, pegavam um cavalo novo e seguiam adiante. A média de tempo para uma correspondência cruzar costa a costa nos EUA agora era de dez dias. A eleição de Lincoln foi comunicada em apenas 7.
O Pony Express era uma maravilha logística, mas durou apenas 18 meses, de 3 de abril de 1860 a 26 de outubro de 1861. A chegada do telégrafo tornou uma excelente e revolucionária ideia totalmente obsoleta.
A invenção do automóvel foi a pá de cal nos cavalos, muitos viraram cola, ou foram vendidos para açougues ou fazendas. Os fabricantes de carroças se adaptaram para produzir carrocerias, muitos fabricantes de carros vendiam só o chassis, que o cliente então enviava para adaptarem a carroceria.
Cocheiros se tornaram motoristas, outros postos de trabalho sumiram, mas a inovação tecnológica também cria novos postos. Carros precisam de frentistas, de vendedores de seguro e de mecânicos. Uma montadora produz muito mais do que uma fábrica de carroças, e demanda um número maior de funcionários, mesmo com automação.
É meio cruel invocar Darwin, mas sobrevive quem melhor se adapta às mudanças, e o mundo muda o tempo todo. Os EUA estão cheios de cidades ligadas à mineração que perderam sua fonte de renda, há vários projetos bem-sucedidos onde mineiros foram treinados como programadores de computador.

Imagem genérica de programadores (Crédito: MeioBit / SD)
Gerações de marinheiros treinados em veleiros tiveram que se adaptar a vapores, depois diesels. Artes e habilidades são perdidas, mas assim é a vida. Sé que aqui, do olho do furacão, não conseguimos ter a perspectiva global.
AIpocalipse Now
Muitos, muitos anos atrás reza a lenda um dono de um escritório contábil, daqueles bem chucros chegou na sala onde 3 ou 4 sujeitos trabalhavam com sistemas em Clipper (pergunte a seus pais) e sumariamente demitiu todo mundo. Ele então tirou um disquete de uma pasta, enfiou no drive e digitou na tela do DOS: “Folha de Pagamento”.
Nada aconteceu. Ele havia comprado um gerador de relatórios bem popular na época, que permitia que você escolhesse via menus algumas opções e tinha razoável flexibilidade, acessando o dBase (avô, pergunte a seu avô). O slogan da publicidade desse gerador era “despeça seu programador”.
Empresas que estão demitindo ou pensam em demitir por causa da IA estão sendo burras como o sujeito da anedota acima. Exceto casos específicos, AI deve ser usada como ferramenta de aumento de produtividade, não de corte de custos.

Placa erguida durante a Grande Depressão de 1929 (Crédito: Domínio Público)
Há bastante gente em pânico, um grupo de artistas entrou com uma ação coletiva contra A Stability.AI, Midjourney, DeviantArt e outras empresas por trás de IAs geradoras de imagens. Não vai dar em nada, o gênio saiu da garrafa, é impossível fazer todo mundo parar de disponibilizar, e muito menos usar essas ferramentas.
Há motivo? Sendo honesto, dependendo do artista, há sim. Uma quantidade relevante de jovens que desenham bem ganha um trocado no Tumblr e no DeviantArt desenhando por encomenda em geral imagens de animes, hentai, furries. Esse povo será dizimado pela IA, e aparentemente já está sendo. O Civitai.com, site NSFW que agrega modelos para o Stable Diffusion está lotado de modelos de anime, com os quais você consegue criar qualquer coisa, incluindo tentáculos.
O Buzzfeed anunciou que irá usar o ChatGPT para criar conteúdo. Ele é excepcionalmente bom para o conteúdo repetitivo sem imaginação e caça-cliques do Buzzfeed. Dá para criar listinhas e top 10s em escala industrial. Se eu fosse redator do Buzzfeed eu estaria me sentindo extremamente inseguro e temeroso de ser substituído a qualquer momento, mas essa é a realidade dos redatores do Buzzfeed: Eles são substituíveis e descartáveis.
E os Programadores, devem temer o AIpocalipse?
De novo, depende, eu estou vendo gente sem muita familiaridade com programação, em geral de outras áreas, como Ciências, adorando poder escrever seus programas de forma ágil e eficiente, sem precisar depender de terceiros, e mesmo entre profissionais de TI, o povo está adorando o CoPilot e similares.
Agora, ao invés de ir no Stack Overflow copiar código, o GPT4 gera o código pra gente, um senhor avanço, que se reflete em produtividade, mas cria o medo da caixapretização da programação.
