Starting off in a new field, you hear a lot of rules of thumb. Rules for estimating things, thinking about things, and (ideally) simplifying tough decisions. When I started in Radar, I heard:
the transmitter makes up three quarters of the cost of a radar system
and when I started building computer systems, I heard a lot of things like:
hardware is free, developers are expensive
and, the ubiquitous:
premature optimization is the root of all evil.
None of these things are true. Some are less true than others2. Mostly, they’re so context dependent that stripping them of their context renders them meaningless. On the other hand, heuristics like this can be exceptionally valuable, saving us time reasoning things through from first principles, and allowing rapid exploration of a design space. Can we make these truisms more true, and more useful, by turning to them into frameworks for quantitative thinking?
Data referenced every five minutes should be memory resident.
Today, thirty five years later, Gray’s five minute rule is just as misleading as the ones above1. What we’re left with isn’t a rule, but a powerful and durable insight. Gray and Putzolu’s observation was that we can calculate the cost of something (storing a page of data in memory) and the cost of replacing that thing (reading the data from storage), and quantitatively estimate how long we should keep the thing.
They did it like this:
The derivation of the five minute rule goes as follows: A disc, and half a controller comfortably deliver 15 random accesses per second and are priced at about 15K$ So the price per disc
access per second is about 1K$/a/s. The extra CPU and channel cost for supporting a disc is 1K$/a/s. So one disc access per second costs about 2K$/a/s.
A megabyte of main memory costs about 5K$, so a kilobyte costs 5$. If making a 1Kb data record main-memory resident saves 1a/s, then it saves about 2K$ worth of disc accesses at a cost of 5$, a good deal. If it saves .1a/s then it saves about 200$, still a good deal. Continuing this, the break-even point is one access every 2000/5 - 400 seconds. So, any 1KB record accessed more frequently than every 400 seconds should live in main memory.
$5000 a Megabyte! Wow! But despite the straight-from-the-80s memory pricing, the insight here is durable. We can plug our storage costs, memory costs, and access costs into the story problem and get some real insight into the problems of today.
Hardware is Free?
Let’s go back to
hardware is free, developers are expensive.
Can we make that more quantitative?
The Bureau of Labor Statistics says that the median US software developer earns $52.41 an hour. A Graviton core in EC2, as of today, costs around $0.04 an hour. So it’s worth spending an hour of developer time to save anything more than around 1300 core hours. That’s about two months, so we can get write a better rule:
It’s worth spending an hour of developer time to save two core months.
Just as with Gray and Putzolu’s rule, this one is highly sensitive to your constants (developer pay, core cost, overheads, etc). But the quantitative method is durable, as is the idea that we can quickly quantitatively estimate things like this. That idea is much more powerful than rules of thumb.
The Irredeemable?
Some rules, on the other hand, are stubbornly difficult to turn into quantitative tools. Take Jevon’s Paradox, for example3:
in the long term, an increase in efficiency in resource use will generate an increase in resource consumption rather than a decrease.
If you’ve spent any time at all online, you’ll have run across folks using Jevon’s Paradox as if it were some immutable law of the universe to dismiss any type of conversation or economic effort. If we’re battling with truisms, I prefer Zeynep’s Law:
Zeynep’s law: Until there is substantial and repeated evidence otherwise, assume counterintuitive findings to be false, and second-order effects to be dwarfed by first-order ones in magnitude.
Both of these truisms seem true. They get us nodding our heads, and may even get us thinking. Unfortunately their use is limited by the fact that they don’t provide us with any tools for thinking about when they are valid, and extending them to meet our own context. From a quantitative perspective, they may be irredeemable. Not useless, just limited in power.
Conclusion
Engineering is, and software engineering sometimes stubbornly is not, a quantitative and economic discipline. I think we’d do well to emphasize the quantitative and economic side of our field. In the words of Arthur M. Wellington:
It would be well if engineering were less generally thought of, and even defined, as the art of constructing. In a certain important sense it is rather the art of not constructing; or, to define it rudely but not inaptly, it is the art of doing that well with one dollar, which any bungler can do with two after a fashion.
Footnotes
Or maybe it isn’t. In The five-minute rule thirty years later from 2017, Appuswamy et al find that for the combination of DRAM and SATA SSD there’s around a 7 minute rule. That’s very close! On the other hand, SSD performance has changed so much since 2022 that the rule is probably broken again.
And then there are the universally constant ones, like π=3 and g=10, which don’t change, but whether they are right or not is very dependent on context. Except π, which is always 3.
More Mastodon / Twitter stuff: Tom MacWright does some development with ActivityPub makes some interesting observations: "it's going to be a lot more complicated than RSS." Yes (which is why I haven't attempted to code for it yet, only for the Mastodon API). More: the highly opinionated guide to learning about ActivityPub. Mike Lapidakis shows that you need a lot of resources to run a Mastodon server, and that probably applies to ActivityPub in general. Jon Udell shows some dashboards built for his Steampipe client.
The collapse of Twitter credibility makes Muguel Guhlin rethink some of his choices for blogging platforms (I'm still surprised Google hasn't killed Blogger). Boris Mann is experimenting with the fediverse and microblogs. Also, remember Twitter Blue? It's set to relaunch with actual verification - so, just like it was before, but now with a fee. But they'll do it without Chuck Pearson, who writes a fine example of quit-Twitter lit.
