
I can't believe I live in Toronto.

This post has taken several weeks in the making to compile. My hope is that this captures the vast majority of questions people have been asking recently with regard to Hachyderm.
To begin, I would like to start by introducing the state of Hachyderm before the migration, as well as introduce the problems we were experiencing. Next, I will cover the root causes of the problems, and how we found them. Finally, I will discuss the migration strategy, the problems we experienced, and what we got right, and what can be better. I will end with an accurate depiction of how hachyderm exists today.

Alice, our main on-premise server with her 8 SSDs. A 48 port Unifi Gigabit switch.
Photo: Kris Nóva
Hachyderm obtained roughly 30,000 users in 30 days; or roughly 1 new user every 1.5 minutes for the duration of the month of November.
I documented 3 medium articles during the month, each with the assumption that it would be my last for the month.
Here are the servers that were hosting Hachyderm in the rack in my basement, which later became known as “The Watertower”.
| Alice | Yakko | Wakko | Dot | |
|---|---|---|---|---|
| Hardware | DELL PowerEdge R630 2x Intel Xeon E5-2680 v3 | DELL PowerEdge R620 2x Intel Xeon E5-2670 | DELL PowerEdge R620 2x Intel Xeon E5-2670 | DELL PowerEdge R620 2x Intel Xeon E5-2670 |
| Compute | 48 Cores (each 12 cores, 24 threads) | 32 Cores (each 8 cores, 16 threads) | 32 Cores (each 8 cores, 16 threads) | 32 Cores (each 8 cores, 16 threads) |
| Memory | 128 GB RAM | 64 GB RAM | 64 GB RAM | 64 GB RAM |
| Network | 4x 10Gbps Base-T 2x | 4x 1Gbps Base-T (intel I350) | 4x 1Gbps Base-T (intel I350) | 4x 1Gbps Base-T (intel I350) |
| SSDs | 238 GiB (sda/sdb) 4x 931 GiB (sdc/sdd/sde/sdf) 2x 1.86 TiB (sdg/sdh) | 558 GiB Harddrive (sda/sdb) | 558 GiB Harddrive (sda/sdb) | 558 GiB Harddrive (sda/sdb) |
It is important to note that all of the servers are used hardware, and all of the drives are SSDs.
“The Watertower” sat behind a few pieces of network hardware, including large business fiber connection in Seattle, WA. Here are the traffic patterns we measured during November, and the advertised limitations from our ISP.
| Egress Advertised | Egress in Practice | Ingress Advertised | Ingress in Practice | |
|---|---|---|---|---|
| 200 Mbps | 217 Mbps | 1 Gbps | 112 Mbps |
Our busiest traffic day was 11/21/22 where we processed 999.80 GiB in RX/TX traffic in a single day. During the month of November we averaged 36.86 Mbps in traffic with samples taken every hour.
The server service layout is detailed below.

For the vast majority of November, Hachyderm had been stable. Most users reported excellent experience, and our systems remained relatively healthy.
On November 27th, I filed the 1st of what would become 21 changelogs for our production infrastructure.
The initial report was failing images in production. The initial investigation lead our team to discover that our NFS clients were behaving unreasonably slow.
We were able to prove that NFS was “slow” by trying to navigate to a mounted directory and list files. In the best cases results would come back in less than a second. In the worst cases results would take 10-20 seconds. In some cases the server would lock up and a new shell would need to be established; NFS would never return.

I filed a changelog, and mutated production. This is what became the first minor change in a week long crisis to evacuate the basement.
We were unable to fix the perceived slowness with NFS with my first change.
However we did determine that we had scaled our compute nodes very high in the process of investigating NFS. Load averages on Yakko, Wakko, and Dot were well above 1,000 at this time.
Each Yakko, Wakko, and Dot were housing multiple systemd units for our ingress, default, push, pull, and mailing queues – as well as the puma web server hosting Mastodon itself.
At this point Alice was serving our media over NFS, postgres, redis, and a lightweight Nginx proxy to load balance across the animaniacs (Yakko, Wakko, and Dot).
The problems began to cascade the night of the 27th, and continued to grow worse by the hour into the night.
The main observation was that the service would “flap”, almost as if it was deliberately toying with our psychology and our hope.

We would see long periods of “acceptable” performance when the site would “settle down”. Then, without warning, our alerts would begin to go off.
Hachyderm hosts a network of edge or point of presence (PoP) nodes that serve as a frontend caching mechanism in front of core.
During the “spikes” of failure, the edge Nginx logs began to record “Connection refused” messages.

The trend of “flapping” availability continued into the night. The service would recover and level out, then a spike in 5XX level responses, and then ultimately a complete outage on the edge.
This continued for several days.

It is important to note that Hachyderm had grown organically over the month of November. Every log that was being captured, every graph that was consuming data, every secret, every config file, every bash script – all – were a consequence of reacting to the “problem” of growth and adoption.
I call this out, because this is very akin to most of the production systems I deal with in my career. It is important to have empathy for the systems and the people who work on them. Every large production is a consequence of luck. This means that something happened that caused human beings to flock to your service.
I am a firm believer that no system is ever “designed” for the consequences of high adoption. This is especially true with regard to Mastodon, as most of our team has never operated a production Mastodon instance before. To be candid, it would appear that most of the internet is in a similar situation.
We are all experimenting here. Hachyderm was just “lucky” to see adoption.
There is no such thing as both a mechanistic and highly adopted system. All systems that are a consequence of growth, will be organic, and prone to the symptoms of reactive operations.
In other words, every ugly system is also a successful system. Every beautiful system, has never seen spontaneous adoption.
By the 3rd day we had roughly 20 changelogs filed.
Each changelog capturing the story of a highly motivated and extremely hopeful member of the team believing they had once and for all identified the bottleneck. Each, ultimately failing to stop the flapping of Hachyderm.
I cannot say enough good things about the team who worked around the clock on Hachyderm. In many cases we were sleeping for 4 hours a night, and bringing our laptops to bed with us.
After all of our research, science, and detection work we had narrowed down our problem two 2 disks on Alice.
/dev/sdg # 2Tb "new" drive
/dev/sdh # 2Tb "new" drive
The IOPS on these two particular drives would max out to 100% a few moments before the cascading failure in the rack would begin. We had successfully identified the “root cause” of our production problems.
Here is a graphic that captures the moment well. Screenshot taken from 2am Pacific on November 30th, roughly 3 days after production began to intermittently fail.

It is important to note that our entire production system, was dependent on these 2 disks, as well as our ZFS pool which was managing the data on the disks,
[novix@alice]: ~>$ df -h
Filesystem Size Used Avail Use% Mounted on
dev 63G 0 63G 0% /dev
run 63G 1.7G 62G 3% /run
/dev/sda3 228G 149G 68G 69% /
tmpfs 63G 808K 63G 1% /dev/shm
tmpfs 63G 11G 53G 16% /tmp
/dev/sdb1 234G 4.6G 218G 3% /home
/dev/sda1 1022M 288K 1022M 1% /boot/EFI
data/novix 482G 6.5G 475G 2% /home/novix
data 477G 1.5G 475G 1% /data
data/mastodon-home 643G 168G 475G 27% /var/lib/mastodon
data/mastodon-postgresql 568G 93G 475G 17% /var/lib/postgres/data
data/mastodon-storage 1.4T 929G 475G 67% /var/lib/mastodon/public/system
tmpfs 10G 7.5G 2.6G 75% /var/log
Both our main media block storage, and our main postgres database was currently housed on ZFS. The more we began to correlate the theory, the more we could correlate slow disks to slow databases responses, and slow media storage. Eventually our compute servers and web servers would max out our connection pool against the database and timeout. Eventually our web servers would overload the media server and timeout.
The timeouts would cascade out to the edge nodes and eventually cause:

We had found the root cause. Our disks on Alice were failing.
We had made the decision to evacuate The Watertower and migrate to Hetzner weeks prior to the incident. However it was becoming obvious that our “slow and steady” approach to setting up picture-perfect infrastructure in Hetzner wasn’t going to happen.
We needed off Alice, and we needed off now.
A few notable caveats about leaving The Watertower.
Unexpectedly I received a phone call from an old colleague of mine @Gabe Monroy at Digital Ocean. Gabe offered to support Hachyderm altruistically and was able to offer the solution of moving our block storage to Digital Ocean Spaces for object storage.
Thank you to Gabe Monroy, Ado Kukic, and Daniel Hix for helping us with this path forward! Hachyderm will forever be grateful for your support!
There was one concern, how were we going to transfer over 1Tb of data to Digital Ocean on already failing disks?
One of our infrastructure volunteers @malte had helped us come up with an extremely clever solution to the problem.
We could leverage Hachyderm’s users to help us perform the most meaningful work first.
Malte’s model was simple:
We can point the try_files directive back to Alice, and only serve the files from Alice once as they would be written back to S3 by the edge node accessing the files. Read try_files documentation.
In other words, the more that our users accessed Hachyderm, the faster our data would replicate to Digital Ocean. Conveniently this also meant that we would copy the data that was being immediately used first.
We could additionally run a slow rclone for the remaining data that is still running 2+ days later as I write this blog post.
This was the most impressive solution I have seen to a crisis problem in my history of operating distributed systems. Our users, were able to help us transfer our data to Digital Ocean, just by leveraging the service. The more they used Hachyderm, the more we migrated off Alice’s bad disks.
By the time the change had been in production for a few hours, we all had noticed a substantial increase in our performance. We were able to remove NFS from the system, and shuffle around our Puma servers, and sidekiq queues to reduce load on Postgres.
Alice was serving files from the bad disks, however all of our writes were now going to Digital Ocean.
While our systems performance did “improve” it was still far from perfect. HTTP(s) requests were still very slowly, and in cases would timeout and flap.
At this point it was easy to determine that Postgres (and it’s relationship to the bad disks) was the next bottleneck in the system.
Note: We still have an outstanding theory that ZFS, specifically the unbalanced mirrors, is also a contributing factor. We will not be able to validate this theory until the service is completely off Alice.
It would be slightly more challenging coming up with a clever solution to get Postgres off Alice.
On the morning of December 1st we finished replicating our postgres data across the atlantic onto our new fleet of servers in Hetzner.
We will be publishing a detailed architecture on the current system in Hetzner as we have time to finalize it.
Our team made an announcement that we were shutting production down, and scheduled a live stream to perform the work.
The video of the cutover is available to watch directly on Twitch.

The migration would not be complete without calling out that I was unable to build the Mastodon code base on our new primary Puma HTTP server.
After what felt like an eternity we discovered that we needed to recompile the NodeJS assets.
cd /var/lib/mastodon
NODE_OPTIONS=--openssl-legacy-provider
RAILS_ENV=production bundle exec rails assets:precompile
Eventually we were able to build and bring up the Puma server which was connected to the new postgres server.
We moved our worker queues over to the new servers in Hetzner.
The migration was complete.
To be candid, Hachyderm “just works” now and we are serving our core content within the EU in Germany.
There is an ever-growing smaller and smaller amount of traffic that is still routing through Alice as our users begin to access more and more obscure files.
Today we have roughly 700Gb of out 1.2Tb of data transferred to Digital Ocean.
We will be destroying the ZFS server in Alice, and replacing the disks as soon as we can completely take The Watertower offline.
On our list of items to cover moving forward:
We suffered from pretty common pitfalls in our system. Our main operational problems stemmed from scaling humans, and not our knowledge of how to build effective distirbuted systems. We have observability, security, and infrastructure experts from across Silicon Valley working on Hachyderm and we were still SSHing into production and sharing passwords.
In other words, our main limitations to scale were managing people, processes, and organizational challenges. Even determining who was responsible for what, was a problem within itself.
We had a team of experts without any formal precedent working together, and no legal structure or corporate organization to glue us together. We defaulted back to some bad habits in a pinch, and also uncovered some exciting new patterns that were only made possible because of the constraints of the fediverse.
Ultimately I believe that myself, and the entire team is convinced that the future of the internet and social is going to be in large collaborative operational systems that operate in a decentralized network.
We made some decisions during the process, such as keeping registrations open during the process that I agree with. I think I would make the same decisions again. Our limiting factor in Hachyderm had almost nothing to do with the amount of users accessing the system as much as it did the amount of data we were federating. Our system would have flapped if we had 100 users, or if we had 1,000,000 users. We were nowhere close to hitting limits of DB size, storage size, or network capacity. We just had bad disks.
I think the biggest risk we took was onboarding new people to a slow/unresponsive service for a few days. I am willing to accept that as a good decision as we are openly experimenting with this entire process.
I have said it before, and I will say it again. I believe in Hachyderm. I believe we can build a beautiful and effective social media service for the tech industry.
The key to success will be how well we experiment. This is the time for good old fashioned computer science, complete with thoughtful hypothesis and detailed observability to validate them.
Thank you to everyone who has been patient with Hachyderm as we have had to make some adjustments to how we do things. Finding ourselves launched into scale has impacted our people more than it has impacted our systems.
I wanted to provide some visibility into our intentions with Hachyderm, our priorities, and immediate initiatives.
We intend on offering transparency reports similar to the November Transparency Report from SFBA Social. It will take us several weeks before we will be able to publish our first one.
The immediate numbers from the administration dashboard are below.