Há quem alerte que deixar a IA fazer o trabalho todo afasta o programador da máquina, ele não terá ideia do que o programa está fazendo internamente. Eu vou contar um segredo: Esse barco já partiu faz tempo.
Hoje um programador Python usa um monte de módulos que não faz a menor ideia de como funcionam por dentro. O alvo da ve são os programadores de framework, que não sabem desenvolver nada do zero, atrelados a seu framework de estimação.
Antes deles a crítica era aos programadores de IDE, que não sabiam usar linha de comando, faziam tudo de dentro do Eclipse, do Visual Studio e do Codewarrior.
Nas linguagens, havia uma disputa de pureza, muita gente não considerava linguagem de programação de verdade se não acessasse o hardware diretamente. Por muito tempo o limite era o povo que programava em linguagem de máquina, eu adorava soltar que escrevia em Assembler Z80 (na época a gente chamava de assembler, e vai ficar assim), até que descobri que existem loucos que programam em microcódigo, escrevendo para CPUs, e nem vou entrar na insanidade do FPGA.

O venerável Z80 (Crédito: Wikimedia Commons)
A IA é mais uma ferramenta, é mais uma camada. Ela vai acabar com todas as outras? Sinceramente, ninguém sabe, mas ela vai acabar com uma classe importante: O desenvolvedor júnior.
É mais rápido para um analista experiente produzir código usando IA, do que especificar funções e algoritmos, repassar para os juniores e depois lidar com o trabalho de revisar e certificar o código de cada um.
O senso comum aponta o contrário, faria sentido ter menos profissionais caros, e mais iniciantes usando a IA para tirar dúvidas e produzir código de melhor qualidade, mas não é assim que a banda toca.
Existe uma máxima na Informática: Um computador faz o que você manda ele fazer, não o que você quer que ele faça, e saber o que pedir é muito mais complicado do que parece.
Para começo de conversa, o cliente não sabe o que ele quer. Ele não sabe especificar, não sabe definir as regras de negócio e não conhece seu fluxo operacional. É preciso um profissional para entrevistar, auditar e especificar o sistema que o cliente precisa, não o que ele imagina querer.
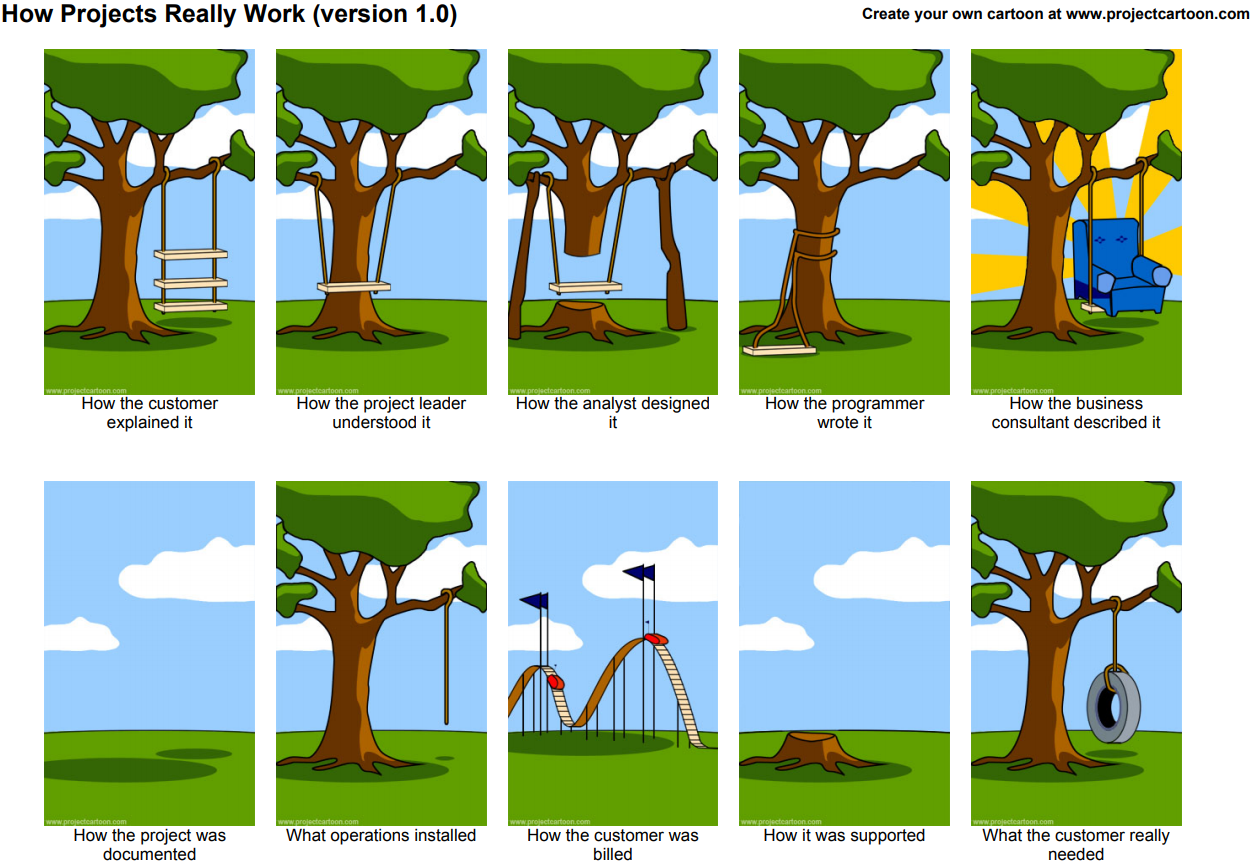
Um clássico. (Crédito: Reprodução Internet)
Descrever um algoritmo complexo é mais complicado do que codificá-lo. É preciso saber o que você quer, e saber descrever de forma que a IA entenda, isso demanda imaginação e conhecimento, características não tão comuns entre o afegão médio.