An EdTech AI Multi-Post Update - Martin Weller declares 2022 to be the year of AI-generated content. "The year started with fun AI generated images and ended with ChatGPT promising the end for humanity as we know it." It's funny; generative analytics wasn't even a category in 2021 when I wrote my Ethics course; I had to add it. And now it's everywhere. And remember: I also predicted the rise of deontic analytics. So get ready.
Greg Rutkowski is not happy his distinctive style dominates AI-generated art. Meanwhile, the developers of Lensa - which produces various versions of your face - are defending themselves against accusations of stealing content. More. No only that, it's easy to trick Lensa into making NSFW images. More. That's it for the last three days. Phew!
Especially in more affluent nations, there is an epidemic of autoimmune diseases sweeping the globe. These diseases, of which there are over 100, now affect 10% of the population in some countries. They all have one thing in common: The body’s immune system, which evolved to fight infections, begins to fight and destroy healthy cells, tissues and organs. There is no known cause and no cure for any of these diseases. They are often triggered by chronic physical or psychological stress.
We understand almost nothing about our body’s immune system response, which is staggeringly complex and varied. We do know that autoimmune diseases are relatively rare or unknown in many poor countries.
One hypothesis for why this might be so is that in poor countries the immune system is regularly ‘exercised’ by being exposed to many more diseases, and hence ‘learns’ to deal appropriately with many different types of bacteria, viruses and infections. We do know that with some serious infections (like the avian ‘flu’ virus that caused the horrific 1918 pandemic) it is hyper-activity of the immune system, so-called ‘cytokine storms’, that killed most of the pandemic’s victims, not infection by the virus itself. So it’s possible that the epidemic of autoimmune diseases might be caused at least in part by an ‘ignorant’ immune system, that never learned to do its vitally important job because, ‘thanks’ to modern medicine’s protections (and massive overuse of antibiotics and other toxic chemicals and sterilizers in our medicines and foods, and keeping babies away from peanut butter, pet dander and other allergens), it never got to practice differentiating what is healthy for our bodies from what is dangerous to them.
That’s just a theory of course. But when we observe how the nation’s poorest nations have had inexplicable orders-of-magnitude lower levels of death from CoVid-19, even when carefully adjusting for reporting capability, it’s tantalizing to consider that we might have unintentionally dumbed down our own immune systems to the point that they are now actually sickening and killing us in large numbers.
The obvious metaphor is the musculoskeletal and circulatory systems of sedentary people, which atrophy and clog and result in endless ailments and injuries due to lack of proper exercise. Our body can’t learn to keep us healthy if it doesn’t have the chance to practice doing so.
If that idea isn’t radical enough, that got me thinking about the fact that those rare humans who have no sense of self and separation function perfectly well but seem to have much lower levels of anxiety, hostility to others, guilt and shame than the rest of us.
What if, at least metaphorically, the evolution (which seems unique to humans) of a ‘conscious’ (and arguably useless) sense of self-awareness and separation might actually underlie almost all human psychological suffering and mental illness? In other words, is our evolved ‘consciousness’, instead of being an evolutionary breakthrough, actually a kind of autoimmune disease? Has it made us uselessly, needlessly and endlessly hypervigilant, to the point we overreact to everything in a desperate attempt to control what is actually not within our control, and what needs no control?
It’s an imperfect metaphor, of course: We need our body’s immune system, without which we’d quickly succumb to infections and die. We don’t need our sense of consciousness and our sense of being separate and apart from everything else and in control of ‘our’ decisions. But we think we do. We cannot imagine what it is like to be without any sense of there being anyone separate. We cannot imagine not even attempting to control these bodies we seem to inhabit. We have no choice but to be hypervigilant, utterly preoccupied with protecting and ‘doing right’ by these bodies we feel it is our absolute and endless responsibility to look after.
That’s got to be crazy-making, especially when all our efforts seem so often in vain, when things don’t go the way they ‘should’, when the stresses and threats seem endless, and when we are sure that the final result of all that frenzied effort is… death.
(Have you ever had a disease with a really high fever, when despite everything else going on inside and outside your body there’s this strange sense of calm, a sense that it’s OK that you’re not quite yourself, ready to deal with every problem that might arise, that everything will be OK even though you can’t deal with it right now? Is this a glimpse, a hint, of what it’s like to be unburdened of this disease of relentless hypervigilance, free from needing to be in control, ready for anything?)
An autoimmune disease is when our bodies mistakenly damage and kill what is perfectly healthy, in the effort to ward off an invasive threat that actually isn’t real. What if our ‘minds’ do the same thing, in the form and name of ‘consciousness’? And what if the result is all human psychological suffering? And what if how that suffering manifests (in acts of war, feelings of hatred, anxiety, grief, shame, guilt etc) is all just completely unnecessary fighting against a non-existent enemy? What if we are, indeed, just one, just this?
How about an app with a spreadsheet under the hood?
Like, the experience would be this: you’re using your photos app or Zoom or expense filing SaaS tool, then you go to Settings and scroll aaaaall the way to the bottom, and tap a power user button that says “Open Spreadsheet.”
Then, magically, Google Sheets opens with all your data in it, and you can sort and query it in all the ways you couldn’t before, and change the titles of your expense claims with spreadsheet functions and that all gets reflected back into the app, or build a callout to an AI to describe all your photos and add natural language tags, do it yourself or ask a friend who knows Excel functions, or whatever really. Anything the app developers didn’t add because they’re building for the 80% use case, and you’re building just for you.
So that’s the idea.
Example #1. Where the spreadsheet is an alt UI for the app.
This is the pattern described by Geoffrey Litt and Daniel Jackson in their 2020 prototype, Wildcard.