On January 1st, 2023 we will be changing our financial model.
Hachyderm has been operating successfully since April of 2022 by funding our infrastructure from the proceeds of Kris Nóva’s Twitch presence.
In January 2023 we will be rolling out a new financial model intended to be sustainable and transparent for our users. We will be looking into donation and subscription models such as Patreon at that time.
From now until the end of the year, Hachyderm will continue to operate using the proceeds of Kris Nóva’s Twitch streams, and our donations through the ko-fi donation page.
We are considering forming a legal entity to control Hachyderm in January 2023.
At this time we are not considering a for-profit corporation for Hachyderm.
The exact details of what our decision is, will be announced as we come to conviction and seek legal advice.
At this time we do not have any plans to “cap” or limit user registration for Hachyderm.
There is a small chance we might temporarily close registration for small limited periods of time during events such as the DDoS Security Threat.
To be clear, we do not plan on rolling out a formal registration closure for any substantial or planned period of time. Any closure will be as short as possible, and will be opened up as soon as it is safe to do so.
We will be reevaluating this decision continuously. If at any point Hachyderm becomes bloated or unreasonably large we will likely change our decision.
At this time we do not believe that user registration will have an immediate or noticeable impact on the performance of our systems. We do not believe that closing registration will somehow “make Hachyderm faster” or “make the service more reliable”.
We will reevaluating this decision continuously. If at any point the growth patterns of Hachyderm changes we will likely change our decision.
We will be onboarding new moderators and operators in January to help with our service.
The existing teams will be spending the rest of December cleaning up documentation, and building out this community resource in a way that is easy for newcomers to be self sufficent with our services.
As moderators and infrastructure teams reach a point of sustainability, each will announce the path forward for volunteers when they feel the time is right.
The announcements page on this website, will be the source of truth.
Hachyderm has signed The Mastodon Server Covenant which means we have given our commitment to give users at least 3 months of advance warning in case of shutting down.
My personal promise is that I will do everything in my power to support our users any way I can that does not jeopardize the safety of other users or myself.
We will be forming a broader set of governance and expectation setting for our users as we mature our services and documentation.
I wanted to share a few thoughts on sustainability with Hachyderm.
Part of creating a sustainable service for our users will involve participation from everyone. We are asking that all Hachydermians remind themselves that time, patience, and empathy are some of the most effective ways in creating sustainable services.
There will be some situations where we will have to make difficult decisions with regard to priority. Often times the reason we aren’t immediately responding to an issue isn’t because we are ignoring the issue or oblivious to it. It is because we have to spend our time and effort wisely in order to keep a sustainable posture for the service. We ask for patience as it will sometimes take days or weeks to respond to issues, especially during production infrastructure issues.
We ask that everyone reminds themselves that pressuring our teams is likely counter productive to creating a sustainable environment.
Most people, when they become teachers, tell themselves that they won't do all the annoying things that their teachers did. If they teach for very long, though, they almost all find themselves slipping back to practices they didn't like as a student but which they now understand from the other side of the fence. Dynomight has written a nice little essay explaining why. Like deadlines. Why have deadlines? Let students learn and work at their own pace. Grade what they turn in, and let them re-submit their work later to demonstrate their newfound learning.
Indeed, why not? Because students are clever and occasionally averse to work. A few of them will re-invent a vexing form of the ancient search technique "Generate and Test". From the essay:
- Write down some gibberish.
- Submit it.
- Make a random change, possibly informed by feedback on the last submission.
- Resubmit it. If the grade improved, keep it, otherwise revert to the old version.
- Goto 3.
You may think this is a caricature, but I see this pattern repeated even in the context of weekly homework assignments. A student will start early and begin a week-long email exchange where they eventually evolve a solution that they can turn in when the assignment is due.
I recognize that these students are responding in a rational way to the forces they face: usually, uncertainty and a lack of the basic understanding needed to even start the problem. My strategy is to try to engage them early on in the conversation in a way that helps them build that basic understanding and to quiet their uncertainty enough to make a more direct effort to solve the problem.
Why even require homework? Most students and teachers want for grades to reflect the student's level of mastery. If we eliminate homework, or make it optional, students have the opportunity to demonstrate their mastery on the final exam or final project. Why indeed? As the essay says:
But just try it. Here's what will happen:
- Like most other humans, your students will be lazy and fallible.
- So many of them will procrastinate and not do the homework.
- So they won't learn anything.
- So they will get a terrible grade on the final.
- And then they will blame you for not forcing them to do the homework.
Again, the essay is written in a humorous tone that exaggerates the foibles and motivations of students. However, I have been living a variation of this pattern in my compilers course over the last few years. Here's how things have evolved.
I assign the compiler project as six stages of two weeks each. At the end of the semester, I always ask students for ways I might improve the course. After a few years teaching the course, students began to tell me that they found themselves procrastinating at the start of each two-week cycle and then having to scramble in the last few days to catch up. They suggested I require future students to turn something in at the end of the first week, as a way to get them started working sooner.
I admired their self-awareness and added a "status check" at the midpoint of each two-week stage. The status check was not to be graded, but to serve as a milepost they could aim for in completing that cycle's work. The feedback I provided, informal as it was, helped them stay course, or get back on course, if they had missed something important.
For several years, this approach worked really well. A few teams gamed the system, of course (see generate-and-test above), but by and large students used the status checks as intended. They were able to stay on track time-wise and to get some early feedback that helped them improve their work. Students and professor alike were happy.
Over the last couple of years, though, more and more teams have begun to let the status checks slide. They are busy, overburdened in other courses or distracted by their own projects, and ungraded work loses priority. The result is exactly what the students who recommended the status checks knew would happen: procrastination and a mad scramble in the last few days of the stage. Unfortunately, this approach can lead a team to fall farther and farther behind with each passing stage. It's hard to produce a complete working compiler under these conditions.
Again, I recognize that students usually respond in a rational way to the forces they face. My job now is to figure out how we might remove those forces, or address them in a more productive way. I've begun thinking about alternatives, and I'll be debriefing the current offering of the course with my students over the next couple of weeks. Perhaps we can find something that works better for them.
That's certainly my goal. When a team succeeds at building a working compiler, and we use it to compile and run an impressive program -- there's no feeling quite as joyous for a programmer, or a student, or a professor. We all want that feeling.
Anyway, check out the full essay for an entertaining read that also explains quite nicely that teachers are usually responding in a rational way to the forces they face, too. Cut them a little slack.
 |
mkalus
shared this story
from |
I was sent the new bluetooth personal stereo cassette player/recorder from 'We Are Rewind' - here's my evaluation. Non-affiliated link to the We Are Rewind website: https://www.wearerewind.com
MERCHANDISE
New Techmoan Merchandise is now available.
https://etsy.me/3zzjweo
SUBSCRIBE
http://www.youtube.com/user/Techmoan?sub_confirmation=1
SUPPORT
This channel can be supported through Patreon
https://www.patreon.com/techmoan
*******Patrons usually have early access to videos*******
OUTRO MUSIC
Over Time - Vibe Tracks https://youtu.be/VSSswVZSgJw
OUTRO SOUND EFFECT
ThatSFXGuy - https://youtu.be/5M3-ZV5-QDM
AFFILIATED LINKS/ADVERTISING NOTICE
All links are Affiliated where possible.
When you click on links to various merchants posted here and make a purchase, this can result in me earning a commission. Affiliate programs and affiliations include, but are not limited to, the eBay Partner Network & Amazon.
I am a participant in the Amazon Services LLC Associates Program, an affiliate advertising program designed to provide a means for sites to earn advertising fees by advertising and linking to AMAZON Sites (including, but not limited to Amazon US/UK/DE/ES/FR/NL/IT/CAN)
Regularly asked question
Q) Why are there comments from days ago when this video has just gone live today?
A) Patrons https://www.patreon.com/techmoan usually have early access to videos. I'll show the first version of a video on Patreon and often the feedback I get results in a video going through further revisions to improve it. e.g. Fix audio issues, clarify points, add extra footage or cut extraneous things out. The video that goes live on youtube is the final version. If you want to see the videos early and before any adverts are added, you can sign up to Patreon here: https://www.patreon.com/techmoan

|
mkalus
shared this story
from |
 "Building housing for the working class is completely off the table for the private sector"
"Building housing for the working class is completely off the table for the private sector" Even with the most optimistic assumptions -- that the land will be delivered clean of any residual toxics, that no demolition is required, that the state's Density Bonus law will apply, that no CEQA review will be required, and that the city will provide all necessary entitlements at no cost to the developer -- new private-sector housing in the neighborhoods doesn't make financial sense in today's market. It simply doesn't provide enough return on investment for the speculative capital that finances housing. [...]
Sup. Myrna Melgar, a former planning commissioner, told me she read the study and agrees: "It has nothing to do with the process." A year after the state forced the city to upzone everwhere, "nothing is moving," she said. "Not a single project." [...]
The problem isn't CEQA, or neighborhood appeals, or zoning. It's Capitalism, stupid.
Apropos of nothing, the other day I saw a small homeless encampment being "cleared" from my neighborhood -- which means, a bunch of people having all of their possessions, including their tents, tossed into a pickup truck and thrown away. Just another reminder that when Breed and Dorsey talk about being "tough on crime", what they mean by "crime" is "visible homelessness".
I hope all the police overtime protecting Union Square high end retail is going great, though!
Previously, previously, previously, previously, previously, previously.
|
mkalus
shared this story
from |
Du hast am Anfang einmal ein Investment, klar. Im besten Fall für die Umsetzung des Pflichtenheftes, das sich dann auch als korrekt herausstellt. Im Regelfall gibt es ein paar Iterationen, bis im Prozess der Umsetzung klar wird, was der Kunde eigentlich haben wollte, und dorthin schwenkt man dann halt um.
Aber dann? Irgendwann ist Schluss mit Investition, da trägt sich das dann von selbst. Klar, man hat vielleicht hie und da noch ein bisschen Wartungsaufwand.
Aber irgendwann, so spätestens ein paar Monate / ein Jahr nach Produktivgang, ist das Ding dann in einem Zustand, wo es den Return on Investment abwirft.
Ein Projekt, bei dem das Pflichtenheft keine groben Korrekturen brauchte, bei dem die Aufgabe relativ zeitnah erledigt werden konnte, und das Ding von da an im Wesentlichen ein Selbstläufer ist, war die Corona-Warnapp.
Umso irritierter bin ich gerade zu lesen, dass die Kosten für 2022 von 50 auf 73 Millionen explodieren. Ich persönlich finde ja, Telekom und SAP hätten die App kostenlos entwickeln sollen. Damit in der Bevölkerung die Tech-Industrie einmal für was anderes als Bauernfängerei und endlose Abzocke gestanden hätte. Ist ja nicht so, als bekämen beide Firmen nicht schon genug Steuergelder in den Arsch geschoben.
Ich kann mir das nur so erklären, dass die beiden Firmen annehmen, bei dem Controlling auf Regierungsseite weiß keiner, dass bei ihnen keine Kosten mehr entstanden sind, und dann halt wie üblich in der Branche voll auf Bauernfänigerei und endlose Abzocke umgeschwenkt haben.
Gar keine Kosten? Nein, da stehen ein paar Server in irgendeinem Rechenzentrum. Es gibt bestimmt auch einen Bugtracker, in dem sich ungefixte Meldungen anhäufen. Und es gibt ein Callcenter, in dem seit Monaten keiner mehr angerufen hat. Das Gesamtbudget dafür liegt so weit unter den hier diskutierten Geldmengen, dass man das als Rundungsfehler vernachlässigen kann. Selbst wenn man das bei anderen Abzocker-Tech-Bros wie Amazon in die Cloud stellt und dort Freudenhauspreise zahlt.
|
mkalus
shared this story
from |
 Scathing allegations against Mayor Breed and city in lawsuit filed over treatment of the homeless:
Scathing allegations against Mayor Breed and city in lawsuit filed over treatment of the homeless: Former San Francisco employees, including a director who worked with the homeless, allege that the city routinely cleared encampments while knowing there were not enough shelter beds available, according to new testimony filed in court Friday. [...]
In Friday's filings, Marshall said they were explicitly directed by the former head of the Department of Homelessness and Supportive Housing, Jeff Kositsky, to forcibly move unhoused people and destroy their property without taking the time to inquire about their needs.
The city cleared encampments in response to "daily mandates" by Mayor London Breed, Marshall stated: "Mayor Breed ordered us to carry out sweeps because she did not want to be seen near unhoused people while she was at lunch, at the gym, at fundraisers, or at meetings on public business." [...]
Marshall also suggested the method the department used to track shelter refusal was misleading. The Homelessness and Outreach Team would warn unhoused folks that the police were coming without taking steps to offer shelter, Marshall alleged. Despite the lack of offers, they wrote, the city recorded those individuals as having "refused" shelter, which Marshall called an "inaccurate and blatant attempt to work around the City's stated requirements for enforcement." [...]
When Public Works removes an encampment, staff are supposed to collect and log unhoused residents' belongings to be retrieved later [but they] often threw away residents' items altogether, due to a lack of time to sort out trash from belongings. "I have seen DPW workers throw away entire tents," Malone stated.