Prevejo grandes oportunidades de emprego e crescimento profissional para engenheiros de software com bastante imaginação e capacidade de comunicação. E isso vale para todas as áreas. Você vai precisar se comunicar com a IA, ela não tem poderes mágicos para adivinhar o que você quer fazer. Aquele velho meme, que agora dizem que envelheceu mal, continua perfeitamente atual:
O tal meme (Crédito: Reprodução Internet)
“Faça um aplicativo” não quer dizer nada, do mesmo jeito que “folha de pagamento” é apenas uma classificação genérica.
Uma pessoa que nunca cozinhou na vida dificilmente conseguiria instruir um cozinheiro novato a fazer um bolo, já o Gordon Ramsey vai xingar bastante, repetir muitos passos mas o novato produzirá um bolo excelente.
O problema aqui é que leva anos até um profissional de TI conseguir montar o arcabouço de conhecimento necessário para especificar sistemas e algoritmos de forma eficiente, e o AIpocalipse está mirando nos novatos.
Há um risco real dos iniciantes não conseguirem entrar no mercado de trabalho, e mesmo entrando, não adquirirem os conhecimentos necessários. Os mais experientes eventualmente sairão do mercado, sobrará um vácuo com excelentes IAs mas sem gente para instruí-las.
Quem Viver, verá
Uma velha maldição chinesa diz “Espero que você viva em tempos interessantes”, mas dessa vez exageraram. Todo mundo já estava agitado o suficiente vendo (mais) uma Guerra Mundial gestando na Europa, agora essas aplicações de Inteligência Artificial caem de paraquedas no colo da gente. E ainda estamos em março!
Ninguém sabe o que fazer com a IA. O Google diz que vai diminuir a relevância de sites que usem textos gerados pelo ChatGPT, mas por quanto tempo vão fazer isso? Quando todo mundo estiver usando, a penalização do Google se tornará irrelevante.
Há listas com mais de 400 aplicações usando a API do ChatGPT, todo dia surgem novas e criativas ferramentas, todas ainda apenas arranhando a superfície.
Em 1943 uma menina chamada Patricia Malone tinha dois anos e idade e alguns dias de vida restante até sucumbir a uma sepse. Um jornalista fez uma campanha-relâmpago para que o Governo dos EUA recolhesse todas as doses disponíveis da altamente experimental Penicilina, e tratassem Patricia. Isso foi feito, e em algumas horas ela estava se recuperando.
O CEO da Pfizer acompanhou o caso. Ele não acreditava muito na Penicilina, mas vendo o caso, e tendo uma filha que morreu da mesma doença, instruiu a empresa investir massivamente na nova droga. Hoje tratamos em casa doenças que seriam fatais 50 anos atrás.
Satya acha que a IA será uma revolução como o iPhone. Eu acho que ele está sendo conservador. A IA tem potencial de mudar o mundo como a eletricidade ou os antibióticos.

Fikadika (Crédito: Domínio Público)
O que não foi boa notícia para acendedores de lampião, fabricantes de velas e bactéria.