In this paper, we present spreadsheet-driven customization, a technique that enables end users to customize software without doing any traditional programming. The idea is to augment an application’s UI with a spreadsheet that is synchronized with the application’s data. When the user manipulates the spreadsheet, the underlying data is modified and the changes are propagated to the UI, and vice versa.
You can see some videos at that link: Wildcard is a prototype browser extension and, visiting Airbnb, you can pop open a spreadsheet view and sort search results in ways not supported by the official site, run calculations etc.
Example #2. Where the spreadsheet is a canvas to weave together new apps.
Fabian Stelzer recently made a Google Sheets template called HOLOSHEET that includes functions to call out to GPT-3 (text generation) and Stable Diffusion (image synthesis) to draft and visualise movies…
HOLOSHEET, story edition!
built a google sheet powered by GPT-3 and #stablediffusion that outputs full stories, with images!
you input a prompt & the AIs generate story, visuals and a title
So you might say "The wizard approached the abyss" and specify a fantasy style from the dropdown, then an embedded, parameterised GPT-3 prompt outlines the story in four scenes, with each scene then being sent to another AI for the illustration.
So both of these are examples of that old design movement Adaptive Design(2020) – end-user adaptation of products that metaphorically have the wires hanging out the back.
Like, sometimes: when you own a house, and not only does it allow for changing around the rooms and so on, but it has been architected so that there’s a blank wall and space on the plot for you to build an extension.
As with architecture, so software.
Adaptive Design in software allows for
End-user software customisation – which means that software that was semi-useful now becomes an intrinsic part of my personal “ecosystem”
A kind of distributed R&D – where the user community has the ability to find its own solutions, and (as a developer) you can look at what has been done and more in that direction.
(The second point came up in conversation recently. Yes sure it’s important to go and talk to users and co-create solutions. But why not give people the tools and knowledge to adapt the technology themselves and then pay attention to the power users?)
What’s neat about spreadsheets, and particularly neat about Google Sheets, is that:
they’re a Figma-like infinite canvas that people already understand, and programmable too with formulas that so many already use - extensible, expressive and accessible
Google Sheets is naturally multiplayer and collaborative, so it’s possible for people to share and work socially.
They’re an interesting vernacular, spreadsheets.
What should startups do?
In the early 2000s, user interfaces were being torn up and re-invented as work went online. The response was a fluid world of web APIs, remix culture, and - to frame that with theory - Adaptive Design.
(Anyone remember Yahoo! Pipes (RIP)? A universal canvas for remixing the web with native handling of APIs and RSS… a bigger loss than Google Reader, that one.)
I feel like we’re seeing this deconstruction/reconstruction again? With generative AIs, and new multiplayer ways of working and new tools for thought, there’s a growing participation in finding out what our new tools should be and how they should behave.
Maybe this time round, instead of APIs we could have Excel formulas? APIs never had that work surface to knit them together; formulas have that built-in.
I wonder what an app team could do to be really spreadsheet friendly? I wonder what the Google Sheets team could do?
And: back in the day there were API lifecycle/management startups (that then all got acquired). Will there be equivalent startups to publish/consume/manage the spreadsheet surface?
The Orange Pi 5 has finally arrived! I received my pre-order and the board is great. So should you go out and buy it? Probably, but there are some things you should know first that you may not be expecting.
The biggest thing to know is that there is no WiFi/Bluetooth included. If you were planning on using Ethernet anyway this doesn't have much of an impact. If you do need wireless capabilities we'll cover what options are available.
In this review we'll cover what you need to know about the Orange Pi 5 including it's onboard capabilities, the available RAM options as well as benchmark the board. Let's get started!
This is great and all, but I don’t think people will get what they want out of this–namely cheaper fees or the same level of security, since the App Store review process is funded by those, and without that, all you’re going to get are scammy apps, regardless of what you believe the added value of it is.
What I would really like to see is a way for me to install and run my own apps without paying for a developer account and/or having to re-sign them every few days, and I can’t see that clearly spelled out yet.
I know Apple doesn’t really get this, but the inability to develop private applications for the hardware you own without jumping through arbitrary hoops is what keeps people like me from actively developing for the platform (and it is also why I keep dabbling with Android devices).
The reason why I've posted almost 39,000 high-quality open access photos to Flickr over the years is to be able to contribute to the commons preserving our history and geography for the future. It's hard to know what will be relevant and what won't be, and it's also hard to anticipate what will be available to researchers of the future. Being prepared for that future is the purpose of the Flickr Foundation, announced today by SmugMug CEO Ben MacAskill. Now my concern is that this is just a first step to separating open access Flickr from paid hosting. Or it may just be a way of paying for that hosting (because let's face it, hosting ain't free). SmugMug has been a good steward thus far and I choose to hope for the best. Image: Prague Castle, one of my 38,666 photos (as of right now).
A decade or so ago, systems based on something called ‘machine learning’ started producing really good results in Imagenet, a contest for computer vision researchers. Those researchers were excited, and then everyone else in AI was excited, and then, very quickly, so was everyone else in tech, as it became clear that this was a step change in what we could do with software that would generalise massively beyond cool demos for recognising cat pictures.