Attackers were able to take advantage of an exploit on the Ankr protocol to obtain around 183,000 aBNBc tokens for only 10 BNB (~$2,900). Before the Ankr exploit, which crashed the price of aBNBc, this many aBNBc tokens would have had a notional value of around $55.5 million. An issue with the price oracle on the staking platform Helio allowed attackers to borrow 16,444,740 HAY, a stablecoin intended to be pegged to the US dollar. The attackers then swapped those HAY for around $15 million in the BUSD stablecoin. Meanwhile, the HAY stablecoin lost its peg, crashing as low as $0.20.
There’s an exhibition at Tate Modern in London that you really should see if you get a chance: Magdalena Abakanowicz: Every Tangle of Thread and Rope. It’s on till May 2023. There’s a review and bio over at The Guardian:
Every Tangle of Thread and Rope traces Magdalena Abakanowicz’s development as a textile artist from the mid 1950s until the late century, beginning with designs for tapestries and jacquard punched cards for weaving, rows of leaf-shapes, colourways and tryouts for decorative fabrics, but soon expands, as did her art, into sculpture and installation art.
– The Guardian, Magdalena Abakanowicz review – so is that a nose or a testicle? (2022)
It’s all challenging, emotionally powerful stuff. The forest of giant fabric sculptures, immediately followed by a room of something like organs, seemed like an assault on walls. So much about interiors, but these slightly open sculptures so much like hung garments or rotted ancient trees, and the forest that you can be within without being contained… here’s an alternate way of being, being enacted right here.
Though it’s the tapestries that stick in my mind - patchworks of woven fabrics - and in particular, in the same room, an early piece made from jacquard punch cards.
Weaving, of course, being traditional “women’s work” and programmable jacquard looms being an industrialisation of weaving.
And Abakanowicz growing up in Poland in the Second World War… the connection I mean is not exactly the use of IBM’s technology by the Nazis for the Holocaust but… the Holocaust was enabled by population census data. Data was tabulated on Hollerith machines, which was the original purpose of these very first data processing machines when they had been invented in 1890 for the US Census (and which eventually became computers). Hollerith tabulators were popular; Hollerith had merged and become IBM; Hollerith punch cards (inspired by jacquard punch cards) became IBM punch cards.
So - and this is a guess, or a query I suppose - there may have been a connection for Abakanowicz between fascism and population control on the one side, and weaving and industrialisation on the other, mediated consciously or unconsciously by punch cards. The two are entangled, textiles and totalitarianism.
Another faint trail through these themes:
At home we have a treasured piece by the artist Hilary Ellis. Look at her portfolio (and WIP on Instagram) and imagine these works at scale: large textured canvases with repeated marks or stitches of thread.
There’s an explicit connection with women’s work:
… an enduring and persistent nature that dwells quietly within the realm of traditional womens’ work and its often futile repetitions. …
Using a variety of media, I produce repeated marks and actions that aim at exact replication, but whose inevitable deviations expose the frailty of the human hand in attempting the pursuit of mechanical process. …
– Hilary Ellis, artist statement
I mention Ellis because when I encountered her work, I thought I saw a connection to the work of Vera Molnar.
I first found Molnar’s pioneering computer-generated art in the 1976 book Artist and Computer (Amazon) in which editor Ruth Leavitt collects work and statements from a large number of contemporary artists. Wonderfully the entire book is online.
Vera Molnar explains her work (there are also examples there):
Using a computer with terminals like a plotter or/and a CRT screen, I have been able to minimize the effort required for this stepwise method of generating pictures. The samples of my work I give here in illustration were made interactively on a CRT screen with a program I call RESEAUTO. This program permits the production of drawings starting from an initial square array of like sets of concentric squares. …
And there’s a resemblance with Ellis think? Not a similarity, that’s not what I mean, but something generative about putting the works in dialogue in my head.
Then this interview with Vera Molnar, Weaving Variations:
“My work is like a textile,” Vera Molnar has told me
Molnar, like Abakanowicz, is an artist from Cold War Europe.
I don’t mean to draw connections where there aren’t any. (Though maybe that’s allowed!)
Nor do I don’t mean to (say) glamourise the hand in the weave and the ritual of repetition, opposing it to the horror of Hollerith punch cards in the formative infancy of computers; all three of these artists connect this territory in different ways. (Though holy shit we should talk about the military history of computing more.)
But it seems to me that there is some kind of nexus of weaving, mechanisation, women’s work - both the way it is performed and the way it is treated - computers and what computers do to us (or what we use computers to do to each other), power more generally…
Something something, I don’t know, I lack the tools to process these thoughts… and this is all so delicate and so faint and I know so little about any of it… but…
The Abakanowicz exhibition has stirred up so much in me. Do go check it out. Art!
|
mkalus shared this story . |
Toronto·New
Refugee children and youth do not place substantial demands on the health-care system in Ontario when compared with their Canadian-born peers, new research indicates.
· The Canadian Press ·
Refugee children and youth do not place substantial demands on the health-care system in Ontario when compared with their Canadian-born peers, new research indicates.
A study led by SickKids hospital in Toronto and non-profit research institute ICES compared 23,287 resettled refugees to 93,148 Ontario-born children and youth aged under 17 from 2008 to 2018.
It found that health-care utilization is generally high among refugees but overall excess demand on the health system is minimal during their first year in Canada.
"While our study is reassuring in terms of the high levels of primary care use in the first year, refugee groups with high health needs may benefit from specialized and integrated community-based primary care ... to ensure a positive health trajectory for all resettled refugee children," senior author Dr. Astrid Guttmann, chief science officer at ICES, wrote in a statement.
The study, published in the peer-reviewed journal Pediatrics, showed that health-care use among refugees varies by their sponsorship model, with health costs higher among government-sponsored refugees compared with privately sponsored refugees.
"We don't know enough about how the private and blended models meet the health-care needs of resettled refugees, compared to the government-assisted refugee program," lead author Dr. Natasha Saunders wrote in a statement.
Saunders said many refugee children arrive needing care for issues related to infection, malnutrition or dental needs.
"Private sponsorship models may have an impact on how refugees navigate and access health services," she said.
Canada's Government Assisted Refugees program provides all funding, support and connections to refugee resettlement services, largely through service provider organizations.
Meanwhile, two programs allow private citizens and permanent residents to sponsor refugees and provide full or partial support to them.
One program sees sponsors support the newcomers financially during their first year and help them navigate health and social services. Another program, called the "blended visa office-referred program," allows sponsors to share costs and resettlement support with the government.
Refugees arriving through all three programs are eligible for provincial health insurance.
Privately sponsored refugees had the lowest reported rates of major illnesses after one year, the research indicated.
The study found that the use of mental health services is low among all refugee groups and noted that some children may be accessing mental health support through community resources.
The UN refugee agency said Canada has welcomed more than one million refugees since 1980 and the country came first in the world in 2019 in terms of the number of accepted refugees, with more than 30,000 refugees arriving in Canada that year.
|
mkalus shared this story . |
The province has released an independent report that makes 26 recommendations, such as being better prepared, more transparent and fostering public trust, for how the government could improve its handling of the COVID-19 pandemic.
"Overall, despite being unprepared for a provincewide emergency, the Government of British Columbia's response to the COVID-19 pandemic was strong, showing resilience, balance, and nimbleness that should give British Columbians confidence in its ability to respond to future provincewide emergencies," reads the executive summary of the 144-page report, simply called COVID-19 Lessons Learned Review.
It was prepared by three authors — Bob de Faye, Dan Perrin, and Chris Trumpy, all former civil servants —who generally praised the province for its handling of the health emergency that began in March of 2020.
Still, the report says the health emergency provided the province with an "opportunity" to be better prepared to respond to similar emergencies in future by acting ahead of time, making changes to its emergency management plan and how to better serve and co-ordinate with First Nations.
The province commissioned the report as an operational overview of its response to the pandemic, which to date has claimed the lives of 4,642 people in B.C.
In March, when the undertaking was announced the Opposition Liberals were critical saying the report would be limited because it would exclude any examination of public health decisions and economic recovery actions.
The report's authors conducted public engagement and consultation with First Nations and government stakeholders. It spoke directly with 200 people and received 15,000 responses and 3,000 pages of written comment.
It also compared B.C.'s response to that of Canada's four other most populous provinces.
The report says that, overall, B.C.'s public health measures were less restrictive than other provinces and had the highest increase in program spending.
The report found that B.C. also had a "slightly" higher vaccination rate than other jurisdictions and lower rates of COVID-19 infections and deaths.
Economically, the report said B.C. fared at least as well as the other jurisdictions in Canada, with employment recovering to pre-pandemic levels by July 2021.
The report makes 26 findings and conclusions in six categories which are trust, preparation, decision-making, communication, implementation and how pandemic response affected Indigenous people.
Mike Farnworth, the minister of public safety and solicitor general said the findings are being seen by his government as de facto recommendations, and action will be taken.
"All things considered, B.C. did a pretty remarkable job, Are there lessons to be learned?" he said during a news conference Friday afternoon. "Absolutely, because you always want to do better."
The report said B.C.'s initial response to the pandemic was undertaken through its Emergency Management B.C. (EMBC) plan, but its format, which involves a small group of decision-makers, created gaps in the co-ordination of an all-government response.
Concerns were also raised about how transparent the province was over whether public-health care decisions were supported by or followed scientific evidence.
The report recommends that there be increased transparency over the process.
"That could include establishing one or more formal advisory groups to support the public health officer and public health decisions," it reads.
The report also makes suggestions for how B.C. used data during the pandemic, something that the province has been routinely scrutinized for.
The report said that public health decision-makers struggled to access data because technology systems at hospitals and within health authorities are not integrated and working together.
"The requirement to manually compile hospitalization data highlighted longstanding issues that have for decades proven resistant to resolution," reads the report.
The report found that trust in government was relatively high throughout the pandemic, up to August 2022 but then began a downward trend. It recommends that "ways be found to rebuild trust, which will be necessary to support compliance with future restrictive measures should they be needed."
In a statement, Farnworth welcomed the feedback from the authors of the report and said work was already underway to address the shortcomings it highlights.
"The review's findings will aid the Province as it continues the work to modernize its emergency management legislation, which will be introduced in spring 2023," it said.
The Ministry of Health and EMBC have also begun work to identify how the provincial pandemic co-ordination plan could be updated.
The statement said that EMBC is also participating in Exercise Coastal Response in February 2023, where logistics-related emergency response activities can be tested as a part of broader supply chain management.
This week I published the first alpha release of Datasette 1.0, with a significant new feature: Datasette core now includes a JSON API for creating and dropping tables and inserting, updating and deleting data.

Combined with Datasette's existing APIs for reading and filtering table data and executing SELECT queries this effectively turns Datasette into a SQLite-backed JSON data layer for any application.
If you squint at it the right way, you could even describe it as offering a NoSQL interface to a SQL database!
My initial motivation for this work was to provide an API for loading data into my Datasette Cloud SaaS product - but now that I've got it working I'm realizing that it can be applied to a whole host of interesting things.
I shipped the 1.0a0 alpha on Wednesday, then spent the last two days ironing out some bugs (released in 1.0a1) and building some illustrative demos.
My first demo reuses my scrape-hacker-news-by-domain project from earlier this year.
https://news.ycombinator.com/from?site=simonwillison.net is the page on Hacker News that shows submissions from my blog. I like to keep an eye on that page to see if anyone has linked to my work.

