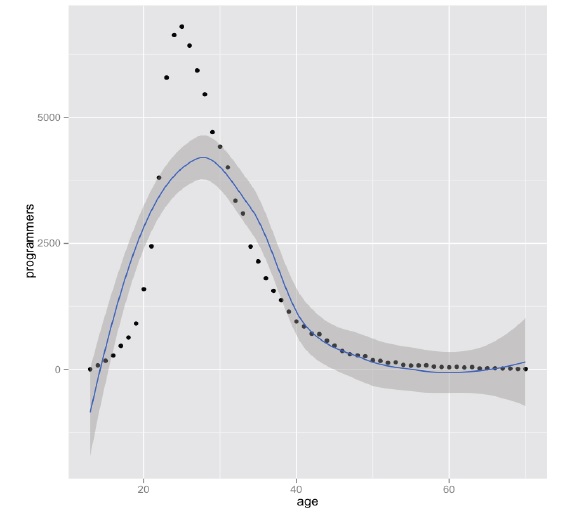
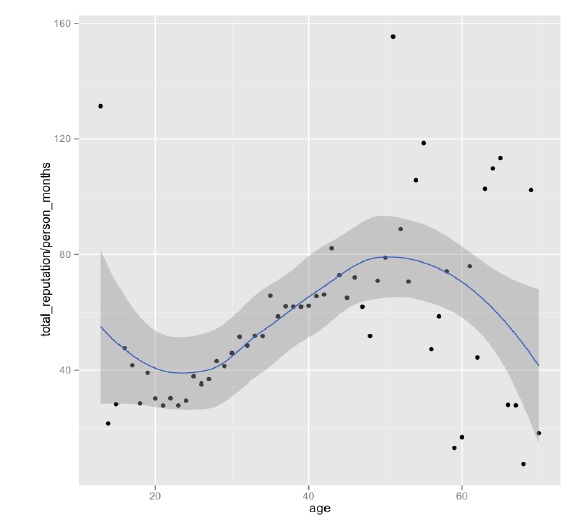
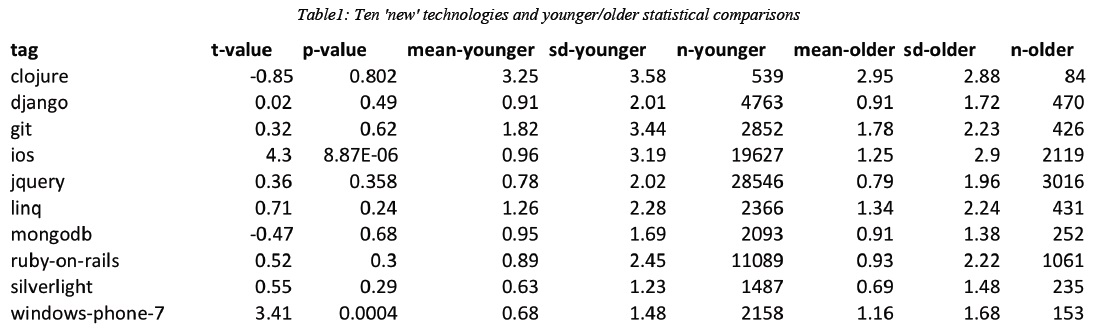
Being a middleware developer is challenging enough to begin with, especially since it is such a tough business model, but support can make your life a living hell. The advantages for the customer are clear, developing software is expensive and risky and licensing middleware reduces risk by adopting a proven piece of technology. For the licensee, their software engineers will have to spend less time reinventing the wheel, doing research and development and can instead focus on the specific product they are trying to create.
Today’s modern game engines make heavy use of licensed middleware. Gone are the days of the ‘not-invented-here’ syndrome. Sure, there are a few holdouts who want to do everything their own way, but they are few and far between. Why would you write your own video codec, compression engine, or sound system? What would be the point? These technologies are practically commodities at this point.
Some pieces of middleware are a bit more controversial. In particular are libraries designed to solve physics and graphics problems. Rarely do these ever just drop easily into an integration. There are often unrealistic expectations on the part of the customer. Frequently they don’t realize that even though they have licensed this middleware they still must account for the time it takes to integrate it, as well as learn how to use it to implement specific features their product requires.