We might be going though a similar moment now around generative networks. 2m people have signed up to use ChatGPT, and a lot of people in tech are more than excited, and somehow even more excited than they were about using the same tech to make images a few weeks ago. How does this generalise? What kinds of things might turn into a generative ML problem? What does it mean for search (and why didn’t Google ship this)? Can it write code? Copy? Journalism? Analysis? And yet, conversely, it’s very easy to break it - to get it to say stuff that’s clearly wrong. The wave of enthusiasm around chat bots largely fizzled out as people realised their limitations, with Amazon slashing the Alexa team last month. What can we think about this, and what’s it doing?
The conceptual shift of machine learning, it seems to me, was to take a group of problems that are ‘easy for people to do, but hard for people to describe’ and turn them from logic problems into statistics problems. Instead of trying to write a series of logical tests to tell a photo of a cat from a photo of a dog, which sounded easy but never really worked, we give the computer a million samples of each and let it do the work to infer patterns in each set. Instead of people trying to write rules for the machine to apply to data, we give the data and the answers to the machine and it calculates the rules. This works tremendously well, and generalises far beyond images, but comes with the inherent limitation that such systems have no structural understanding of the question - they don’t necessarily have any concept of eyes or legs, let alone ‘cats’.
To simplify hugely, generative networks run this in reverse - once you’ve identified a pattern, you can make something new that seems to fit that pattern. So you can make more picture of ‘cats’ or ‘dogs’, and you can also combine them - ‘cats in space suits’ or ‘a country song about venture capitalists rejecting founders’. To begin with, the results tended to be pretty garbled, but as the models have got it better the outputs can be very convincing.
However, they’re still not really working from a canonical concept of ‘dog’ or ‘contract law’ as we do (or at least, as we think we do) - they’re matching or recreating or remixing a pattern that looks like that concept.
I think this is why, when I ask ChatGPT to ‘write a bio of Benedict Evans’, it says I work at Andreessen Horowitz (I left), worked at Bain (no), founded a company (no), and have written some books (no). Lots of people have posted similar examples of ‘false facts’ asserted by ChatGPT. It often looks like an undergraduate confidently answering a question for which it didn’t attend any lectures. It looks like a confident bullshitter, that can write very convincing nonsense. OpenAI calls this ‘hallucinating’.
But what exactly does this mean? Looking at that bio again, it’s an extremely accurate depiction of the kind of thing that bios of people like me tend to say. It’s matching a pattern very well. Is that false? It depends on the question. These are probabilistic models, but we perceive the accuracy of probabilistic answers differently depending on the domain. If I ask for ‘the chest burster scheme in Alien as directed by Wes Anderson’ and get a 92% accurate output, no-one will complain that Sigourney Weaver had a different hair style. But if I ask for some JavaScript, or a contract, I might get a ‘98% accurate’ result that looks a lot like the JavaScript I asked for, but the 2% error might break the whole thing. To put this another way, some kinds of request don’t really have wrong answers, some can be roughly right, and some can only be precisely right or wrong, and cannot be ‘98% correct’.
So, the basic use-case question for machine learning as it generalised was “what can we turn into image recognition?” or “what can we turn into pattern recognition?” The equivalent question for generative ML might be “what can we turn into pattern generation?” and “what use cases have what kinds of tolerance for the error range or artefacts that come with this?”
This might be a useful way to think about what this means for Google and the idea of ‘generative search’ - what kind of questions are you asking? How many Google queries are searches for something specific, and how many are actually requests for an answer that could be generated dynamically, and with what kinds of precision? If you ask a librarian a question, do you ask them where the atlas is or ask them to tell you the longest river in South America?
But more generally, the breakthroughs in ML a decade ago came with cool demos of image recognition, but image recognition per se wasn’t the point - every big company has deployed ML now for all sorts for things that look nothing like those demos. The same today - what are the use cases where pattern generation at a given degree of accurate is useful, or that could be turned into pattern generation, that look nothing like the demos? What’s the right level of abstraction to think about? Qatalog, a no-code collaboration tool, is now using generative ML to make new apps - instead of making a hundred templates and asking the user to pick, the user types in what they want and they system generates it (my friends at Mosaic Ventures are investors). This don’t look like the viral generative ML demos, and indeed it doesn’t look like ML at all, but then most ML products today don’t ‘look’ like ML - that’s just how they work. So, what are the use cases that aren’t about making pictures or text at all?
There’s a second set of questions, though: how much can this create, as opposed to, well, remix?
It seems to be inherent that these systems make things based on patterns that they already have. They can be used to create something original (‘a cat in a space suit in the style of a tintype photo’), but the originality is in the prompt, just as a photograph can be art, or not, depending on where you point the camera and why. But if the advance from chatbots to ChatGPT is in automating the answers, can we automate the questions as well? Can we automate the prompt engineering?
It might be useful here to contrast AlphaGo with the old saying that a million monkeys with typewriters would, in time, generate the complete works of Shakespeare. AlphaGo generated moves and strategies that Go experts found original and valuable, and it did that by generating huge numbers of moves and seeing which ones worked - which ones were good. This was possible because it could play Go against itself and see what was good. It had feedback - automated, scalable feedback. Conversely, the monkeys could create a billion plays, some gibberish and some better than Shakespeare, but they would have no way to know which was which, and we could never read them all to see. Borges’s Library is full of masterpieces no human has ever seen, but how can you find them? What would the scoring system be?
Hence, a generative ML system could make lots more ‘disco’ music, and it could make punk if you described it specifically enough (again, prompt engineering), but it wouldn’t know it was time for a change and it wouldn’t know that punk would express that need. When can you ask for ‘something raw, fresh and angry that’s a radical change from prog rock?’ And when can a system know people might want that? There is some originality in creating new stuff that looks like the patterns we already have, but the originality that matters is in breaking the pattern. Can you score that?