A lição é: Não seja uma bactéria. Entre em modo Full Darwin, estude como a IA irá mudar sua área de atuação, descubra como torná-la uma aliada, como você pode agregar a IA ao seu trabalho, crie uma simbiose. Não perca tempo brigando, tentando mostrar a IA como o inimigo. Ela é inevitável, e não tem engrenagens para você jogar seus tamancos.
A IA tem potencial de afetar todos os ramos da sociedade e da cadeia produtiva. Resistir a ela é fútil, logo teremos aplicações de IA em todos os cantos, de Call Centres a elevadores.
Em uma cena da última temporada de Westworld, a roboa Dolores está trabalhando em uma indústria de entretenimento, escrevendo histórias. Ela descreve os personagens e situações de forma bem genérica, e o computador cuidado do resto, preenchendo as lacunas, criando imagens e contexto.
Quem diria que uma cena que em 2022 era ficção científica o bastante para se passar em 2058 estaria prestes a se tornar realidade em 2023. Estamos prestes a migrar para uma Era onde informação deixará de ser escassa, a IA responderá muitas perguntas práticas, e talvez até algumas filosóficas.
Depende de cada um escolher se lutar contra a IA, se recusar a usar os serviços atrelados a ela, e manter seu trabalho como está, o que inevitavelmente levará ao AIpocalipse, ou se vai surfar essa nova onda na crista, se adaptando e usando a IA como uma ferramenta maravilhosa, o que poderá nos levar a uma UtopIA.
A única certeza é que no futuro da IA ninguém encerrará um texto com um trocadilho horrendo desses.
AIpocalipse: Vamos todos perder o emprego ou a IA trará a Utopia?
NASA: estudos confirmam sucesso da missão DART
A NASA lançou em 2021 a missão DART, um teste para a avaliar a eficácia de usar impactadores espaciais, movidos a velocidades extremas e portando cargas de material denso, como ferramentas para desviar asteroides potencialmente perigosos, em casos onde podem entrar em rota de colisão com a Terra.
- Missão DART – O primeiro passo na defesa planetária
- Armas nucleares podem proteger a Terra de asteroides, aponta estudo
O teste da DART foi bem-sucedido, ao atingir em cheio o asteroide Dimorphos em setembro de 2022, e não muito depois disso, confirmou que a órbita do mesmo foi alterada. Agora, começam a surgir artigos confirmando os dados da NASA, e adicionando mais detalhes.

Representação artística da missão DART em rota de colisão com o asteroide Dimorphos (Crédito: NASA/Johns Hopkins APL/Steve Gribben)
Hoje nós dispomos de poucas técnicas para proteger a Terra de corpos celestes perigosos. Infelizmente, contar com a ajuda do Bruce Willis não é mais uma opção, e outras em estudo como usar motores, ou mesmo tinta, implicam em desafios complexos.
A opção nuclear, embora tenha demonstrado resultados positivos em simulações recentes, não passa disso, um exercício de cálculo baseado em probabilidade, e ninguém sabe como um asteroide pode se comportar na vida real.
A única opção que temos hoje, totalmente viável e ligeiramente escalável, é o que a NASA chama de impactador cinético, a base do programa DART. De modo resumido, você carrega uma sonda com um material incrivelmente denso, e acelera a uma velocidade extrema em direção a um asteroide.
Graças ao bom e velho Newton, sabemos que a força do impacto da sonda é determinada pela sua massa multiplicada pela aceleração, e ela possui um impactador de 610 kg. A velocidade de impacto foi mensurada em 22.531 km/h, ou 6,26 6.258 m/s; o alvo escolhido foi Dimorphos, um asteroide de 177 metros de diâmetro que compõe o sistema binário 65803 Didymos, primeiro porque qualquer alteração neste poderia ser percebida analisando sua órbita ao redor de Didymos A, de 780 m de diâmetro.
Segundo, a proximidade e seu tamanho o tornaram candidatos ideais para o teste do DART, e também por não estar em rota de colisão, tampouco uma colisão mudaria seu curso a ponto dele passar a ser considerado um risco. Uma vez selecionado o alvo, a sonda foi lançada via Falcon 9 no dia 24 de novembro de 2021.
Às 09:21 de 26 de setembro de 2022, horário de Brasília, o impacto da sonda DART foi confirmado pela NASA, com uma força similar a de uma bomba nuclear. Sim, tem vídeo.