Data from that page is not currently available through the official Hacker News API... but it's in an HTML format that's pretty easy to scrape.
My shot-scraper command-line browser automation tool has the ability to execute JavaScript against a web page and return scraped data as JSON.
I wrote about that in Scraping web pages from the command line with shot-scraper, including a recipe for scraping that Hacker News page that looks like this:
shot-scraper javascript \ "https://news.ycombinator.com/from?site=simonwillison.net" \ -i scrape.js -o simonwillison-net.json
Here's that scrape.js script.
I've been running a Git scraper that executes that scraping script using GitHub Actions for several months now, out of my simonw/scrape-hacker-news-by-domain repository.
Today I modified that script to also publish the data it has scraped to my personal Datasette Cloud account using the new API - and then used the datasette-atom plugin to generate an Atom feed from that data.
Here's the new table in Datasette Cloud.
This is the bash script that runs in GitHub Actions and pushes the data to Datasette:
export SIMONWILLISON_ROWS=$(
jq -n --argjson rows "$(cat simonwillison-net.json)" \
'{ "rows": $rows, "replace": true }'
)
curl -X POST \
https://simon.datasette.cloud/data/hacker_news_posts/-/insert \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DS_TOKEN" \
-d "$SIMONWILLISON_ROWS"$DS_TOKEN is an environment variable containing a signed API token, see the API token documentation for details.
I'm using jq here (with a recipe generated using GPT-3) to convert the scraped data into the JSON format needeed by the Datasette API. The result looks like this:
{
"rows": [
{
"id": "33762438",
"title": "Coping strategies for the serial project hoarder",
"url": "https://simonwillison.net/2022/Nov/26/productivity/",
"dt": "2022-11-27T12:12:56",
"points": 222,
"submitter": "usrme",
"commentsUrl": "https://news.ycombinator.com/item?id=33762438",
"numComments": 38
}
],
"replace": true
}This is then POSTed up to the https://simon.datasette.cloud/data/hacker_news_posts/-/insert API endpoint.
The "rows" key is a list of rows to be inserted.
"replace": true tells Datasette to replace any existing rows with the same primary key. Without that, the API would return an error if any rows already existed.
The API also accepts "ignore": true which will cause it to ignore any rows that already exist.
Full insert API documentation is here.
Before I could insert any rows I needed to create the table.
I did that from the command-line too, using this recipe:
export ROWS=$(
jq -n --argjson rows "$(cat simonwillison-net.json)" \
'{ "table": "hacker_news_posts", "rows": $rows, "pk": "id" }'
)
# Use curl to POST some JSON to a URL
curl -X POST \
https://simon.datasette.cloud/data/-/create \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DS_TOKEN" \
-d $ROWSThis uses the same trick as above, but hits a different API endpoint: /data/-/create which is the endpoint for creating a table in the data.db database.
The JSON submitted to that endpoint looks like this:
{
"table": "hacker_news_posts",
"pk": "id",
"rows": [
{
"id": "33762438",
"title": "Coping strategies for the serial project hoarder",
"url": "https://simonwillison.net/2022/Nov/26/productivity/",
"dt": "2022-11-27T12:12:56",
"points": 222,
"submitter": "usrme",
"commentsUrl": "https://news.ycombinator.com/item?id=33762438",
"numComments": 38
}
]
}It's almost the same shape as the /-/insert call above. That's because it's using a feature of the Datasette API inherited from sqlite-utils - it can create a table from a list of rows, automatically determining the correct schema.
If you already know your schema you can pass a "columns": [...] key instead, but I've found that this kind of automatic schema generation works really well in practice.
Datasette will let you call the create API like that multiple times, and if the table already exists it will insert new rows directly into the existing tables. I expect this to be a really convenient way to write automation scripts where you don't want to bother checking if the table exists already.
My end goal with this demo was to build an Atom feed I could subscribe to in my NetNewsWire feed reader.
I have a plugin for that already: datasette-atom, which lets you generate an Atom feed for any data in Datasette, defined using a SQL query.
I created a SQL view for this (using the datasette-write plugin, which is installed on Datasette Cloud):
CREATE VIEW hacker_news_posts_atom as select id as atom_id, title as atom_title, url, commentsUrl as atom_link, dt || 'Z' as atom_updated, 'Submitter: ' || submitter || ' - ' || points || ' points, ' || numComments || ' comments' as atom_content from hacker_news_posts order by dt desc limit 100;
datasette-atom requires a table, view or SQL query that returns atom_id, atom_title and atom_updated columns - and will make use of atom_link and atom_content as well if they are present.
Datasette Cloud defaults to keeping all tables and views private - but a while ago I created the datasette-public plugin to provide a UI for making a table public.
It turned out this didn't work for SQL views yet, so I fixed that - then used that option to make my view public. You can visit it at:
https://simon.datasette.cloud/data/hacker_news_posts_atom
And to get an Atom feed, just add .atom to the end of the URL:
https://simon.datasette.cloud/data/hacker_news_posts_atom.atom
Here's what it looks like in NetNewsWire:
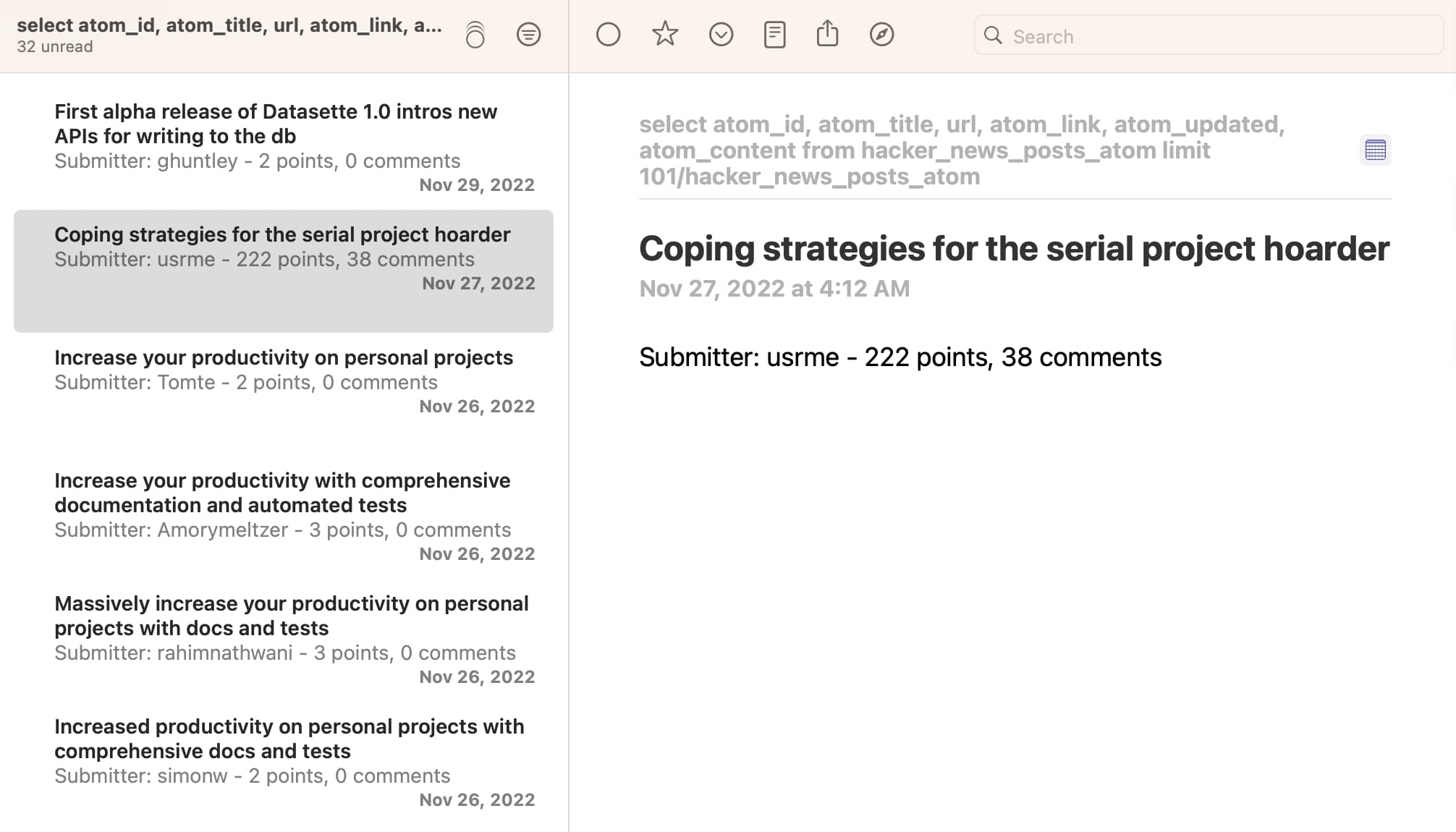
I'm pretty excited about being able to combine these tools in this way: it makes getting from scraped data to a Datasette table to an Atom feed a very repeatable process.
My second demo explores what it looks like to develop custom applications against the new API.
TodoMVC is a project that provides the same TODO list interface built using dozens of different JavaScript frameworks, as a comparison tool.
I decided to use it to build my own TODO list application, using Datasette as the backend.
You can try it out at https://todomvc.datasette.io/ - but be warned that the demo resets every 15 minutes so don't use it for real task tracking!
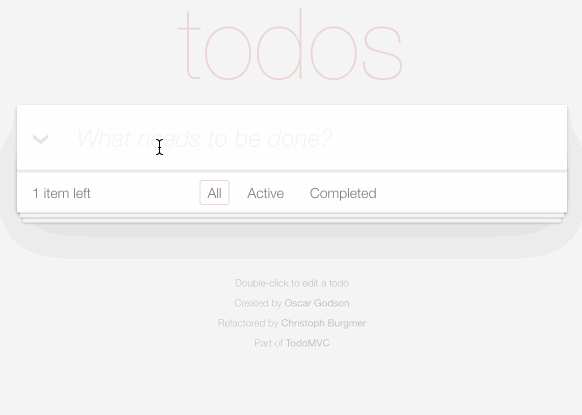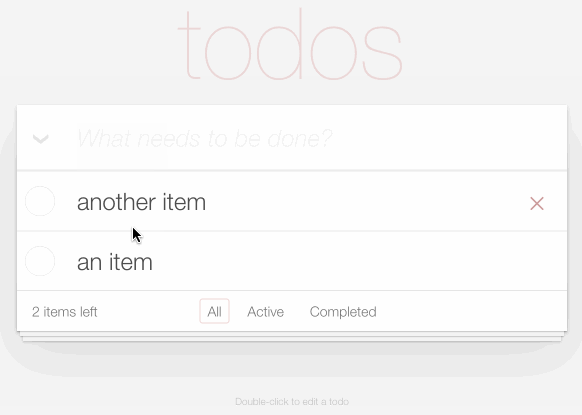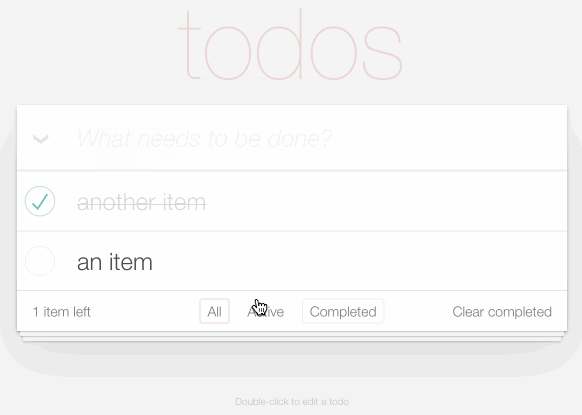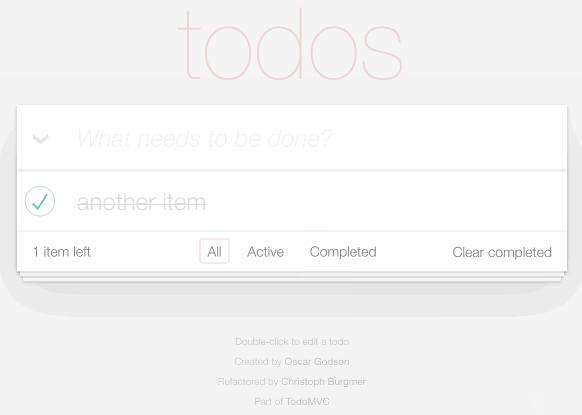
The source code for this demo lives in simonw/todomvc-datasette - which also serves the demo itself using GitHub Pages.
The code is based on the TodoMVC Vanilla JavaScript example. I used that unmodified, except for one file - store.js, which I modified to use the Datasette API instead of localStorage.
The demo currently uses a hard-coded authentication token, which is signed to allow actions to be performed against the https://latest.datasette.io/ demo instance as a user called todomvc.
That user is granted permissions in a custom plugin at the moment, but I plan to provide a more user-friendly way to do this in the future.
A couple of illustrative snippets of code. First, on page load this constructor uses the Datasette API to create the table used by the application:
function Store(name, callback) {
callback = callback || function () {};
// Ensure a table exists with this name
let self = this;
self._dbName = `todo_${name}`;
fetch("https://latest.datasette.io/ephemeral/-/create", {
method: "POST",
mode: "cors",
headers: {
Authorization: `Bearer ${TOKEN}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
table: self._dbName,
columns: [
{name: "id", type: "integer"},
{name: "title", type: "text"},
{name: "completed", type: "integer"},
],
pk: "id",
}),
}).then(function (r) {
callback.call(this, []);
});
}Most applications would run against a table that has already been created, but this felt like a good opportunity to show what table creation looks like.
Note that the table is being created using /ephemeral/-/create - this endpoint that lets you create tables in the ephemeral database, which is a temporary database that drops every table after 15 minutes. I built the datasette-ephemeral-tables plugin to make this possible.
Here's the code which is called when a new TODO list item is created or updated:
Store.prototype.save = function (updateData, callback, id) {
// {title, completed}
callback = callback || function () {};
var table = this._dbName;
// If an ID was actually given, find the item and update each property
if (id) {
fetch(
`https://latest.datasette.io/ephemeral/${table}/${id}/-/update`,
{
method: "POST",
mode: "cors",
headers: {
Authorization: `Bearer ${TOKEN}`,
"Content-Type": "application/json",
},
body: JSON.stringify({update: updateData}),
}
)
.then((r) => r.json())
.then((data) => {
callback.call(self, data);
});
} else {
// Save it and store ID
fetch(`https://latest.datasette.io/ephemeral/${table}/-/insert`, {
method: "POST",
mode: "cors",
headers: {
Authorization: `Bearer ${TOKEN}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
row: updateData,
}),
})
.then((r) => r.json())
.then((data) => {
let row = data.rows[0];
callback.call(self, row);
});
}
};TodoMVC passes an id if a record is being updated - which this code uses as a sign that the ...table/row-id/-/update API should be called (see update API documentation).
If the row doen't have an ID it is inserted using table/-/insert, this time using the "row": key because we are only inserting a single row.
The hardest part of getting this to work was ensuring Datasette's CORS mode worked correctly for writes. I had to add a new Access-Control-Allow-Methods header, which I shipped in Datasette 1.0a1 (see issue #1922).
I built the datasette-ephemeral-tables plugin because I wanted to provide a demo instance of the write API that anyone could try out without needing to install Datasette themselves - but that wouldn't leave me responsible for taking care of their data or cleaning up any of their mess.
You're welcome to experiment with the API using the https://latest.datasette.io/ demo instance.
First, you'll need to sign in as a root user. You can do that (no password required) using the button on this page.
Once signed in you can view the ephemeral database (which isn't visible to anonymous users) here:
https://latest.datasette.io/ephemeral
You can use the API explorer to try out the different write APIs against it here:
https://latest.datasette.io/-/api
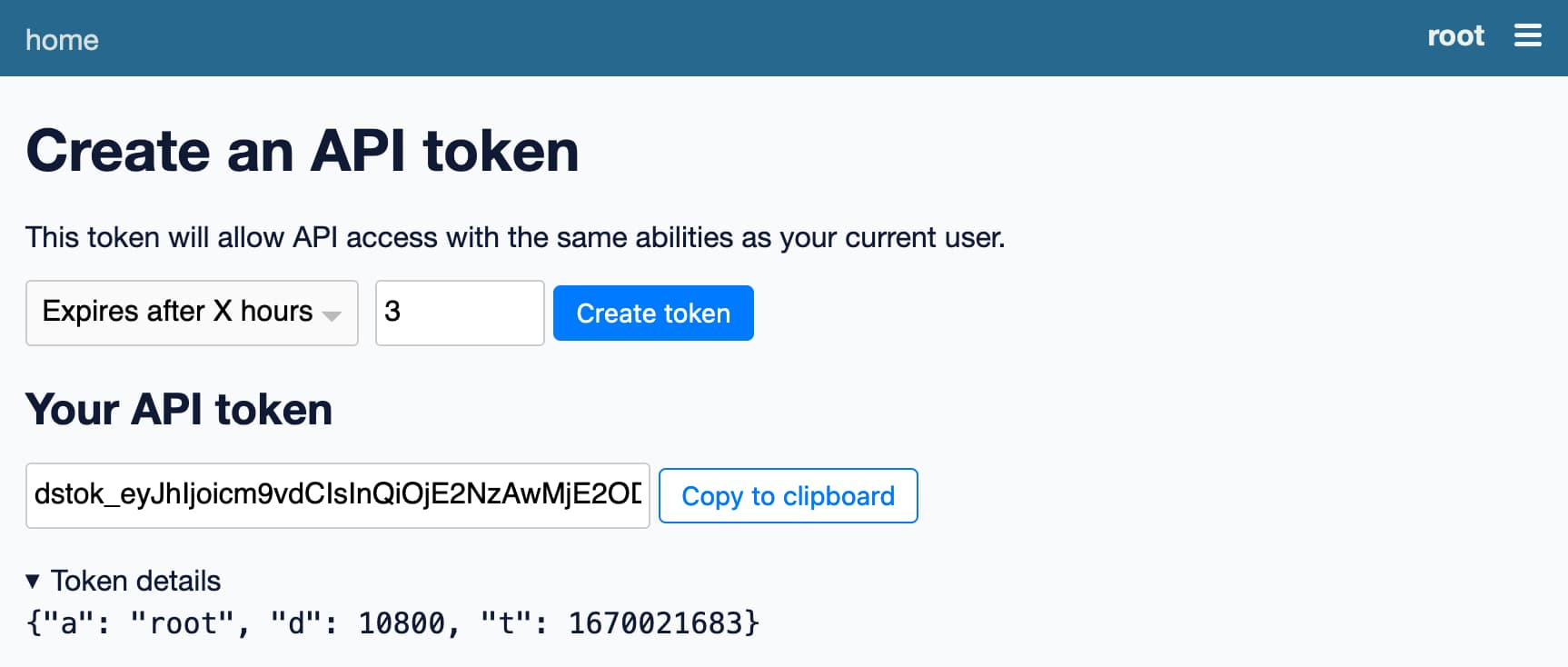
And you can create your own signed token for accessing the API on this page:
https://latest.datasette.io/-/create-token
The TodoMVC application described above also uses the ephemeral database, so you may see a todo_todos-vanillajs table appear there if anyone is playing with that demo.
You can install the latest Datasette alpha like this:
pip install datasette==1.0a1
Then create a database and sign in as the root user in order to gain access to the API:
datasette demo.db --create --root
Click on the link it outputs to sign in as the root user, then visit the API explorer to start trying out the API:
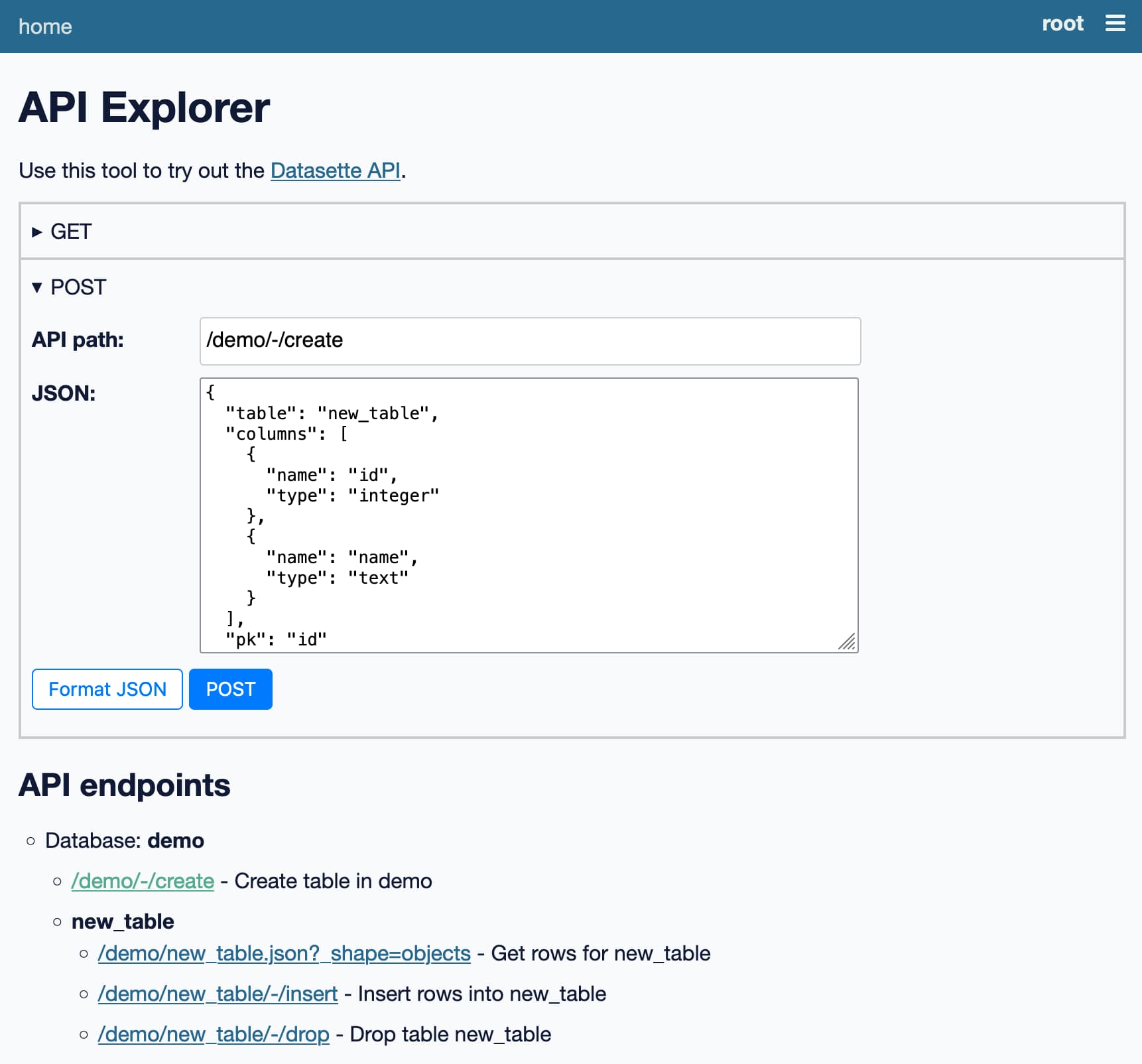
The API explorer works without a token at all, using your existing browser cookies.
If you want to try the API using curl or similar you can use this page to create a new signed API token for the root user:
http://127.0.0.1:8001/-/create-token
This token will become invalid if you restart the server, unless you fix the DATASETTE_SECRET environment variable to a stable string before you start the server:
export DATASETTE_SECRET=$(
python3 -c 'print(__import__("secrets").token_hex(16))'
)
Check the Write API documentation for more details.
If you have feedback on these APIs, now is the time to share it! I'm hoping to ship Datasette 1.0 at the start of 2023, after which these APIs will be considered stable for hopefully a long time to come.
If you have thoughts or feedback (or questions) join us on the Datasette Discord. You can also file issue comments against Datasette itself.
My priority for the next 1.0 alpha is to bake in a small number of backwards incompatible changes to other aspects of Datasette's JSON API that I've been hoping to include in 1.0 for a while.
I'm also going to be rolling out API support to my Datasette Cloud preview users. If you're interested in trying that out you can request access here.