There’s a joke that AI stands for ‘Anonymous Indians’, because before you can give an image recognition systems a million pictures of dogs and a million pictures of cats as data for automated training, actual humans in an outsourcing company have to label all those images. There are people in the loop. But then, every billion-scale system we use today relies on people in the loop. Google Search analyses how people interact with the internet just as much as it analyses the content itself. Instagram can recommend things to you by comparing what you seem to like with what a billion other people seem to like, not by knowing what those thing are themselves. Image recognition could move that to a different level of abstraction, but who, again, labels the images?
If there are always humans in the loop - if these things are all mechanical Turks in some way - then the question is how you find the right point of leverage. Yahoo tried paying people to catalogue the entire web one site at a time, and that was unscalable. Google, on one side, is based on the patterns of aggregate human behaviour of the web, and on the other side it gives you ten results and makes you pick one - manual curation by billions of users. The index is made by machine, but the corpus it indexes is made by people and the results are chosen by people. In much the same way, generative networks, so far, rely on one side on patterns in things that people already created, and on the other on people having new ideas to type into the prompt and picking the ones that are good. So, where do you put the people, at what point of leverage, and in what domains?
One of the ways I used to describe machine learning was that it gives you infinite interns. You don’t need an expert to listen to a customer service call and hear that the customer is angry and the agent is rude, just an intern, but you can’t get an intern to listen to a hundred million calls, and with machine learning you can. But the other side of this is that ML gives you not infinite interns but one intern with super-human speed and memory - one intern who can listen to a billion calls and say ‘you know, after 300m calls, I noticed a pattern you didn’t know about…’ That might be another way to look at a generative network - it’s a ten-year-old that’s read every book in the library and can repeat stuff back to you, but a little garbled and with no idea that Jonathan Swift wasn’t actually proposing, modestly, a new source of income for the poor.
What can they make, then? It depends what you can ask, and what you can explain to them and show to them, and how much explanation they need. This is really a much more general machine learning question - what are domains that are deep enough that machines can find or create things that people could never see, but narrow enough that we can tell a machine what we want?
Here's a trick I've been using to compare the rows in a table before and after I perform an operation against it. It works well for a few hundred (and maybe a few thousand) rows.
First, get hold of a copy of the primary keys (or some other unique column) in the existing table, as JSON.
select json_group_array(id) from mytable
This will return a JSON string, which you can copy and paste somewhere.
I ran it against my repos table here to select repo names, like this:
select
full_name
from
repos
where
full_name not in (
select
value
from
json_each(
'["simonw/datasette","simonw/csvs-to-sqlite","simonw/datasette-plugin-demos","simonw/datasette-cluster-map","simonw/register-of-members-interests-datasette","simonw/fivethirtyeight-datasette","simonw/global-power-plants-datasette","simonw/datasette-sql-scraper","simonw/datasette-leaflet-geojson","simonw/datasette-registry","simonw/datasette-vega","simonw/sqlite-utils","simonw/russian-ira-facebook-ads-datasette","simonw/datasette-json-html","simonw/russian-troll-tweets-datasette","simonw/datasette-render-images","simonw/datasette-small","simonw/24ways-datasette","simonw/sqlite-fts4","simonw/datasette-sqlite-fts4","simonw/db-to-sqlite","simonw/datasette-pretty-json","simonw/markdown-to-sqlite","simonw/dbf-to-sqlite","simonw/whosonfirst-datasette","simonw/datasette-car-2019","simonw/datasette-jellyfish","simonw/yaml-to-sqlite","simonw/datasette-render-html","simonw/datasette-jq","simonw/datasette-bplist","simonw/datasette-render-binary","simonw/fara-datasette","simonw/datasette-auth-github","simonw/sqlite-diffable","simonw/datasette-cors","dogsheep/dogsheep-beta","dogsheep/healthkit-to-sqlite","dogsheep/swarm-to-sqlite","dogsheep/twitter-to-sqlite","dogsheep/inaturalist-to-sqlite","dogsheep/google-takeout-to-sqlite","dogsheep/github-to-sqlite","simonw/datasette-rure","simonw/datasette-atom","dogsheep/genome-to-sqlite","dogsheep/pocket-to-sqlite","simonw/datasette-render-timestamps","dogsheep/dogsheep.github.io","simonw/museums","simonw/datasette-haversine","simonw/sqlite-transform","simonw/datasette-csvs","simonw/datasette-render-markdown","simonw/datasette-template-sql","simonw/asgi-log-to-sqlite","simonw/datasette-configure-asgi","simonw/datasette-upload-csvs","simonw/datasette-auth-existing-cookies","simonw/datasette-sentry","simonw/geojson-to-sqlite","simonw/datasette-debug-asgi","simonw/shapefile-to-sqlite","simonw/datasette-mask-columns","simonw/datasette-ics","simonw/datasette-configure-fts","simonw/fec-to-sqlite","simonw/datasette-search-all","simonw/datasette-column-inspect","simonw/covid-19-datasette","simonw/datasette-edit-schema","simonw/datasette-publish-fly","dogsheep/hacker-news-to-sqlite","simonw/datasette-show-errors","simonw/datasette-publish-vercel","simonw/big-local-datasette","simonw/datasette-clone","dogsheep/dogsheep-photos","simonw/til","simonw/datasette-media","simonw/datasette-permissions-sql","simonw/datasette-auth-tokens","simonw/datasette-psutil","simonw/datasette-plugin","simonw/datasette-plugin-template-demo","simonw/datasette-saved-queries","simonw/datasette.io","simonw/sqlite-generate","simonw/datasette-block-robots","simonw/datasette-glitch","simonw/datasette-init","simonw/datasette-write","simonw/datasette-allow-permissions-debug","simonw/sba-loans-covid-19-datasette","simonw/datasette-auth-passwords","simonw/srccon-2020-datasette","simonw/datasette-insert","simonw/datasette-copyable","simonw/datasette-insert-unsafe","simonw/datasette-graphql","simonw/parlgov-datasette","simonw/homebrew-datasette","simonw/datasette-io-redirect","simonw/datasette-schema-versions","simonw/calands-datasette","simonw/datasette-yaml","simonw/datasette-backup","simonw/sqlite-dump","simonw/datasette-dns","simonw/datasette-seaborn","simonw/sqlite-fts5-trigram","simonw/datasette-dateutil","simonw/datasette-import-table","simonw/buildpack-datasette","simonw/datasette-json-preview","dogsheep/evernote-to-sqlite","simonw/sphinx-to-sqlite","simonw/datasette-edit-templates","simonw/datasette-indieauth","simonw/datasette-ripgrep","simonw/datasette-css-properties","simonw/datasette-export-notebook","simonw/cbsa-datasette","simonw/datasette-leaflet-freedraw","simonw/datasette-leaflet","simonw/datasette-basemap","simonw/datasette-tiles","simonw/vaccinate-ca-datasette","simonw/datasette-block","simonw/us-counties-datasette","simonw/tableau-to-sqlite","simonw/django-sql-dashboard","simonw/iam-to-sqlite","simonw/azure-functions-datasette","simonw/datasette-publish-azure","simonw/datasette-placekey","simonw/datasette-remote-metadata","simonw/datasette-pyinstrument","simonw/datasette-query-links","simonw/datasette-x-forwarded-host","simonw/datasette-app","simonw/datasette-verify","simonw/datasette-plugin-template-repository","simonw/datasette-plugin-template-repository-demo-old","simonw/datasette-statistics","simonw/datasette-notebook","simonw/datasette-template-request","simonw/datasette-hello-world","simonw/datasette-jupyterlite","simonw/iam-definitions-datasette","simonw/datasette-redirect-to-https","simonw/datasette-table","simonw/datasette-hovercards","simonw/datasette-pretty-traces","simonw/datasette-tiddlywiki","simonw/google-drive-to-sqlite","simonw/datasette-redirect-forbidden","simonw/congress-legislators-datasette","simonw/datasette-hashed-urls","simonw/datasette-plugin-template-repository-demo","simonw/datasette-packages","simonw/datasette-auth0","simonw/pypi-to-sqlite","simonw/datasette-total-page-time","simonw/datasette-gzip","simonw/datasette-copy-to-memory","simonw/datasette-lite","simonw/datasette-upload-dbs","simonw/datasette-screenshots","simonw/google-calendar-to-sqlite","simonw/datasette-unsafe-expose-env","simonw/mbox-to-sqlite","simonw/datasette-socrata","simonw/datasette-low-disk-space-hook","simonw/datasette-scale-to-zero"]'
)
)
As you can see, we spend 4–8 hours in blackout during a typical day. You can notice some stepping patterns in the data — this is our energy workers trying to stabilize the blackouts into some kind of schedule, although it’s often overridden due to emergency shutdowns. More blackouts happen in the evening time because of the increased load on the grid, with everyone getting home after work and cooking dinner. There’s usually no need for blackouts at night because people go to sleep, and the load falls sharply — that’s usually the time for us to charge devices, turn on the washing machine & dishwasher, and occasionally bake something nice in the oven.
One of the fun things about being a physicist is that occasionally you end up pondering some sort of everyday phenomenon that you’ve never thought about before and realize that you can explain it with some elementary physics! Some time ago I had one of these little epiphanies and thought I would share it.
Have you ever been out driving at night after a rain storm and found yourself constantly checking to see if your headlights are on, because they don’t look like they’re on? We can explain this very simply with a basic discussion of optical reflection.
First, we can ask: how to you normally notice that your headlights are on at night? If you’re right behind another car, or passing by a nearby road sign or other roadside feature, you can probably see the light from your headlights reflected back at you. But you can also see the reflection of your headlights from the road ahead of you.
In fact, because the pavement is a rough surface, the light from the headlights scatter in all directions when they collide with the road. This is what we call diffuse reflection, and it is the most common type of reflection you see. Most surfaces are not terribly smooth, and so the light hitting it scatters every which way. In the case of the car, some of the light from the headlights bounces back towards you, so you can see, indirectly, that your headlights are on.
But what about when it has rained? If there is enough water on the pavement, it fills in all the little crevices in the pavement, making it effectively a smooth surface, like a mirror. Then you get the elementary case of what is referred to as specular reflection, where the angle of reflection is equal to the angle of incidence . This means that nearly all the light from the headlights ends up being directed forward, away from the car, and you don’t see any light on the pavement ahead of you.
Since we’re so used to being able to see some light reflected back on dry nights, we might doublecheck to see if our headlights are on!
Of course, if it is actively raining while you’re driving, you’ll often see light scattered off the raindrops themselves, which is why I have stressed that this is an effect that you see soon after it has rained.
Pretty sure this explanation makes sense, though I’ve never seen anyone talk about it before! It’s a nice little example of how a little bit of physics knowledge can often illuminate things you see in daily life (no pun intended).