The biggest problem middleware providers face is support. This goes beyond simply trying to explain to a developer how to use the API, it is the fact that now that your software is deeply embedded in someone else's product, and if their product crashes anywhere inside of your code, then, Houston, you have a problem. In fact you may have a very, very, very, big problem. Even if the developer passed complete garbage data into your middleware, even if they abused your middleware worse than Bobby Brown, if it crashes anywhere in your code it almost always instantly becomes your fault.
Once your middleware has become part of someone else's product, you are for practical purposes usually an unpaid member of their development team. You may often find yourself in the situation of being used as a scapegoat for why things are going wrong. If a developer can't get something to work the way their manager wants it to, or there are other problems, they can just blame the middleware since those engineers aren't around to defend themselves. Frankly, these kinds of political issues arise frequently.
Once your middleware has become part of someone else's product, you are for practical purposes usually an unpaid member of their development team. You may often find yourself in the situation of being used as a scapegoat for why things are going wrong. If a developer can't get something to work the way their manager wants it to, or there are other problems, they can just blame the middleware since those engineers aren't around to defend themselves. Frankly, these kinds of political issues arise frequently.
Something else to be aware of is that, frequently when people license a piece of middleware they may not understand the underlying technology very well themselves. Often junior level programmers may be trying to use your API in ways that it was never intended to be used or you never could have imagined. They may call your API from the most unexpected places and in the most unexpected ways. Once your middleware has been licensed to several customers you may feel like you never get to write a new line of code ever again. You may feel as though you are under constant attack and bombardment from your customers which, in actuality, you probably are.
Here are some of the issues you will deal with in support.
-
Their product will crash in your code, which makes it immediately ‘your fault’
-
They will invoke your API from a myriad of different threads, even if your documentation says they shouldn't do that.
-
They will pass bad pointers into routines and blame you when the code crashes.
-
They will pass in bad floating point numbers which will then, in turn, produce infinities, and expose bizarre behavior and crashes.
-
They will pass in what are technically considered ‘valid’ floating point numbers but they will be wildly out of range, either massive in size or incredibly tiny; creating all kinds of pathological behavior.
-
They may create hundreds of thousands of instances of objects in a system designed to handle no more than a few hundred.
-
They may set constants and other tuning parameters to outrageous values that cause the system to consume insane amounts of CPU and then blame you because your middleware is so slow.
-
They may create thousands of objects but never release them.
-
They may create thousands of objects all at the origin since, at object creation time, they don’t know their position yet.
-
They will pass in normals that are not normal.
-
They will pass in matrices which are invalid.
-
They will pass in quaternion rotations which are completely invalid.
-
They will pass in triangle mesh geometry with degenerate faces, and all manner of corruption.
-
They will pass in convex hulls which are completely inappropriate for real-world use.
-
They will report impossible to reproduce problems.
-
They will report problems which only occur, at random, after their product has been running for 10 hours straight.
-
They will report problems but give you no way to debug or support them short of getting on an airplane and flying physically to their location.
I could go on and on, but you get the idea. Like I said, the business model for middleware is challenging enough, but the support nightmare makes it a largely thankless task. What is a middleware provider to do?
Treat your customer as your enemy. Imagine your customer is actively trying to write malware to attack your API. While they may not consciously be doing that, in the practical case that is essentially what is happening.
There is a solution to this problem, but it is rather extreme. You do not, necessarily, have to go the full extreme route to address these support issues. You can do something in between and live with the risks that you leave yourself open to. The rest of this article is going to discuss the extreme view of implementing a fully hardened API and what that requires.
I also do not talk a great deal about unit-testing here. Obviously you should have a robust set of tests and samples for your SDK, that is a given. However, unless your API is very simplistic, it is doubtful that you will even begin to scratch the surface of how end-users will use your system. Yes, write as many tests as you can but also realize the limitations of this testing coverage.
One thing I strongly recommend is that if your middleware is designed to be used by large scale development projects, then do not release it until it has been thoroughly integrated and tested in at least one large scale development project. Sandbox and sample testing is so unrealistic as to be relatively useless.