NASA não esperava resultado tão bom
Para a NASA, a missão seria considerada um sucesso se a órbita de Dimorphos fosse alterada em no mínimo 73 segundos, mas os resultados superaram todas as expectativas: no que ele originalmente levava 11 horas e 55 minutos para dar uma volta ao redor de Didymos A, após o impacto, o tempo caiu para 11 horas e 23 minutos.
Sim, o DART causou uma redução de 32 minutos na órbita do asteroide, um tempo 25 vezes maior do que o limiar; a NASA esperava que o impacto causasse uma alteração de pelo menos 7 minutos, valor igualmente superado pela realidade. Segundo a agência, o efeito de recuo causado pela ejeção de destroços, dispersados pelo impacto, foi bem maior. Ponto para Newton, de novo.
Agora, começaram a surgir estudos paralelos, que estão analisando e confirmando os dados coletados pela NASA através da sonda parceira LICIACube, um cubesat italiano que se destacou antes do impacto e enviou imagens da DART acertando o asteroide, bem como de outros observatórios, como os telescópios Hubble e James Webb.
O primeiro deles detalha que uma missão de impactadores pode ter sucesso mesmo em casos de desviar corpos celestes realmente perigosos, quando planejada com anos ou décadas de antecedência, o que aumentaria as chances, mas mesmo em uma situação sem avaliação prévia, como descobrir um asteroide em rota de colisão a meses de distância, o DART pode prover resultados positivos significantes.
No segundo, dados coletados de outras duas fontes confirmaram o desvio na órbita de Dimorphos, na redução dos mesmos 33 minutos de sua duração. Já um terceiro confirmou que a transferência de momento linear foi instantânea, com a velocidade do asteroide reduzida de pronto em 2,7 mm/s; com o tempo, a ejeção de material respondeu por mais transferência de energia do que a sonda DART em si, que serviu como catalisador.
Por fim, o quarto estudo levantou discussões sobre o que podemos aprender sobre a formação de cometas no Sistema Solar, visto que Dimorphos é agora um "asteroide ativo" com uma nuvem de detritos em sua órbita, formando uma cauda que se estende por 9.656 km.
A missão DART foi importante para confirmar a viabilidade de desviar asteroides da Terra em rotas perigosas, com sondas prontas para desferir porradas em quem chegar perto. Para nossa sorte, não há nada no horizonte minimamente perigoso para nós, o que permitirá à NASA e demais agências especiais refinarem a tecnologia, tornando-a mais robusta e pronta para, quem sabe, encarar até mesmos pedregulhos capazes de desencadear Eventos de Extinção em Massa.
Claro, a opção ideal seria iniciar os planos para colonização de outros planetas, mas isso ainda vai demorar bastante.
Referências bibliográficas
DALY, R.T., ERNST, C.M., BARNOUIN, O.S. et al. Successful Kinetic Impact into an Asteroid for Planetary Defense. Nature (2023), 1.º de março de 2023. Disponível aqui;
THOMAS, C.A., NAIDU, S.P., SCHEIRICH, P. et al. Orbital Period Change of Dimorphos Due to the DART Kinetic Impact. Nature (2023), 1.º de março de 2023. Disponível aqui;
CHENG, A.F., AGRUSA, H.F., BARBEE, B.W. et al. Momentum Transfer from the DART Mission Kinetic Impact on Asteroid Dimorphos. Nature (2023), 1.º de março de 2023. Disponível aqui;
LI, JY., HIRABAYASHI, M., FARNHAM, T.L. et al. Ejecta from the DART-produced active asteroid Dimorphos. Nature (2023), 1.º de março de 2023. Disponível aqui.
Fonte: Missão DART (NASA)
Framework’s first gaming laptop features upgradeable GPUs, swappable keyboards

Enlarge (credit: Framework)
{kind=link}
We were skeptical at first, but Framework has delivered on the promise of its original 13-inch laptop. Three product generations in, the company has made a respectable competitor for the Dell XPS 13 or MacBook Air that can be repaired, modified, and upgraded, and owners of the original laptop can easily give themselves a significant performance boost by upgrading to the new 13th-generation Intel or AMD Ryzen-based boards the company announced today.
Framework is now looking to build on that track record with an all-new Framework Laptop 16. It's a larger-screened model that can fit more powerful processors, dedicated GPUs, and a range of different keyboard modules, all with the same commitment to repairability and upgradeability seen in the original Framework Laptop (now retroactively dubbed the Framework Laptop 13).
Framework isn't discussing many details yet; preorders won't open until "this spring," and shipments won't begin until "late 2023."