Postscript: This also gives you an idea of why stealth aircraft are designed to have flat surfaces! Ordinary aircraft, with round bodies, tend to reflect radar waves in all directions, including back to radar defense systems, making them easy to track. Stealth aircraft, with their mostly flat surfaces, tend to reflect radar waves only in the specular direction, which is very unlikely to be in the location of a radar detector!
Phoebe Maltz Bovy 🐩@BovyMaltz
Could the streetcar that goes up and down Roncesvalles please return please I ask of you @TTCnotices please if I ask nicely
Andrew Fleischman@ASFleischman
Two immutable twitter beliefs are that conservative men are just innately more masculine and attractive than libera… twitter.com/i/web/status/1…
I've released the third alpha of Datasette 1.0. The 1.0a2 release introduces upsert support to the new JSON API and makes some major improvements to the Datasette permissions system.
New /db/table/-/upsert API, documented here. Upsert is an update-or-insert: existing rows will have specified keys updated, but if no row matches the incoming primary key a brand new row will be inserted instead. (#1878)
This table has a primary key of id. The above API call will create three records if the table is empty. But if the table already has records matching any of those primary keys, their name and born columns will be updated to match the incoming data.
Upserts can be a really convenient way of synchronizing data with an external data source. I had a couple of enquiries about them when I published the first alpha, so I decided to make them a key feature for this release.
Ignore and replace for the create table API
The /db/-/create API for creating a table now accepts "ignore": true and "replace": true options when called with the "rows" property that creates a new table based on an example set of rows. This means the API can be called multiple times with different rows, setting rules for what should happen if a primary key collides with an existing row. (#1927)
/db/-/create API now requires actor to have insert-row permission in order to use the "row" or "rows" properties. (#1937)
This feature is a little less obvious, but I think it's going to be really useful.
The /db/-/create API can be used to create a new table. You can feed it an explicit list of columns, but you can also give it one or more rows and have it infer the correct schema based on those examples.
Datasette inherits this feature from sqlite-utils - I've been finding this an incredibly productive way to work with SQLite databases for a few years now.
The real magic of this feature is that you can pipe data into Datasette without even needing to first check that the appropriate table has been created. It's a really fast way of getting from data to a populated database and a working API.
Prior to 1.0a2 you could call /db/-/create with "rows" more than once and it would probably work... unless you attempted to insert rows with primary keys that were already in use - in which case you would get an error. This limited the utility of the feature.
Now you can pass "ignore": true or "replace": true to the API call, to tell Datasette what to do if it encounters a primary key that already exists in the table.
Heres an example using the author data from above:
POST /books/-/create
Authorization: Bearer $TOKEN
Content-Type: application/json
This will create the authors table if it does not exist and ensure that those three rows exist in it, in their exact state. If a row already exists it will be replaced.
Note that this is subtly different from an upsert. An upsert will only update the columns that were provided in the incoming data, leaving any other columns unchanged. A replace will replace the entire row.
Finely grained permissions
This is the most significant area of improvement in this release.
New register_permissions(datasette) plugin hook. Plugins can now register named permissions, which will then be listed in various interfaces that show available permissions. (#1940)
Prior to this, permissions were just strings - things like "view-instance" or "view-table" or "insert-row".
Plugins can introduce their own permissions - many do already, like datasette-edit-schema which adds a "edit-schema" permission.
In order to start building UIs for managing permissions, I needed Datasette to know what they were!
The register_permissions() hook lets them do exactly that, and Datasette core uses it to register its own default set of permissions too.
Permissions are registered using the following named tuple:
The abbr is an abbreviation - e.g. insert-row can be abbreviated to ir. This is useful for creating things like signed API tokens where space is at a premium.
takes_database and takes_resource are booleans that indicate whether the permission can optionally be applied to a specific database (e.g. execute-sql) or to a "resource", which is the name I'm now using for something that could be a SQL table, a SQL view or a canned query.
The insert-row permission for example can be granted to the whole of Datasette, or to all tables in a specific database, or to specific tables.
Finally, the default value is a boolean that indicates whether the permission should be default-allow (view-instance for example) or default-deny (create-table and suchlike).