In my career as a software engineer I have seen numerous products released that were designed to help developers with some set of problems that, as soon as you applied it to a real-world massive project, rolled over and died immediately.
I also do not talk a great deal about unit-testing here. Obviously you should have a robust set of tests and samples for your SDK, that is a given. However, unless your API is very simplistic, it is doubtful that you will even begin to scratch the surface of how end-users will use your system. Yes, write as many tests as you can but also realize the limitations of this testing coverage.
One thing I strongly recommend is that if your middleware is designed to be used by large scale development projects, then do not release it until it has been thoroughly integrated and tested in at least one large scale development project. Sandbox and sample testing is so unrealistic as to be relatively useless.
In my career as a software engineer I have seen numerous products released that were designed to help developers with some set of problems that, as soon as you applied it to a real-world massive project, rolled over and died immediately.
To be clear, I am not saying that you should do all of these things. What I am saying is that if you wanted to make a perfectly hardened API then you would have to do so; especially since anything less does expose you to some element of risk. The actual solution is probably to adopt some of these recommendations, but not all of them everywhere at all times.
The following rules apply ONLY to your public API. Internally, you can code however you wish and to any standard that you wish. These guidelines only refer to how your end-user, your customer, is allowed to interact with your middleware.
Rule #1 : Never use pointers, EVER! If your API ever accepts a pointer, anywhere, then you are implying a level of trust with the developer that is not warranted. You are trusting that the developer is only ever going to pass you a valid pointer. You might even think, hey, this is a pointer to an object that I allocated so it must be safe, but that still doesn't cut it. You would now be trusting the application to pass you back, unmolested, the same pointer you created and you don’t know that this is true. The simple fact is that you cannot allow the end user to pass you a pointer that your code then operates on. If you do, and they pass you a bad pointer, then your code will crash when you dereference it and, when your code crashes, it’s not their fault, it’s now your fault. This is more than just testing for null pointers which, of course, you should do. This is about any potentially random value a pointer could be assigned to. The pointer could be bad because it was in an uninitialized data section, it could be bad because it refers to an object which has already been deleted, or it could be bad simply because the application developer trashed it.
The same thing goes for references. References are pointers too, so don’t think that somehow lets you off the hook here.
You might be wondering now, if you cannot ever use pointers, what do you use instead? Instead of pointers you should use ‘handles’. A handle is simply an integer value which refers indirectly to a pointer. In any use case where your API might normally return a pointer, instead you should return a handle (integer) instead.
When the user passes a handle back to you (instead of a pointer) you can completely and safely validate this handle with zero risk. Your own SDK will maintain a handle table, that maps an integer to a pointer. First you make sure that the integer passed in is within range and represents a valid handle/pointer mapping. If it does not, then you simply do not attempt to operate on it, and return an error code and/or issue an error message to the developer via whatever logging mechanism your SDK implements.
Even if the handle passed in is valid, it may not necessarily be pointing to the correct type of object, so your code should validate this as well before dereferencing it.
Rule #2 : Never use C++ non-static methods EVER! This may not seem obvious at first, but this is actually just an extension of Rule #1 to never use pointers. It is pretty much impossible to use C++ without using pointers, unless all of your methods are static which wouldn't really make much practical sense. Whenever you call a method on a C++ class there is an implied pointer known as the ‘this’ pointer. If any part of your API uses C++ methods it violates the first rule to not use pointers, for all of the same reasons cited above.
You can use C++ classes or flat structs so long as none of the member variables contain pointers or non-static methods.
Rather than further confusing things, the best rule is to make your entire API be straight vanilla C. These functions (not methods) will be physically linked into your application. The customer will get a link error if they use the API incorrectly, but there is no risk at runtime.
It is important to remember, once again, that this is only in reference to your public customer facing API. Your actual implementation code can use all of the C++ and object oriented goodness that you want, you just can’t expose any of that to the end user.
Rule #3 : Never use the STL, Boost, or other dependencies in your public API. This is basically the same as rule #2. These APIs are all based on C++ and imply way too much trust about the format and validity of the data being passed. Once again, you can use them in your own internal implementation code if you wish, so long as you are willing and ready to accept any risk that they pose.