Hi SUMO folks,
I’m delighted to share this news with you. The Hubs team has recently transitioned into a new phase of a product. If in the past, you needed to figure out the hosting and deployment on your own with Hubs Cloud, you now have the option to simply subscribe to unlock more capabilities to customize your Hubs room. To learn more about this transformation, you can read their blog post.
Along with this relaunch, Mozilla has also just acquired Active Replica, a team that shares Mozilla’s passion for 3D development. To learn more about this acquisition, you can read this announcement.
To support this change, the SUMO team has been collaborating with the Hubs team to update Hubs help articles that we host on our platform. We also recently removed Hubs AAQ (Ask a Question) from our forum, and replaced it with a contact form that is directly linked to our paid support infrastructure (similar to what we have for Mozilla VPN and Firefox Relay).
Paying customers of Hubs will need to be directed to file a support ticket via the Hubs contact form which will be managed by our designated staff members. Though contributors can no longer help with the forum, you are definitely welcome to help with Hubs’ help articles. There’s also a Mozilla Hubs Discord server that contributors can pop into and participate in.
We are excited about the new direction that the Hubs team is taking and hope that you’ll support us along the way. If you have any questions or concerns, we’re always open to discussion.

The BNB Chain-based Ankr defi protocol suffered an exploit of their aBNBc token. "We are currently working with exchanges to immediately halt trading," they wrote. However, the attacker had already bridged and tumbled around $5 million in funds from the exploit before the announcement was even made.
The attacker, and possible subsequent copycat attackers, used a vulnerability in the project smart contract to mint quadrillions of aBNBc, which they then swapped to various other tokens.
Binance halted trading on aBNBc tokens, as well as on HAY tokens, a stablecoin project that was subsequently exploited. Ankr also tweeted that "We have been in touch with the [decentralized exchanges] and told them to block trading", although decentralized exchanges are typically not supposed to be able to "block trading".
After watching the recent 3Blue1Brown video on convolutions I realized that there is a surprising lack of articles on convolutions as they apply to probability. If you search online for "convolution" you will discover about a billion posts on "convolutional neural networks", which is a bit unfortunate since CNNs don't technically use convolutions (they use correlations, though there's a reasonable argument it doesn't matter) and convolution plays a very important and practical role in probability. Not to mention that viewing convolution from the perspective of probability might be one of the easiest ways of understanding it!
So in this post we're going to take a look at how to use convolutions, how to compute them and how they are defined mathematically... and we'll also throw in a bit of mad-science!

A bit too much data science ultimately leads to other career options.
Callout: Before even beginning with the rest of this post I need to give special mention to Steven W. Smith's absolutely phenomenal Guide to Digital Signal Processing. This is the book that really made convolutions click for me and was a huge inspiration in writing this post. As an homage I have tried to make all my charts in a similar style to the ones he uses in his book. Now let's continue!
At a high level, in probability, a convolution is the way to determine the distribution of the sum of two random variables. That is, we can see it as a way of combine two probability distributions to create a third distribution, in much the same way we might use multiplication to combine two integers to make a third. This is very useful because, in all but a few special cases, the distribution of the sum of two random variables is not the same as the distribution that each of individual random variable.
A notable and fortunate exception regarding summing two random variables is the case of normally distributed random variables. For example suppose we have these two random variables that are normally distributed:
$$X \sim \mathcal{N}(\mu_x, \sigma_x)$$
$$Y \sim \mathcal{N}(\mu_y, \sigma_y)$$
That is we have two random values sampled from two different normal distributions. It's easy to imagine a scenario when we want to know what the distribution the sum of these might be:
$$Z = X + Y$$
$$Z \sim ?$$
It turns out that there is a very pleasant analytic solution to this:
$$Z \sim \mathcal{N}(\mu_x + \mu_y, \sqrt{\sigma_x^2 + \sigma_y^2})$$
If you aren't familiar with this wonderful fact then this post has already been worth your time, as this is a very useful tool to have for many probability problems.
The trouble is that not all real world probability distributions are well defined and most well defined probability distributions don't have this pleasant property. Convolutions are important because they allow us to define this operation (at least mathematically) on any probability distribution. Convolutions are particularly useful when we want to solve this problem for arbitrary discrete distributions.
We're going to adopt some notation that we'll be using throughout the post. We'll consider our two probability distributions \(f\) and \(g\), each will take argument \(t\) representing the value we want to know the probability of. Much of the work of convolutions comes out of the world of signal processing so \(t\) typically means "time", but we'll think of it more as an index.
Because we're going to make heavy use of discrete convolutions in the post we'll alternate between using \(f(t)\) when we want to think of our distribution of a function and \(f[t]\) when we want to think of it as an array. In either case this will mean "the probability of \(t\)".
The symbol used for convolutions is \(\ast\) and we typically denote the convolution of two functions as:
$$f\ast g = h$$
We'll stick to denoting the result of our convolution with \(h\). And since the result of the convolution is itself another probability distribution we can pass \(t\) into the result of convolution as well:
$$(f \ast g)(t)$$
With this we can make a generalized version of our sum of normal random variables we performed before:
$$X \sim f$$
$$P(X = t) = f(t)$$
$$Y \sim g$$
$$P(Y = t) = g(t)$$
$$Z = X + Y$$
$$Z \sim f \ast g$$
$$h = (f \ast g)$$
$$P(Z = t) = h(t) = (f \ast g)(t)$$
This latter notation will work to describe the result of any probability distribution, not just normals. Now computing those results is another issue. Let's start with our horrific example!
In the post we're going to explore the very common problem of constructing a horrific monstrosity which is the fusion of a crab and a human wielding a chainsaw.

A good example of a Crab-Man monster
If you've ever done much mad science you'll know that a major problem is selectively determining the best crab and best chainsaw wielding human to use as candidates. After all some crabs are just tasty snacks and some men wielding chainsaws are just lumber jacks... that would yield a lumber snack! Hardly the monster you're hoping for.
The common way to solve this is to have tournaments where crabs fight crabs and humans fight humans. This yields the strongest, toughest and meanest of each species as inputs into our final creation.

Crab fights (and chainsaw fights) typically end up in the loss of limbs.
This leads to another big problem: missing limbs. The only downside of our tournaments is that fights between crabs and fights between chainsaw wielding dudes tend to leave the winner shy a few limbs. This is important because the total limbs of the final monster equal the combined limbs of the crab and human.
For the record: humans have up to 4 limbs and crabs have up to 10.
Now it would be awesome to have a 14 armed chainsaw crabman, but we'll settle for just 4, heck 3 works so long as it can chase and chainsaw! What we want to do is take the distribution of human limbs after the fight, the distribution of crab limbs after their fight and use convolution to determine the distribution of monster limbs!
Here we can see the distribution of human limbs after many rounds of chainsaw combat:

The distribution of human limbs remaining after our brutal chainsaw tournament.
For notation we'll consider the random variable representing human limbs remaining to be \(X\), and sampled from a distribution function \(f\).
$$X \sim f$$
We'll treat \(f\) as an array for most of this post since we have discrete values here. Note that there are 5 possible values since no limbs at all is a possibility.
Here is the distribution of crab limbs:

I actually didn’t know crabs had 10 limbs, I thought only 6 legs and 2 claws, but it is in fact 10!
The number of crab limbs remaining will be denoted by \(Y\) and sampled from a distribution \(g\).
$$Y \sim g$$
What we want know is to now is the final monster distribution \(Z\). Notationally our solution is going to be:
$$h = (f \ast g)$$
$$Z \sim h$$
But what does \(h\) look like and how can we compute it?
First let's make sure we're thinking of \(f\), \(g\) and \(h\) as 0 indexed arrays where each index holds the value of the probability of that index. That is \(h[5]\) is the probability that the monster has 5 limbs and \(f[0]\) is the probability that the chainsaw wielding man has no limbs.
One important thing to realize is that, as an array (or as a signal), \(h\) is larger than \(f\) or \(g\). In fact the length of \(h\) is always going the length of \(f\) + the length of \(g\) minus 1. This makes logical sense since our monster will have between 0 and 14 legs, so there are 15 possible values.
It's quite possible you have solved this problem before in code. I know I have without even knowing what a convolution was!
One way that might come naturally is to think about this from the perspective of the inputs. We'll start by building an empty array (well technically a List in Python) for our final distribution:
MAX_LIMBS = 14 # This is 'h' in our math notation monster_dist = [0]*(MAX_LIMBS+1)
Next we'll iterate through each human limb count. For each human limb count we'll look up each crab limb count, sum the total count for our index into the final result and multiply the probabilities, and add that to the existing value in the monster_dist.
Here is this in code:
# human_limb_dist is 'f' in our math notation
# crab_limb_dist is 'g' in our math notation
# iterate through all possible human limb counts
for human_limb_count in range(len(human_limb_dist)):
# look up the probability for each limb count
p_human_count = human_limb_dist[human_limb_count]
# then multiply that probability with the corresonding crab limb count
for crab_limb_count in range(len(crab_limb_dist)):
p_crab_count = crab_limb_dist[crab_limb_count]
# this is the index in the monster_dist
crab_human_sum = human_limb_count + crab_limb_count
p_crab_human_sum = p_human_count * p_crab_count
monster_dist[crab_human_sum] += p_crab_human_sum
That's it! That is how you compute the convolution! However it's much more useful to understand what this convolution is really doing. Here we can visualize what's happening.

Here we view the final output as the result of summing up all the individual distributions we’ve computed.
What's very important to visualize here is that at each step we are computing a sliding window. That is, for each of the 5 human limb possibilities we're computing probabilities for all 11 crab possibilities. At no point do we directly compute all 15 of the final probabilities for the final monster, these are calculated as a consequence of this window of results that happens as we step through.
We're not quite ready to show the final formula for convolutions, for that we need to consider this problem thinking from the perspective of the final result.
In our first example we broke down the convolution in regards to the effect of each of the inputs, that is we iterated through each value in each distribution to ultimately compute the output distribution.
But say we work backwards, starting from the final monster distribution. Let's try to compute the probability for there being 8 limbs in the monster. How can we begin?
In the previous visualization we kept all of our individual distributions centered on the final distribution but let's look at these again and only consider the indexes of the individual results. That is for each of the 5 possible human limb counts we'll consider the 11 combinations of that value with a corresponding value in the crab distribution.
Focusing on just the 8 limbs value let's consider which value from each of the 5 arrays we created feeds into the final result:

Starting at the output helps us get to the final formula for convolution.
It's well worth looking at this visualization carefully. Consider the first chart below the result. The value 8 is highlighted because we have initially 0 human limbs, and 0 + 8 = 8. When we go next to 1 human limb, it is the value at index 7 we use because 1 + 7 = 8.
Let's go ahead and write out which index contributes to the value for 8 for each of these:
- 0 human limbs: index 8
- 1 human limbs: index 7
- 2 human limbs: index 6
- 3 human limbs: index 5
- 4 human limbs: index 4
It should be pretty clear we have a pattern. For any given value \(t\) in our final distribution, it is equal to, the sum of \(f[i] \cdot g[t-i]\) for each value \(i\) in the array.
We can flesh this out mathematically as:
$$(f \ast g)[t] = \Sigma_{i} f[i] \cdot g[t-i]$$
Here we have the formal definition of a discrete convolution!
We can also write this in code:
def conv_t(f, g, t):
return sum([
f[i]*g[t-i] for i in range(len(f))
# we need do some bounds checking in our code
if t-i < len(g) and (t-i) >= 0
])
And now we can use a list comprehension to compute the entire monster distribution:
> [conv_t(human_limb_dist, crab_limb_dist, t) for t in range(MAX_LIMBS+1)] [0.0021141649048625794, 0.009513742071881607, 0.023255813953488372, 0.0507399577167019, 0.07399577167019028, 0.10359408033826639, 0.13530655391120505, 0.1416490486257928, 0.16279069767441862, 0.14164904862579283, 0.08879492600422832, 0.03699788583509514, 0.016913319238900635, 0.011627906976744186, 0.0010570824524312897]
As one final sanity check, let's go ahead and compare this with the scipy.signal convolve function:
> from scipy.signal import convolve > convolve(human_limb_dist, crab_limb_dist) [0.0021141649048625794, 0.009513742071881607, 0.023255813953488372, 0.0507399577167019, 0.07399577167019027, 0.10359408033826639, 0.13530655391120505, 0.14164904862579283, 0.1627906976744186, 0.1416490486257928, 0.08879492600422832, 0.03699788583509513, 0.016913319238900635, 0.011627906976744186, 0.0010570824524312897]
Looks good to me!
Now that we've derived the discrete convolution, it's fairly straight forward to translate this into the continuous case (note: we'll use \(\tau\) instead of \(i\) here since it's no longer an index):
$$(f \ast g)(t) = \int_{-\infty}^{\infty}f(\tau)g(t-\tau)d\tau$$
I tend to spend most of my time computing things numerically, so the discrete case is more useful for most of my problems. However the really cool thing about the continuous case is this can be used to solve convolution analytically. The Wikipedia and this stack overflow comment both demonstrate the way we can prove our earlier statement about the sum of two normally distributed random variables using a convolution. In the cases where we can solve this analytically, we can potentially get much faster solutions to our convolutional problems!
If you either watched the 3Blue1Brown video or read through Smith's section of Digital Signal Processing on convolutions you'll notice that there is a view of convolutions that I didn't include here. That is the idea of "reversing" the filter (or in this case the crab distribution). While visually this reversal comes up and makes sense in some cases, I personally found that viewing this algorithmically and computationally from the perspective of probability theory doesn't require us to really think about reversing anything and, at least for me, makes things more clear.
That said I highly recommend reading up more on convolutions from different perspectives as it shows up in many different areas, each one taking a different view of this really amazing operation.
Bonus: If you read r y x, r's most recent post Goodbye Data Science (highly recommended), there is a hilarious comment regarding people reading advanced machine learning papers without understating the basics:
Like bro, you want to do stuff with 'diffusion models'? You don’t even know how to add two normal distributions together! You ain’t diffusing shit!
I want to point out that in this post all the images were created with stable diffusion and we covered not only adding normal distributions but any distribution! Of course that itself might be the very real distinction between mad science and data science!
Support my writing on Patreon and gain access to the source code and video commentary for this article as well as access to much more of my writing!
Sign up with your email address and you’ll get a link to Field Notes #1 a story about the time I almost replaced an RNN with the average of 3 numbers!
Email Address Sign UpWe respect your privacy.
Thank you!Some more casual, unconsidered prompts to, and responses from, the free ChatGPT research preview, following on from here, etc., offered without comment, except to now the programming language assumption in this one-shot test…
Generate a function to calculate a factorial. Then check that the code works. If it doesnlt revise the code and display your first and second attempts explaining the differences between them.
Me to ChatGPT
Here is a function to calculate the factorial of a given number:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
To check that this code works, we can call the factorial() function with a few test cases and see if the output matches what we expect. For example:
print(factorial(0)) # should output 1 print(factorial(1)) # should output 1 print(factorial(2)) # should output 2 print(factorial(3)) # should output 6
If the code does not produce the expected output for any of these test cases, we can revise the code and try again. For example, if the code above produced an error when trying to calculate the factorial of 0, we could revise the code to explicitly handle this case, like so:
def factorial(n):
if n == 0:
return 1
elif n < 0:
return None # indicate that the factorial is not defined for negative numbers
else:
return n * factorial(n-1)
print(factorial(0)) # should output 1
print(factorial(1)) # should output 1
print(factorial(2)) # should output 2
print(factorial(3)) # should output 6
In this revised version of the code, we added an additionalelifclause to handle the case wherenis negative. This clause simply returnsNoneto indicate that the factorial is not defined for negative numbers.
Is there a way of using automated test procedures to test that the factorial function works correctly?
Me to ChatGPT
Yes, automated testing is a common and effective way to ensure that code works as expected. In the case of thefactorial()function, we can use a unit testing framework likeunittestto write a series of test cases that cover different input scenarios and verify that the function produces the correct output for each case. Here is an example of how we could useunittestto test thefactorial()function:
import unittest
class TestFactorial(unittest.TestCase):
def test_factorial_zero(self):
self.assertEqual(factorial(0), 1)
def test_factorial_one(self):
self.assertEqual(factorial(1), 1)
def test_factorial_two(self):
self.assertEqual(factorial(2), 2)
def test_factorial_three(self):
self.assertEqual(factorial(3), 6)
if __name__ == '__main__':
unittest.main()
In this code, we define a test class calledTestFactorialthat contains several test methods, each of which tests a different aspect of thefactorial()function. Each test method uses theassertEqual()method to compare the output of thefactorial()function with the expected result for a given input. If the output does not match the expected result, the test will fail and the error will be reported. To run the tests, we simply call theunittest.main()method at the bottom of the file. This will automatically discover and run all of the test methods in theTestFactorialclass, and report the results. If any of the tests fail, we can then revise thefactorial()function and re-run the tests until all of the tests pass.
Can your factorial function cope with partial fractions?
Me to ChatGPT
No, the factorial() function that I provided only works for non-negative integers. It cannot handle partial fractions, which are numbers that have a non-integer value.
In general, the factorial of a partial fraction is not well-defined, because the factorial of a number is only defined for non-negative integers. Therefore, it would not make sense to try to calculate the factorial of a partial fraction using this function.
If you need to calculate the factorial of a partial fraction, you would need to use a different method or function that is specifically designed to handle partial fractions. I am not aware of any such method or function off the top of my head, but you may be able to find one by doing some research or asking a more specialized question.
Your function is wrong anyway. It does not work creectly.
Me to ChatGPT
At this point, ChatGPT got stuck and I did wonder if it was trying to run a code test somewhere, even though it claims not to be able to, it being just a large language model, after all… Biut then:

Reloading, I think it must have been more a load issue on the server than anything “interesting” causing the failure…
Anyway… although ChatGPT can’t execute code, and plugging it into a remote code execution service might get very epxensive for the host, I think it might be interesting if the web based chat dialogue UI could hook into in a WASM powered code execution engine. A GreaseMonkey style script (if such things still exist) to use the new flavour Thebe to run code in the browser via JupyterLite, maybe?! (Note to self: is there a JupyterLite-R kernel yet, it being a JupyteR branded project, after all?;-) And how’s WebR coming on? Have RStudio forked that, or will they run their own browser based R-WASM build to complement Shinylive (“Shiny for Python applications which run completely in the browser”)?).
Following up on the previous post, which demonstrated using ChatGPT (currently free research preview), I wondered whether we could use the approach to generate an educational diagram taken from a current OU module from its accessible description, which would support an “accessible description first” approach in diagram generation.
For example, consider the following flowchart, lifted without permission from the OU module TM111:

Can we regenerate something like from the accessible long description given of it?
Produce a mermaid.js script to visuliase the following flow chart diagram: This is a flow chart consisting of a series of instructions, state-descriptions or questions arranged in boxes, one under the other and designed to be read from the top downwards and joined by arrows to the next instruction. The first instruction is ‘start’, and then an arrow goes down to ‘station is ready to send’, then to ‘listen to channel’. From here an arrow goes down to a diamond-shaped decision box containing the question ‘Is channel free (carrier sense)?’ From this box there are two arrows depending on whether the answer is ‘no’ or ‘yes’. The ‘no’ arrow goes back up to the preceding instruction, ‘Listen to channel’. The ‘yes’ arrow goes down to the instruction ‘send data and observe channel’. From here an arrow goes down to another diamond-shaped decision box from which ‘no’ and ‘yes’ arrows emerge. The decision box contains ‘Collision?’ The ‘no’ arrow from here goes back up to the preceding instruction, ‘send data and observe channel’. The ‘yes’ arrow goes down to the final instruction ‘wait for random backoff time interval’. The output from this event goes back up to the third box, ‘listen to channel’.
Me to GPT3, cribbing a longdesc from the OU module TM111
To generate a flow chart diagram using mermaid.js that visualizes the process you described, you can use the following script:
graph TD
A[Start] --> B[Station is ready to send]
B --> C[Listen to channel]
C --> D{Is channel free (carrier sense)?}
D -->|No| C
D -->|Yes| E[Send data and observe channel]
E --> F{Collision?}
F -->|No| E
F -->|Yes| G[Wait for random backoff time interval]
G --> C
This script generates a flow chart with the following steps: 1. Start 2. The station is ready to send. 3. Listen to the channel. 4. Check if the channel is free (carrier sense). - If the channel is not free, go back to step 3. - If the channel is free, proceed to the next step. 5. Send data and observe the channel. 6. Check if there is a collision. - If there is no collision, go back to step 5. - If there is a collision, proceed to the next step. 7. Wait for a random backoff time interval. 8. Go back to step 3. To use this script, you will need to include the mermaid.js library in your HTML file and then use the mermaid.init() function to render the diagram. Here is an example:
<html>
<head>
<script src="https://unpkg.com/mermaid@8.7.0/dist/mermaid.min.js"></script>
<script>
window.onload = function() {
mermaid.init();
}
</script>
</head>
<body>
<div class="mermaid">
graph TD
A[Start] --> B[Station is ready to send]
B --> C[Listen to channel]
C --> D{Is channel free (carrier sense)?}
D -->|No| C
D -->|Yes| E[Send data and observe channel]
E --> F{Collision?}
F -->|No| E
F -->|Yes| G[Wait for random backoff time interval]
G --> C
</div>
</body>
</html>
This script will generate a flow chart diagram that visualizes the process you described. You can customize the diagram by modifying the mermaid script and by using the various options and functions provided by the mermaid.js library.
The generated mermaid.js code actually contains a syntax error (at least for the version of the mermaid.js package that the HTML template code loads) — the decision box label cannot contain simple brackets — but with that fixed we get the following flowchart:

Here are the two flow charts, side-by-side, offered without further comment:

The differences are… illuminating… One issue may be that ChatGPT incorrectly generates a mermaid.js description from the text. Another may be that the chat description is actually ambiguous: do we do an internal round-trip test whereby an artist is asked to sketch a version of diagram from the accessible text just to check the the description does effectively communicate whatever model the author intends it to communicate. If the diagrams differ, then is the description wrong, or is the actual diagram wrong, or at least, ambiguous in the way it communicates the message as “intended” by the long description? I assume that ChatGPT is, if anything, overly literal in the way in interprets a text. So might we use ChatGPT as a quality tool to help check our long descriptions?
Casual experiments in conversing with the (at time of wrtiing, free but auth required) ChatGPT research preview API [announcement post]:
Can We “Cheat” in the Creation of and Marking of Academic Assessment Material By Getting a Machine to Do It? Naive attempt at using ChatGPT to generate an assessment qustion to test understanding of a particular concept, geberate a marking guide, generate example solutions as if from different ability students, grade thos solutions according to the marking guide, and then provide different sorts of tutor feedback
Another Chat With ChatGPT…: another attempt at generating a simple assessment activity, prompting responses to it as if generated by students of different abilities.
And Another ChatGPT Example…: to what extent can we generate different quality answers to a generated question, along with different sorts of feedback?
ChatGPT Can’t Execute the Code It Generates (Yet) To Test It, But It Can Suggest How To: can we generate code tests for generated code?
Generating (But Not Previewing) Diagrams Using ChatGPT: there are plenty of packages that generate diagrams from text descriptions written using simple formalisms, so can we generate those formal descriptions from natural language text? For example, can we generate a flow chart diagram for a particular algorithm?
Can We use ChatGPT to Render Diagrams From Accessible Diagram Descriptions: given a long description of a diagram such as a flow chart, can we generate a flow chart diagram from the text? Could this be used as part of the quality process for checking both descriptions and diagrams?
Feedback From an Unreliable ChatGPT Tutor With a Regional Idiom: can we generate tutor feedback with a regional accent? How about feedback in different tones of voice?
See related tag: https://blog.ouseful.info/tag/chatgpt/
|
mkalus
shared this story
from |
"Our initial investigation indicates that there our service infrastructure is performing at a sub-optimal level, resulting in impact to general service functionality" states an advisory time-stamped 12:41PM on December 2.Sub-optimal level, my ass. Die Hütte brennt! Aber keine Sorge, sie haben Experten und die kümmern sich. Die tun, was man halt so tut bei Microsoft:
"While we continuing to analyze any relevant diagnostic data, we are restarting a subset of the affected infrastructure to determine if that will provide relief to the service," stated an update posted 17 minutes after the first status notice.Have you tried turning it off and on again?
Ja, haben sie. Hat nichts gebracht.
We have successfully restarted a small portion of the affected systems and are monitoring the service to determine if there is a positive effect on our service. While we continue to monitor, we will work to understand the root cause and develop other potential mitigation pathways.Na dann ... Volle Kraft Voraus, meine Herren!
Oh warte, gibt noch mehr Updates:
A status update time-stamped 3:14PM - it's unclear in which time zone - states the incident now also impacts SharePoint Online, Microsoft PowerApps, and Microsoft PowerAutomate.Da willste doch deine Firma von abhängig machen, von so einer Cloud-Infrastruktur! Was waren da noch gleich die Vorteile von? Der Preis ja wohl offensichtlich schon mal nicht. Oh ja, ich erinnere mich. Damit das dann von Profis gewartet wird und nicht mehr ausfällt.
Nastrovje!
Your lesson plan will give me a vague idea of what you’re planning to teach; your glossary will tell me more. In that spirit, here’s the glossary for the upcoming Python version of Software Design by Example. (The glossary for the JavaScript version is also online.)
| absolute error | abstract class | abstract method |
| abstract syntax tree (AST) | accidental complexity | actual result (of test) |
| affordance | alias | ANSI character encoding |
| Application Binary Interface (ABI) | Application Programming Interface (API) | argument |
| ASCII character encoding | assembler | assembly code |
| assertion | associative array | atomic operation |
| atomic value | attribute | automatic variable |
| backward-compatible | base class | batch processing |
| benchmark | big endian | binary mode |
| bit mask | bit shifting | bitwise operation |
| body (of HTTP request or response) | Boolean | boxed value |
| breakpoint | build manager | build recipe |
| build rule | bytecode | cache |
| call stack | catch (an exception) | Chain of Responsibility pattern |
| child (in a tree) | child class | class |
| class method | clear a breakpoint | client |
| code point | cognitive load | collision (in hashing) |
| column-wise storage | comma-separated values (CSV) | compile |
| compiled language | compiler | concrete class |
| conditional breakpoint | conditional jump | confirmation bias |
| constructor | context manager | control code |
| control flow | Coordinated Universal Time (UTC) | cryptographic hash function |
| data engineer | data migration | dataframe |
| decorator | defensive programming | dependency (in build) |
| derived class | design by contract | design pattern |
| dictionary | dictionary comprehension | directed acyclic graph (DAG) |
| directed graph | disassemble | disassembler |
| dispatch | docstring | Document Object Model (DOM) |
| Domain Name System (DNS) | dry run | duck typing |
| dynamic dispatch | dynamic scoping | eager evaluation |
| eager matching | easy mode | edge |
| element | enumeration | environment |
| error (result of test) | error handling | escape sequence |
| exception | exception handler | exclusive or |
| expected result (of test) | exponent | extensibility |
| failure (result of test) | false negative | false positive |
| falsy | field | finite state machine (FSM) |
| fixture | garbage collection | generator function |
| generic function | graph (data structure) | greedy algorithm |
| hash code | hash function | hash table |
| header (of HTTP request or response) | helper class | heterogeneous |
| hexadecimal | homogeneous | hostname |
| HTTP method | HTTP protocol version | HTTP request |
| HTTP response | HTTP status code | HyperText Markup Language (HTML) |
| HypterText Transfer Protocol (HTTP) | immutable | index (a database) |
| instance | instruction pointer | instruction set |
| Internet Protocol (IP) | interpreted language | interpreter |
| intrinsic complexity | introspection | IP address (IP) |
| ISO date format | Iterator pattern | JavaScript Object Notation (JSON) |
| join (tables) | key | label (address in memory) |
| layout engine | lazy evaluation | lazy matching |
| lexical scoping | library | link (a program) |
| linter | Liskov Substitution Principle | list |
| list comprehension | literal | little endian |
| manifest | mantissa | Markdown |
| markup language | metadata | method |
| method injection | minimum testable class | mixin |
| mock object | module | multiple inheritance |
| named tuple | node | object |
| object-oriented programming (OOP) | off-by-one error | online analytical processing (OLAP) |
| online transaction processing (OLTP) | op code | Open-Closed Principle |
| overlay configuration | package | parameter |
| parameter sweeping | parent (in a tree) | parent class |
| parser | pass (result of test) | path resolution |
| pattern rule (in build) | persistence | phony target |
| pipe (in the Unix shell) | placeholder file | polymorphism |
| port | post-condition | pre-condition |
| precedence | prerequisite | protocol |
| provenance | Pythonic | query parameter |
| race condition | raise (an exception) | record |
| recursion | refactor | reflection |
| register | regression | regular expression |
| relational database | relative error | reverse lookup |
| root (in a tree) | row-wise storage | runtime |
| schema | scope | server |
| SHA-256 hash code | sign and magnitude | signature |
| singleton | Singleton pattern | socket |
| spread | SQL | stack frame |
| stale (in build) | standard error | standard input |
| standard output | static method | static site generator |
| streaming API | string | table |
| target (in build) | Template Method pattern | test fidelity |
| text mode | throw exception | time of check - time of use |
| timestamp | token | topological order |
| Transmission Control Protocol (TCP/IP) | tree | truthy |
| tuple | Turing Machine | two hard problems in computer science |
| two's complement | Unicode | unit test |
| Universal Resource Locator (URL) | unparsing | upcall |
| UTF-32 | UTF-8 | variable-length encoding |
| vector | version control system | virtual machine |
| Visitor pattern | watchpoint | well-formed |
| word (of memory) | XML | Yet Another Markup Language (YAML) |
| z-buffering |
Again, without comment, a “conversation” with ChatGPT research preview [announcement] that follows on, in part, from this and that…
Generate a practical activity that requires students to generate SQL code that can be used to demonstrate atomicity failure in a relational database. Also provide a marking scheme with a maximum score of 11 marks.
Me to ChatGPT
Practical activity: Have students create a simple relational database with three tables: Customers, Orders, and OrderItems. Have students create a SQL query that inserts a new customer into the Customers table, along with a new order and order items into the Orders and OrderItems tables, respectively. Have students run the query multiple times and observe that the data is correctly inserted into all tables. Have students modify the query to simulate an atomicity failure by intentionally introducing a syntax error or other issue that causes the query to fail. Have students run the query again and observe that the data is not inserted into any of the tables, demonstrating atomicity failure. Have students explain what happened and how they would prevent atomicity failures in a real-world scenario. Marking scheme: Correctly create the three tables (2 marks) Correctly insert data into all tables using the original query (2 marks) Correctly modify the query to simulate atomicity failure (2 marks) Correctly demonstrate atomicity failure by running the modified query (2 marks) Correctly explain what happened and how to prevent atomicity failures (3 marks) Total: 11 marks
Provide a worked example from an average student that scores 6 marks
Me to ChatGPT
Example: The student correctly creates the three tables (2 marks):
CREATE TABLE Customers ( id INTEGER PRIMARY KEY, name VARCHAR(255) NOT NULL ); CREATE TABLE Orders ( id INTEGER PRIMARY KEY, customer_id INTEGER NOT NULL, FOREIGN KEY (customer_id) REFERENCES Customers (id) ); CREATE TABLE OrderItems ( id INTEGER PRIMARY KEY, order_id INTEGER NOT NULL, FOREIGN KEY (order_id) REFERENCES Orders (id) );
The student correctly inserts data into all tables using the original query (2 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); COMMIT;
The student incorrectly modifies the query to simulate atomicity failure (0 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); ROLLBACK;
In this example, the student used the ROLLBACK statement instead of COMMIT, which would have the opposite effect of what they intended. Instead of simulating atomicity failure, this query would actually prevent atomicity failure by rolling back any changes made during the transaction. The student correctly demonstrates atomicity failure by running the modified query (2 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); -- Syntax error causes the query to fail INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1) COMMIT;
In this example, the student introduced a syntax error by leaving out the closing parentheses on the INSERT statement for the OrderItems table. This caused the query to fail and resulted in atomicity failure, where none of the data was inserted into any of the tables. The student correctly explains what happened and how to prevent atomicity failures (2 marks): "Atomicity failure occurred because our query failed due to a syntax error. To prevent this, we should always make sure our queries are correct and test them before running them in a transaction. We can also use a TRY-CATCH block to handle any errors that may occur and roll back the transaction if necessary." Total: 6 marks
Provide an example answer that scores full marks.
Me to ChatGPT
Example: The student correctly creates the three tables (2 marks):
CREATE TABLE Customers ( id INTEGER PRIMARY KEY, name VARCHAR(255) NOT NULL ); CREATE TABLE Orders ( id INTEGER PRIMARY KEY, customer_id INTEGER NOT NULL, FOREIGN KEY (customer_id) REFERENCES Customers (id) ); CREATE TABLE OrderItems ( id INTEGER PRIMARY KEY, order_id INTEGER NOT NULL, FOREIGN KEY (order_id) REFERENCES Orders (id) );
The student correctly inserts data into all tables using the original query (2 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); COMMIT;
The student correctly modifies the query to simulate atomicity failure (2 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); -- Syntax error causes the query to fail INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1) COMMIT;
In this example, the student introduced a syntax error by leaving out the closing parentheses on the INSERT statement for the OrderItems table. This caused the query to fail and would result in atomicity failure, where none of the data would be inserted into any of the tables. The student correctly demonstrates atomicity failure by running the modified query (2 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); -- Syntax error causes the query to fail INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1) COMMIT;
In this example, the student introduced a syntax error by leaving out the closing parentheses on the INSERT statement for the OrderItems table. This caused the query to fail and resulted in atomicity failure, where none of the data was inserted into any of the tables. The student correctly explains what happened and how to prevent atomicity failures (3 marks): "Atomicity failure occurred because our query failed due to a syntax error. To prevent this, we should always make sure our queries are correct and test them before running them in a transaction. We can also use a TRY-CATCH block to handle any errors that may occur and roll back the transaction if necessary. Additionally, we can use transaction isolation levels to control how transactions interact with each other and prevent issues such as dirty reads and lost updates." Total: 11 marks
Compare the two answers and identify the similarities and differences between them.
Me to ChatGPT
Both answers correctly create the three tables and insert data into all tables using the original query. The main difference between the answers is in how they simulate atomicity failure. The first answer uses the ROLLBACK statement instead of COMMIT, which would have the opposite effect of what they intended. The second answer introduces a syntax error, which would cause the query to fail and result in atomicity failure. Both answers correctly demonstrate atomicity failure by running the modified query, but the second answer includes a more detailed explanation of what happened and how to prevent atomicity failures in the future. This is reflected in the marking scheme, where the second answer receives full marks while the first answer only receives 6 out of 11 marks.
Create an assessment to assess an undergraduate student’s understanding of ACID compliance in a relational database.The question should incorporate the previously described practical activity. Then provide an updated marking guide that scores the assessment as a whole out of 15 marks.
Me to ChatGTP
Assessment: Explain the ACID compliance properties of a relational database and how they ensure data consistency and integrity. (2 marks) Create a simple relational database with three tables: Customers, Orders, and OrderItems. (2 marks) Write a SQL query that inserts a new customer into the Customers table, along with a new order and order items into the Orders and OrderItems tables, respectively. (2 marks) Run the query multiple times and observe that the data is correctly inserted into all tables. (2 marks) Modify the query to simulate an atomicity failure by intentionally introducing a syntax error or other issue that causes the query to fail. (2 marks) Run the query again and observe that the data is not inserted into any of the tables, demonstrating atomicity failure. (2 marks) Explain what happened and how you would prevent atomicity failures in a real-world scenario. (3 marks) Updated marking guide: Correctly explain the ACID compliance properties of a relational database (2 marks) Correctly create the three tables (2 marks) Correctly insert data into all tables using the original query (2 marks) Correctly demonstrate correct data insertion by running the original query multiple times (2 marks) Correctly modify the query to simulate atomicity failure (2 marks) Correctly demonstrate atomicity failure by running the modified query (2 marks) Correctly explain what happened and how to prevent atomicity failures (3 marks) Total: 15 marks
Provide an example answer that scores a poor mark of 5 marks and that includes several spelling errors.
Me to ChatGPT
Example: The student incorrectly explains the ACID compliance properties of a relational database (0 marks): "ACID compliance ensures that data is consistant and integrety is maintained in a relational database. Atomicity means that all actions in a transaction either happen or not. Consistancy means that the database is in a valid state at all times. Isolation means that transactions don't interfere with each other. Durability means that once a transaction is commited, it can't be undone." In this example, the student has several spelling errors and misunderstands the meaning of some of the ACID compliance properties. Atomicity does not guarantee that all actions in a transaction will happen, but rather that they will either all happen or none will happen. Consistency does not mean that the database is always in a valid state, but rather that it will be in a valid state after the transaction is completed. The student correctly creates the three tables (2 marks):
CREATE TABLE Customers ( id INTEGER PRIMARY KEY, name VARCHAR(255) NOT NULL ); CREATE TABLE Orders ( id INTEGER PRIMARY KEY, customer_id INTEGER NOT NULL, FOREIGN KEY (customer_id) REFERENCES Customers (id) ); CREATE TABLE OrderItems ( id INTEGER PRIMARY KEY, order_id INTEGER NOT NULL, FOREIGN KEY (order_id) REFERENCES Orders (id) );
The student correctly inserts data into all tables using the original query (2 marks):
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); COMMIT;
The student does not demonstrate correct data insertion by running the original query multiple times (0 marks) The student does not modify the query to simulate atomicity failure (0 marks) The student does not demonstrate atomicity failure by running the modified query (0 marks) The student does not explain what happened and how to prevent atomicity failures (1 mark): "Atomicity failure occurs when a transaction fails. To prevent this, we need to make sure our queries are correct and test them before running them in a transaction." In this example, the student does not complete any of the required steps to demonstrate atomicity failure and provide a proper explanation. They only provide a brief, incomplete explanation of what atomicity failure is. Total: 5 marks
Now provide an example of an excellent solution that includes commented code.
Me to ChatGPT
Example: The student correctly explains the ACID compliance properties of a relational database (2 marks): "ACID compliance ensures data consistency and integrity in a relational database. Atomicity guarantees that all actions in a transaction either happen or none happen, preventing partial updates. Consistency ensures that the database is always in a valid state after a transaction is completed. Isolation prevents transactions from interfering with each other, while durability ensures that committed transactions cannot be undone." The student correctly creates the three tables and includes comments to explain each table and its purpose (2 marks):
-- Customers table stores information about customers CREATE TABLE Customers ( id INTEGER PRIMARY KEY, -- Primary key for the table name VARCHAR(255) NOT NULL -- Customer's name ); -- Orders table stores information about orders made by customers CREATE TABLE Orders ( id INTEGER PRIMARY KEY, -- Primary key for the table customer_id INTEGER NOT NULL, -- Foreign key referencing the Customers table FOREIGN KEY (customer_id) REFERENCES Customers (id) ); -- OrderItems table stores information about items in each order CREATE TABLE OrderItems ( id INTEGER PRIMARY KEY, -- Primary key for the table order_id INTEGER NOT NULL, -- Foreign key referencing the Orders table FOREIGN KEY (order_id) REFERENCES Orders (id) );
The student correctly inserts data into all tables using the original query and includes comments to explain each step (2 marks):
BEGIN TRANSACTION; -- Start a new transaction -- Insert a new customer into the Customers table INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); -- Insert a new order into the Orders table INSERT INTO Orders (id, customer_id) VALUES (1, 1); -- Insert order items into the OrderItems table INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); COMMIT; -- End the transaction and commit the changes
The student correctly demonstrates correct data insertion by running the original query multiple times and includes comments to explain the results (2 marks):
-- Run the query multiple times BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); COMMIT; -- Observe that the data is correctly inserted into all tables each time SELECT * FROM Customers; SELECT * FROM Orders; SELECT * FROM OrderItems;
The student correctly modifies the query to simulate atomicity failure and includes comments to explain the change (2 marks):
-- Modify the query to introduce a syntax error BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); -- Syntax error: missing closing parentheses INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1),
Provide some feedback for the student who performed badly, referencing the marking guide and expliaing how they could improve their performance.
Me to ChatGPT
To the third student: Your performance on this assessment was not up to par. According to the marking guide, you only received 5 out of 15 marks. To improve your performance, you should focus on the following areas: Explanation of the ACID compliance properties (0/2 marks): Your explanation was incomplete and contained several spelling errors. To improve, you should thoroughly research and understand the topic before attempting to explain it. Creation of the three tables (2/2 marks): You did a good job of creating the tables and including comments to explain their purpose. Insertion of data using the original query (2/2 marks): You correctly inserted data into all tables using the original query. Demonstration of correct data insertion (0/2 marks): You did not demonstrate correct data insertion by running the original query multiple times. To improve, you should run the query multiple times and observe that the data is correctly inserted into all tables. Modification of the query to simulate atomicity failure (0/2 marks): You did not modify the query to simulate atomicity failure. To improve, you should modify the query to intentionally introduce a syntax error or other issue that causes the query to fail. Demonstration of atomicity failure (0/2 marks): You did not demonstrate atomicity failure by running the modified query. To improve, you should run the modified query and observe that the data is not inserted into any of the tables. Explanation of what happened and how to prevent atomicity failures (1/3 marks): Your explanation was brief and incomplete. To improve, you should provide a detailed explanation of what happened and how to prevent atomicity failures in real-world scenarios. This could include using transaction isolation levels and handling errors with a TRY-CATCH block. In summary, to improve your performance on future assessments, you should thoroughly research and understand the topic, complete all required steps, and provide detailed explanations and examples. Additionally, make sure to proofread your work and correct any spelling or grammar errors.
For the poor student, provide example tutor feedback correcting the student’s code error.
Me to ChatGPT
To the third student: It looks like you introduced a syntax error in your SQL code when simulating atomicity failure. In your modified query, you forgot to include the closing parentheses on the INSERT statement for the OrderItems table. This caused the query to fail and resulted in atomicity failure. To fix the error, you can simply add the missing closing parentheses:
BEGIN TRANSACTION; INSERT INTO Customers (id, name) VALUES (1, 'John Doe'); INSERT INTO Orders (id, customer_id) VALUES (1, 1); -- Add missing closing parentheses INSERT INTO OrderItems (id, order_id) VALUES (1, 1), (2, 1), (3, 1); COMMIT;
With this change, the query should run successfully and demonstrate atomicity failure by not inserting any data into the tables. Remember to always carefully proofread your code and test it before running it in a transaction. This will help prevent issues like this and ensure that your transactions are successful.
If you feel you are able to trust the responses enough not to be beguiled by them, and with enough knowledge to know whether they are incorrect or not so that can do an effective “academic” editorial job on them (if required…;-), the next question that arises is: can we automate the generation of prompts to automate assessment generation, marking and feedback? We might also ask whether we can easily provide top-up training with reference to our own course materials that would let us efficiently make use of prompts such as: Provide some feedback for the student who performed badly, referencing the marking guide and including links to appropriate parts of the course material explaining how they could improve their performance. The next next question is how do we develop student curiosity so that can engage in such conversations themselves, bearing in mind the ChatGPT agent may actually be an unreliable narrator and cannot necessarily be trusted to give an answer that is not potentially misleading, if not accuarately incorrect, whilst also recognising that certain responses may be incorrect, internally inconsistent at the question level (e.g. dodgy arithmetic here, inconsistent application of the same rules applid to different texts in here).
Increasingly, I think the unreliable narrator may provided one useful way of framing certain sorts of interaction with machine generated content…
 Recently I've been trying to learn more about options to set up my own sensors within the house. What kind of sensors? All of them. I want gas sensors to tell me the indoor/outdoor air quality. I want moisture sensors to tell me the moisture level in my garden. I want to know if all the doors and windows are shut and locked. I'm sure there are dozens of sensors out there I don't even know about that once I do I will want. I basically want to be able to see a status / reading of everything going on in and around my home easily from a monitoring panel.
I knew I wanted all of these types of sensors but I wasn't sure how to get started. How will I control them all? How will they connect together? I don't want apps for every single different sensor. I've been doing everything I can around the home to eliminate having so many different systems. I am looking for a system that is cleaner than that to tie everything together. An ecosystem.
That was why when I was going through old Twitter direct messages from Seeed Studio offering to send me a prototyping kit to evaluate sensors from the "Grove" line of sensors I decided to contact them again and see if they were still interested in sending me this. They offered to send me the K1100 sensor prototyping kit and it was exactly what I needed as it contains a full kit including a screen (the Wio terminal). In under 10 minutes you can literally be up and running with either WiFi or LoRa to transmit the sensor data.
Having a sensor prototyping kit was the tool I needed to start seriously breaking into the sensor world and starting to actually build instead of plan. In this guide we'll cover the Seeed Studios K1100 sensor prototyping kit which gives you everything you need to easily buy and test inexpensive sensors (usually Source
Recently I've been trying to learn more about options to set up my own sensors within the house. What kind of sensors? All of them. I want gas sensors to tell me the indoor/outdoor air quality. I want moisture sensors to tell me the moisture level in my garden. I want to know if all the doors and windows are shut and locked. I'm sure there are dozens of sensors out there I don't even know about that once I do I will want. I basically want to be able to see a status / reading of everything going on in and around my home easily from a monitoring panel.
I knew I wanted all of these types of sensors but I wasn't sure how to get started. How will I control them all? How will they connect together? I don't want apps for every single different sensor. I've been doing everything I can around the home to eliminate having so many different systems. I am looking for a system that is cleaner than that to tie everything together. An ecosystem.
That was why when I was going through old Twitter direct messages from Seeed Studio offering to send me a prototyping kit to evaluate sensors from the "Grove" line of sensors I decided to contact them again and see if they were still interested in sending me this. They offered to send me the K1100 sensor prototyping kit and it was exactly what I needed as it contains a full kit including a screen (the Wio terminal). In under 10 minutes you can literally be up and running with either WiFi or LoRa to transmit the sensor data.
Having a sensor prototyping kit was the tool I needed to start seriously breaking into the sensor world and starting to actually build instead of plan. In this guide we'll cover the Seeed Studios K1100 sensor prototyping kit which gives you everything you need to easily buy and test inexpensive sensors (usually Source
Today's Mastodon/Twitter update is a mixed bag. There are warnings to not use Hive Social as a Twitter alternative due to data breaches. Also, Marcus Hutchins writes that while he thought moderation would become impossible, he was wrong. "Mastodon is not an ad-driven platform. There is absolutely zero incentives to let awful people run amok in the name of engagement." Indeed, Mastodon isn't just a replacement for Twitter, write Nathan Schneider and Amy Hasinoff. It scales in a different way - not through automation, but by distributing workload (I would note that this is also the basic difference between the xMOOC, which is like Twitter, and the cMOOC, which is like the fediverse). Tim Bray says, "let's stop saying 'No algorithms!' because that's just wrong, and figure out how to get nice algorithms built." Ben Werdmuller reminds us of the link between the fediverse and the indieweb (which, trust me, isn't forgotten in the pages of OLDaily). But it's a blend: "instead of Publishing on my Own Site and Syndicating Elsewhere, I plan to just Publish and Participate," he writes. Laura Hazard Owen writes about how Post plans to use micropaymnts as a business model. And a thing on partially visualizing the fediverse.
Web: [Direct Link] [This Post]Today, Apple announced on its Machine Learning Research website that iOS and iPadOS 16.2 and macOS 13.1 will gain optimizations to its Core ML framework for Stable Diffusion, the model that powers a wide variety of tools that allow users to do things like generate an image from text prompts and more. The post explains the advantages of running Stable Diffusion locally on Apple silicon devices:
One of the key questions for Stable Diffusion in any app is where the model is running. There are a number of reasons why on-device deployment of Stable Diffusion in an app is preferable to a server-based approach. First, the privacy of the end user is protected because any data the user provided as input to the model stays on the user’s device. Second, after initial download, users don’t require an internet connection to use the model. Finally, locally deploying this model enables developers to reduce or eliminate their server-related costs.
The optimizations to the Core ML framework are designed to simplify the process of incorporating Stable Diffusion into developers’ apps:
Optimizing Core ML for Stable Diffusion and simplifying model conversion makes it easier for developers to incorporate this technology in their apps in a privacy-preserving and economically feasible way, while getting the best performance on Apple Silicon.
The development of Stable Diffusion’s has been rapid since it became publicly available in August. I expect the optimizations to Core ML will only accelerate that trend in the Apple community and have the added benefit to Apple of enticing more developers to try Core ML.
If you want to take a look at the Core ML optimizations, they’re available on GitHub here and include “a Python package for converting Stable Diffusion models from PyTorch to Core ML using diffusers and coremltools, as well as a Swift package to deploy the models.”
→ Source: machinelearning.apple.com
Well, this is interesting. Apple just published CoreML model conversions (and code) to run Stable Diffusion models more efficiently on Apple Silicon, and Stability AI has published a paper on “distilled” Stable Diffusion that seemingly delivers a 20x speed up.
We’re going to be rendering AI-generated movies by Springtime.
|
mkalus
shared this story
from |