Rule #4 : Never trust a floating point number passed into your API : You would be amazed at the world of trouble that this can cause. Floating point numbers are almost worse than garbage pointers being passed into an API because they are more insidious in some ways. If you dereference a bad pointer, you will generally get a crash right then and there. However, if you reference a garbage floating point number, instead of getting a crash, you will likely just get a garbage result. One bad floating point number used in a calculation will then infect the result and get passed on down the line. (Infect is actually a good way to put it, bad floating point values are like viruses, they infect the rest of your systems making each one sick and spreading it to others.)
Soon your entire system is riddled with garbage floating point numbers throwing every calculation off. None of these may even necessarily cause immediate crashes but, instead, you get pathological behavior and things may simply stop working or behave in some very, very, bizarre ways. One example of how this sort of thing might cause an infinite loop is as follows. Let’s say that you have some sort of a hierarchical bounding volume tree that you traverse. Now, let’s say you are traversing it but with a bad floating point number. This could break the tree traversal in all sorts of unexpected ways since floating point compares may always fail when the expected behavior is that one side is always greater while the either side is always lesser. This could lead to infinite loops or missing results.
Soon your entire system is riddled with garbage floating point numbers throwing every calculation off. None of these may even necessarily cause immediate crashes but, instead, you get pathological behavior and things may simply stop working or behave in some very, very, bizarre ways. One example of how this sort of thing might cause an infinite loop is as follows. Let’s say that you have some sort of a hierarchical bounding volume tree that you traverse. Now, let’s say you are traversing it but with a bad floating point number. This could break the tree traversal in all sorts of unexpected ways since floating point compares may always fail when the expected behavior is that one side is always greater while the either side is always lesser. This could lead to infinite loops or missing results.
Another chance for bad floating point numbers to crash your code is if you convert a floating point number back into an integer which you then use to index an array with a bogus result.
By default most applications do not generate an exception when a bad floating point number is accessed. Exceptions can be enabled, but this can have unintended side effects. In general it is not valid for your middleware to change a global system wide setting like the floating point control word. You might enable exceptions to catch problems in your own code but then the application you are running inside of might suddenly start crashing or, worse yet, just turn them back off again.
Another thing to be aware of is how the floating point unit handles numeric precision and rounding behavior and the fact that it is not always preserved. It can be changed under your feet without you knowing about it! For this reason your API also needs to confirm that the floating point unit is always in the precision and rounding mode that your SDK expects and if it is ever changed, you should issue an error message and stop operating on the input data.
Since your code should never change the floating point unit state and, more to the point, our goal here is to never, ever, crash, then enabling exceptions that we do not handle gracefully is not really the solution.
Instead, the recommended course of action is to verify that each and every single floating point number passed into your API is valid by using the ‘isfinite’ check in the standard library.
In addition to making sure that all floating point numbers are valid, you should also make sure that they are within a ‘reasonable’ range. Just what a reasonable range means is specific to the context of your problem space. Let’s say this is for some kind of a game which has a world size that is never larger than 8 kilometers and is represented in meters. In this example any floating point number representing a ‘position’ that is outside of that range would be considered invalid.
Another thing to check for is normalization. Let’s say one of the values being passed into your API is supposed to represent a vector normal. All three floating point numbers could be perfectly valid, but that doesn't mean it is a valid normal. The same thing goes for matrices and quaternions.
To deal with these problems it requires that you perform full floating point validation not just for invalid numerics, but also numerics which are within range and appropriate for the use case.
By now you are probably wondering, isn't all of this going to be incredibly expensive and degrade performance?
The answer to that question is, probably yes. Here are ways to deal with this.
-
Your SDK can have multiple build configurations. One which is hardened to an extreme degree, a ‘checked’ build as it were, and one which does no, or fewer, checks and is typically called a ‘release’ or ‘shipping build.
-
Your SDK can have different levels of validation. You can even implement this as a run-time option; essentially by having each API call redirect to a different implementation that does the degree of validation required. This solution is a bit more difficult to implement but probably worth it, as it allows the developer to swap out which degree of checking they perform simply by changing a .INI file without requiring a different build of the game.
Rule #5 : Never trust any other parameter passed into your API : While we have discussed the validation of floating point numbers, the same degree of validation is required for all other parameters, whether it is an integer, or enumeration, or the contents of a data structure. All parameters passed into any method should be completely validated as much as is necessary to make sure they are in a reasonable range and express expected values.
Rule #6 : Always be thread safe! In this day and age you can never assume that any API call is not going to be interrupted by a call to another function, or even the same routine you are already executing, but from another thread. All API calls should have, at the minimum, a mutex to make sure that you don’t get burned by reentrancy and may, in fact, need a thread safe command queue if this is a common usage pattern.
Exceptions to the Rule
The rules above are required to create a nearly perfectly hardened API which can never, ever, be crashed because the user submitted bad input data.
It is also possible that even though the API is hardened, the application could still just stomp directly on some of your internal state data. There are some things you can do to detect and protect against this sort of thing but it is generally considered impractical. Short of making your SDK act as a kernel mode driver, some of these crazy abuses cannot be easily guarded against.
It is possible that they could still abuse your API by making unreasonable demands and requests on it, causing it to run very slowly or otherwise consume a great deal of CPU. Your code could have checks to detect this situation and allow it to bail out if a particular routine takes too long to execute and treat that as a warning or error.
At the end of the day, no matter how much you want to harden your API, these rules may ultimately be impractical. If the user needs to add millions of data items and the only way to do so is by making a million discrete API calls which are fully validated, this simply may not work.
You can break any of the rules above, just so long as you are aware of and willing to accept the risk that comes with it.
You could take the approach of having the vast majority of your API be fully hardened yet expose just a handful or routines which require high-speed data transmission to occur. This would make things mostly safe most of the time and the non-hardened API could be thoroughly documented in detail and would hopefully be a risk you could manage.
Features to make your life easier
There are a couple of features your SDK probably needs to keep your life from becoming a living hell. As soon as a customer has a problem that only happens in their product and cannot be reproduced outside of it, you will find yourself in a difficult situation. Usually you will not have source code access to their product and, even if you did, learning how to sync, build, and run their product could consume days, if not weeks, of your time.
There are a few key features you need to implement in your SDK to help deal with this. Most of these features will be much easier to write so long as you have used the API hardening rules above.
-
Logging : Your SDK should support extensive logging features. This goes beyond simply logging warnings, errors, and other poor usage patterns but even go so far as to log the contents of every single API call. You can, and should, support multiple levels of data logging detail. The data-logging should be easily human readable and act as a useful aid in diagnosing runtime problems. A lot of times just a quick look at a log can reveal to the support engineer, holy shit, they are calling the API this crazy way!!
-
API record / playback : This is probably the single most important piece of technology you should provide. No matter how long it takes you to implement a robust record and playback system, it will save you far more time than you would otherwise spend on product support. The concept is simple. Every single time the application makes a call into your SDK, you write the entire contents of that API to a stream (flushing the stream immediately). This process has to be so fast that it does not interfere with the operation of the actual product. Once you have a recording you should also have a separate application of your own which can play back that data. Imagine that your customer has a difficult to reproduce crash that only happens semi-randomly after running their product for an hour. Your hopes of debugging this in the traditional way would be bleak, but with a sufficiently powerful record and playback system there is real hope. The QA person would run the product with the recording feature enabled up until the problem occurs. It could be a crash (which really should not happen if your API is sufficiently hardened) or it could be a performance or behavior problem. They should be able to annotate the recording with metadata tags as well (text tags which indicate what was happening in the application over time). Once they have captured this file they can simply send it to you. With that file, and without needing access to their source code or product, you can reproduce this issue exactly and reproduce it deterministically every single time over and over again. No matter how much time you may spend developing this API capture and playback feature all of that effort will be paid back the first couple of times you can fix an issue using it. Remember that the API record/playback system must be able to take multi-threading into account. Many problems which happen in modern day software results from issues related to multithreading and reentrancy. For really tricky multi-threading issues there is a chance that a playback will not be able to reproduce the problem, so you should be aware there are some limitations with this approach.