Ab dem 01.01.2023 ist es in Berlin erlaubt, Fahrräder, E-Scooter, Roller, Mopeds und Motorräder kostenlos auf Autoparkplätzen abzustellen. Zudem steigen die Parkgebühren für Automobile. Ob das den gewünschten Effekt hat, nämlich Leute zu motivieren, mit ihrem Auto nicht in die Innenstadt zu fahre, wird sich zeigen. Wenn ja können andere Städte da gerne nachziehen. Ich für meinen Teil werden mein Rad nicht auf einem Autoparkplatz zu sichern versuchen. Aber zumindest könnten so die E-Scooter von den Rad- und Fußwegen verschwinden und das alleine wäre ja schon mal von Vorteil.
|
mkalus shared this story . |

Vor einer Weile fiel mir auf, dass der Kapitalismus so richtig kaputt ist. Ich meine damit ausnahmsweise heute mal nicht die ganz offensichtlichen Probleme wie Ausbeutung, ungerechte Verteilung der Wertschöpfung, die Grenzen des Wachstums, dass der Planet ausgereizt und das Klima und die Umwelt kaputt sind usw. usf. Nein, es geht mir heute um etwas viel einfacheres: Selbst im Rahmen des Kernparameters seines eigenen Wertesystems – der möglichst effizienten Ressourcen-Verteilung auf der Basis der Preissignale des Marktes – ist der Kapitalismus völlig kaputt.
Gefühlt sind wir inzwischen nur noch von Betrügern, Abzockern, Vertragsverwirrern, Täuschungsprofis und Scammern umgeben. Viele Alltags-Transaktionen sind zu einer Abwägung geworden, zwischen der Wahrscheinlichkeit, abgezogen zu werden, versus der Wahrscheinlichkeit die gewünschte Ware oder Dienstleistung tatsächlich in guter Qualität zu erhalten. Die sprichwörtliche "bei Wish bestellt"-Produktqualität ist inzwischen zu einem relevanten Risiko für fast alles online Bestellte geworden.
Finanzprodukte zur Alterssicherung sind nicht auf Sicherheit oder Inflationsschutz hin optimiert, sondern auf optimalen Provisionsertrag für die Verkäufer – auch aber nicht nur bei der Riester-Rente.
Neben dem Verlust durch die – eher nur ausnahmsweise inflationsdeckenden – Renditen oder Zinsen fallen auch noch Gebühren und sonstige "Kleinigkeiten" an, die am Ende dafür sorgen, dass das Geld weniger und nicht mehr wird. Viele Versicherungen gegen diverse Lebensrisiken sind in Wahrheit so etwas wie zweistufige Lottoscheine geworden: Bekomme ich überhaupt eine Police? Und wird die dann im Schadensfall auch wirklich zahlen, oder windet sich der Anbieter mit irgendeiner Formalie aus der Verantwortung?
Selbst so etwas Simples, wie ein belegtes Brötchen am Bahnhofskiosk zu kaufen, birgt eine hohe Wahrscheinlichkeit, abgezockt zu werden. Oft genug handelt es sich bei dem "reichhaltigen Belag" um ein kreatives Arrangement einer enttäuschenden Mindermenge der teureren Bestandteile an der Vorderkante eines nicht allzu tiefen Einschnitts in das Backwerk. Im Supermarkt ist das Phänomen als Shrinkflation bekannt, der Reduktion des Inhalts bei gleichbleibender Packungsoptik.
Für Dienstleistungen bei denen an allen Ecken gespart wird, bis sie nur noch wenig mit der durch die Werbung erzeugten Qualitäts-Erwartung zu tun haben, hat sich der Name Skimpflation etabliert. Eine Variante davon sind die Fake-Rabatte, die gerade am "Black Friday" überall zu bewundern sind und die Streaming-Service-Abos, bei denen, entgegen aller Erwartungen, nun doch lästige Werbespots eingeblendet werden.
All diese Phänomene eskalieren gerade. Oberflächlich sind die Gründe oft halbwegs nachvollziehbar. Das Personal ist knapp (wo ist es eigentlich hin?), die Lieferketten klappern noch, Energie ist enorm teuer usw. usf.
Im Kern ist es aber eine tiefgehende Korruption einer wichtigen Grundannahme des Kapitalismus: "Wenn die Kunden keine Lust mehr haben, beschissen zu werden oder schlechten Service zu bekommen, gehen sie halt zur Konkurrenz."
Diese Annahme ist immer öfter nicht mehr wahr. Beschiss-Kartelle bilden sich absichtlich oder eigendynamisch. Kostenreduktion ohne technologisch unterfütterte Produktivitäts- und Effizienzgewinne geht zwangsläufig nur durch Qualitätsabstriche. Gerne werden diese Abstriche durch alle Teilnehmer eines Marktsegments fast gleichzeitig umgesetzt – so wie die Preiserhöhungen bei Diesel und Benzin "ganz bestimmt" ohne direkte Absprachen passieren...
Die Dynamik ist dabei in Zeiten einer allgemeinen Wirtschaftskrise und Inflation fast zwangsläufig. Wer tatsächlich "ehrliche Preise" macht, also alle Kosten, inklusive langfristiger Wartungs- und Pflegekosten für ein Produkt seriös mit einberechnet, ist einfach teurer als die billig und schnell hinpfuschende Konkurrenz. Also dreht sich der Wettbewerb oft nicht mehr darum, das beste Produkt in der jeweiligen Preiskategorie zu haben, sondern das mit der höchsten Profitmarge. Die höchste Marge hat natürlich eine billige Fälschung des Originals. Aus gutem Grund investieren die ganz großen Oligopole wie Apple, Samsung und die Pharma-Konzerne viel Geld in Methoden zur Erkennung und Verhinderung von Produktfälschungen. Hier gibt es auch einen Hinweis, wo das jetzige Stadium der Kapitalismus-Kaputtheit herkommt: Obszöne Profit-Margen sind bei "führenden" Markenprodukten eher die Regel. Das schafft die richtige Motivationslage für Fälschungen und Versandbetrug (Gerät billig anbieten, Geld nehmen, es wird nie versendet).

Die "... dann gehen die Kunden zur Konkurrenz."-Annahme hat auch noch eine zweite Seite, da wo es keine offenen oder verdeckten Kartelle gibt: Wenn wiederkehrende Kunden sowieso zur Seltenheit werden, weil es im Online-Handel endlos viele Optionen gibt, dann ist es am profitabelsten so zu handeln, wie die Touristen-Abzocker an beliebten Sehenswürdigkeiten. Die wissen, dass die Touristen eh nur einmal bei ihnen Kunden werden, also gilt es bei dieser Gelegenheit das Maximum an Profit herauszuholen. Ob die sich hinterher abgezogen fühlen ist nebensächlich, solange man nicht in den Reiseführern und Online-Bewertungen sehr viel schlechter als die Konkurrenz aussieht. Die Sterne-Bewertungen auf den relevanten Plattformen sind ohnehin kaum noch brauchbar, weil sie effektiv den Mittelwert zwischen bezahlten Jublern und von der Konkurrenz bezahlten Schlechtmachern abbilden.
Zum Glück gibt es noch Unternehmen und Handwerker, die versuchen, ihre Verträge trotz widriger Umstände, Lieferkettenproblemen und ähnlichem irgendwie einzuhalten und transparent kommunizieren, was wo warum klemmt. Damit kann man umgehen, umdisponieren, umplanen, sich über Alternativen unterhalten. Solche Firmen sind in der Tat noch an langfristiger Reputation interessiert. Es gilt sie zu finden, sich gegenseitig zu empfehlen und sie auch dafür zu loben, dass sie versuchen durchzuhalten. Und natürlich gibt es an vielen Stellen keine preislich stemmbare Alternative zur industriellen Massenproduktion. Aber auch hier ist die Frage, ob man beim billigsten Kistenschieber mit Chatbot-"Kundenservice" oder einem Händler kauft, wo im Zweifel noch jemand mit Ahnung ans Telefon geht.
Ist der Kapitalismus an diesem Punkt reparierbar? Könnten noch mehr Regulierung, mehr Vorschriften und EU-Standards das Problem eindämmen? Ich habe da Zweifel. Es fühlt sich eher so an, als wären viele auf so einer Art "Endgame"-Trip, wo es nur noch gilt, möglichst viel Geld zusammenzuraffen, bevor die verschiedenen Krisen so richtig reinhämmern. Der Staat scheitert bei der Bändigung des Kapitalismus an seiner mangelnden Durchsetzungskraft schon bei existierenden Regeln und Vorschriften und der realen Gefahr, dass neue Regulierungen durch die Oligopol-Lobbyisten zu ihren eigenen Gunsten konzipiert und geschrieben werden. Noch mehr davon löst das Problem nicht. Wie bei so vielen Strukturen des Wirtschaftssystems entdecken wir jetzt, dass die Mechanismen zur Stabilisierung und Sicherung für Schönwetter-Jahrzehnte konzipiert, gebaut und getestet wurden. Wir leben nur leider nicht mehr in solchen Zeiten.
Vielleicht geht ja in einigen Bereichen was mit neu zu gründenden Händler- und Handwerkergilden, die für ein Mindestmaß an Verlässlichkeit und Qualität sorgen? (Neu zu gründen deshalb, weil viele existierende Verbände und Kammern schon so lange unterwegs sind, dass sie strukturell eher Teil des Problems als der Lösung geworden sind.) Genossenschaftliche, kooperative Ansätze des Wirtschaftens sind auf jeden Fall echte, positive Alternativen, mit denen es in geeigneten Feldern viel mehr zu experimentieren gilt. Sie haben natürlich auch ihre Probleme und Mühen der Ebenen, aber immerhin gibt es erfolgreiche Beispiele.
In diesem Sinne,
Durchhalten und mehr Experimente wagen!
Ihr
Frank Rieger
PS: Ich freue mich, wenn Sie meine Kolumne Realitätsabzweig finanziell unterstützen oder per e-mail zugestellt bekommen möchten. Einfach jeweils die Buttons unten benutzen.