-
Debug Visualization : Depending on the type of SDK you are creating it may be valuable to have a debug visualization tool which can render a meaningful picture of what is happening ‘inside’ of your engine.
-
Performance Tracking : Often times the reports of problems you will get from customers is not that your SDK is crashing but, instead, that it is consuming too many resources; be that CPU, GPU, or memory for example. Embedding robust and detailed performance tracking into your product can be invaluable. In this case, rather than writing your own from scratch, I strongly recommend you consider yet another piece of middleware, which is Telemetry from Rad Game Tools. It is an incredible tool which will allow you to easily embed many of these logging, analysis, and visualization features.
Conclusion
In conclusion I am not saying that you have to do these things, or even that you should. The point of this article is simply to present the extent and degree to which an API can be hardened against attack, either intentionally or not, by end users.
As extreme as all of these things sound, it is important to remember the real-world problems they are designed to address. If you develop a non-hardened API to be used by a general population of not necessarily expert programmers, you are going to run into a lot of problems. If you would like to spend more of your time developing cool technology and less of it in hopeless support tasks, tasks which most of the time are not even issues with your software, then you may want to consider some of these strategies.
If a lot of this may sound hypothetical but I assure you that it is not. I have developed a number of APIs in my career targeted at various audiences. Here are the real problems I have encountered, quite frequently in fact.
-
I have frequently been passed garbage pointers into routines and told it was my fault when it crashed in my code.
-
I have frequently been passed bad floating point numbers.
-
I have frequently been passed unreasonable floating point numbers that were far out of practical range.
-
I have frequently been passed invalid parameters, out of range and otherwise bogus.
-
I have frequently had an API get blindly called from all kinds of different threads in ways I never imagined anyone would, or could, do so.
-
I have frequently had people create insane or unreasonable content that caused performance to tank.
-
I have frequently had reports of problems that only happen in the context of someone’s larger product with no repro case made available.
-
I have frequently had people pass in garbage triangle mesh data, invalid normals, bad matrices, bad quaternions, and all manner of invalid and incorrect input data.
So, as you can see, none of this is hypothetical. This is the life of a middleware developer. Let’s be frank, frequently when someone is licensing a piece of technology it’s because they don’t actually understand it that well themselves. They think that if they license this piece of middleware it will magically solve all of their problems. However, all middleware has integration costs and requires a good conceptual understanding of the underlying technology so that it is not abused and misused.
If I was just writing something for myself and my personal colleagues, I probably would adopt only a few of these recommendations. However, if I was developing a piece of middleware going out to a wide audience that I had to support then I would probably do everything recommended here and more.
I hate to use the analogy but really I don’t see that I have any choice. You wouldn't have sex with a complete stranger without using a condom, you probably shouldn't let the users of your API do so without an equal degree of protection.
Postscript
I should probably address the elephant I left standing in the room here. Some people reading this are probably aware of middleware that I have been involved in and worked on. I would guess that those people are probably wondering how come the middleware I work on doesn't adopt hardly any of these recommendations. The answer to that is that it's not my middleware. I didn't create it and I don't own it. These recommendations are based on work that I have personally done in the past and, perhaps, some work I intend to do in the future. I hope this clarifies any questions you might have had on this point.
 一个人怎么才能混得好?恐怕各人都有一套说辞。但事实证据到底如何?图片来源:seanheritage.com
一个人怎么才能混得好?恐怕各人都有一套说辞。但事实证据到底如何?图片来源:seanheritage.com 激励在学习成功乃至找工作的过程中,都有突出的影响。图片来源:《新科学家》
激励在学习成功乃至找工作的过程中,都有突出的影响。图片来源:《新科学家》 *视唱(sight-reading)指拿到一份乐谱看谱即唱的技能,具体而言,是一种调动学生独立运用视觉、听觉、感觉进行积极思维活动练习识谱的技能训练,是学习音乐的基础学科之一。图片来源:《新科学家》
*视唱(sight-reading)指拿到一份乐谱看谱即唱的技能,具体而言,是一种调动学生独立运用视觉、听觉、感觉进行积极思维活动练习识谱的技能训练,是学习音乐的基础学科之一。图片来源:《新科学家》


 重复让音乐带给人特殊的聆听体验。
重复让音乐带给人特殊的聆听体验。






 侯世达对计算机程序的描述不仅准确,还富于创意,他对“我们大脑中的秘密软件结构”的描绘,开启了整整一代年轻人对AI的探索。图片来源:theatlantic.com
侯世达对计算机程序的描述不仅准确,还富于创意,他对“我们大脑中的秘密软件结构”的描绘,开启了整整一代年轻人对AI的探索。图片来源:theatlantic.com







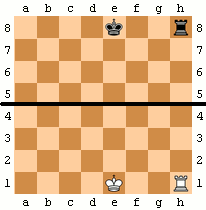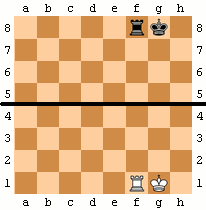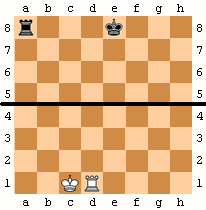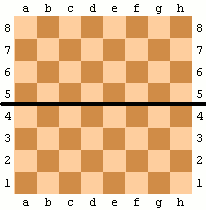








 , but we’re taking absolute values here, so it’s a bit more complicated than that. However, the expression does look pretty symmetric, so let’s see if we can do something with that. Name and conquer, so let’s define:
, but we’re taking absolute values here, so it’s a bit more complicated than that. However, the expression does look pretty symmetric, so let’s see if we can do something with that. Name and conquer, so let’s define: := |a + b| + |a - b|")
 = |b + a| + |b - a| = |a + b| + |-(a - b)| = \\ |a + b| + |a - b| = f(a,b)")
 = |a + (-b)| + |a - (-b)| = |a - b| + |a + b| = f(a,b)")
 = f(a,b)") for free – bonus! Putting all these together, we now know that
for free – bonus! Putting all these together, we now know that = f(b,a) = f(|a|,|b|) = | |a| + |b| | + | |a| - |b| |")
 and
and  are always non-negative, so in fact we have
are always non-negative, so in fact we have = |a| + |b| + | |a| - |b| |") .
. . In that case, we know the sign of the expression on the right and can simplify further:
. In that case, we know the sign of the expression on the right and can simplify further: = |a| + |b| + (|a| - |b|) = 2 |a|")
 , we get
, we get  = 2 |b|") . Putting the two together, we arrive at the conclusion
. Putting the two together, we arrive at the conclusion = 2 \max(|a|,|b|)")

 紧张感或者孤独感能够破坏免疫系统——有时候甚至到了危及生命的程度。图片来源:shutterstock
紧张感或者孤独感能够破坏免疫系统——有时候甚至到了危及生命的程度。图片来源:shutterstock 贫穷本身看上去也开始像是种疾病了。图片来源:shutterstock
贫穷本身看上去也开始像是种疾病了。图片来源:shutterstock 千百万年来我们一直是社会性动物。图片来源:shutterstock
千百万年来我们一直是社会性动物。图片来源:shutterstock
 要知道怎么做就必须得实际去做。计算机自动化所节省的那份苦力,恰恰是我们学习知识所必须付出的。图片来源:Kyle Bean/The Atlantic
要知道怎么做就必须得实际去做。计算机自动化所节省的那份苦力,恰恰是我们学习知识所必须付出的。图片来源:Kyle Bean/The Atlantic 大多数人都愿意相信,自动化能让我们把时间花在更高层次的追求上面,但不会改变我们行动或思考的方式。这是一种谬见——自动化学者称之为“替代神话”的说法。图片来源:inopalesolutions.com
大多数人都愿意相信,自动化能让我们把时间花在更高层次的追求上面,但不会改变我们行动或思考的方式。这是一种谬见——自动化学者称之为“替代神话”的说法。图片来源:inopalesolutions.com