This next feature explains why I needed those permission names to be known to Datasette:
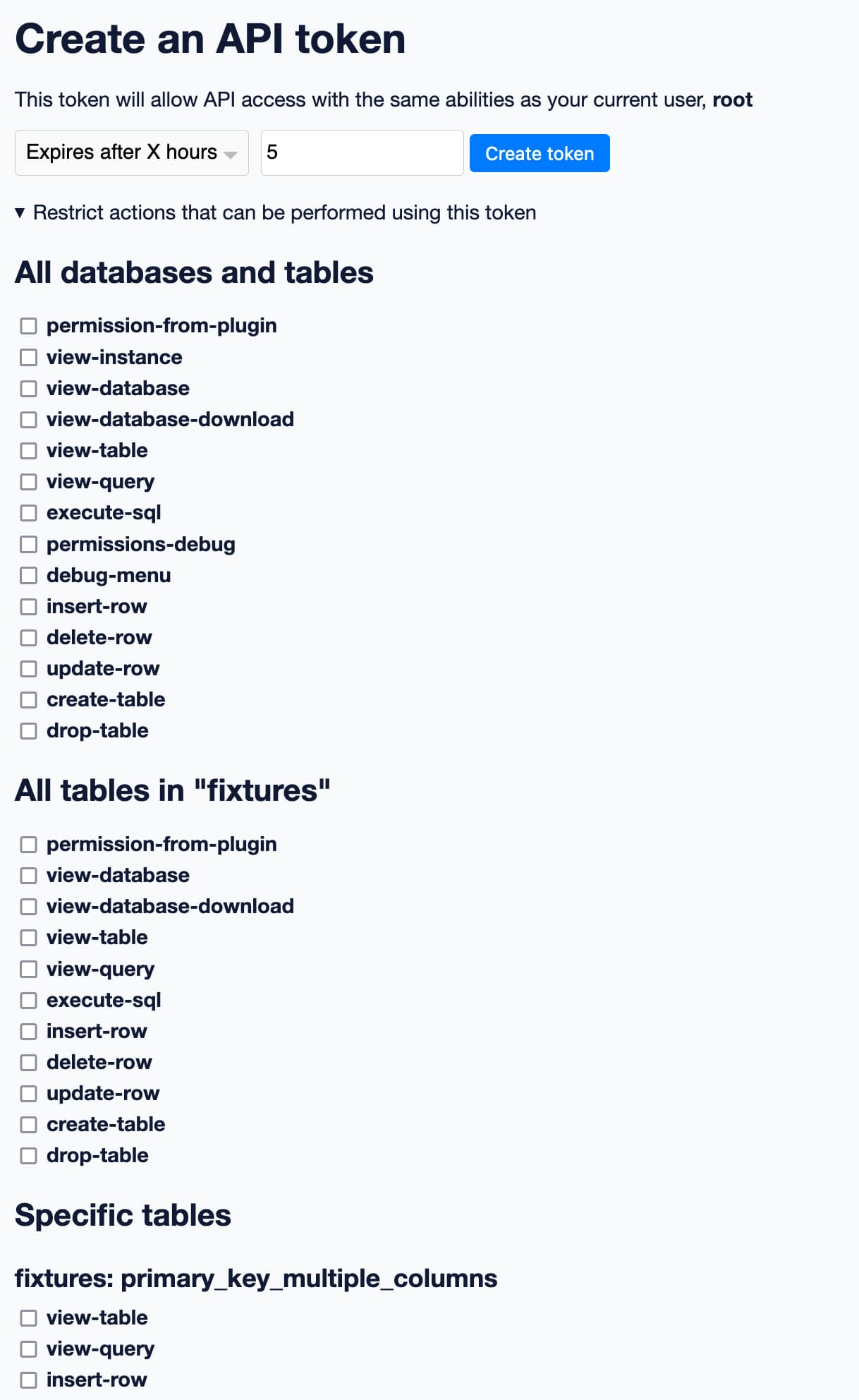
The /-/create-token page can now be used to create API tokens which are restricted to just a subset of actions, including against specific databases or resources. See API Tokens for details. (#1947)
Datasette now has finely grained permissions for API tokens!
This is the feature I always want when I'm working with other APIs: the ability to create a token that can only perform a restricted subset of actions.
When I'm working with the GitHub API for example I frequently find myself wanting to create a "personal access token" that only has the ability to read issues from a specific repository. It's infuriating how many APIs leave this ability out.
The /-/create-token interface (which you can try out on latest.datasette.io by first signing in as root and then visiting this page) lets you create an API token that can act on your behalf... and then optionally specify a subset of actions that the token is allowed to perform.
Thanks to the new permissions registration system, the UI on that page knows which permissions can be applied to which entities within Datasette itself.
Here's a partial screenshot of the UI:
Select a subset of permissions, hit "Create token" and the result will be an access token you can copy and paste into another application, or use to call Datasette with curl.
Here's an example token I created that grants view-instance permission against all of Datasette, and view-database and execute-sql permission against the ephemeral database, which in that demo is hidden from anonymous Datasette users.
Here's a screenshot of the screen I saw when I created it:
I've expanded the "token details" section to show the JSON that is bundled inside the signed token. The "_r" block records the specific permissions granted by the token:
"a": ["vi"] indicates that the view-instance permission is granted against all of Datasette.
"d": {"ephemeral": ["vd", "es"]} indicates that the view-database and execute-sql permissions are granted against the ephemeral database.
The token also contains the ID of the user who created it ("a": "root") and the time that the token was created ("t": 1671085302). If the token was set to expire that expiry duration would be baked in here as well.
You can see the effect this has on the command-line using curl like so:
In order to sign the token you need to pass in the --secret used by the server - although it will pick that up from the DATASETTE_SECRET environment variable if it's available.
This has the interesting side-effect that you can use that command to create valid tokens for other Datasette instances, provided you know the secret they're using. I think this ability will be really useful for people like myself who run lots of different Datasette instances on stateless hosting platforms such as Vercel and Google Cloud Run.
Configuring permissions in metadata.json/yaml
Arbitrary permissions can now be configured at the instance, database and resource (table, SQL view or canned query) level in Datasette's Metadata JSON and YAML files. The new "permissions" key can be used to specify which actors should have which permissions. See Other permissions in metadata for details. (#1636)
Datasette has long had the ability to set permissions for viewing databases and tables using blocks of configuration in the increasingly poorly named metadata.json/yaml files.
As I've built new plugins that introduce new permissions, I've found myself wishing for an easier way to say "user X is allowed to perform action Y" for arbitrary other permissions.
The new "permissions" key in metadata.json/yaml files allows you to do that.
Here's how to specify that the user with "id": "simon" is allowed to use the API to create tables and insert data into the docs database:
databases:
docs:
permissions:
create-table:
id: simon
insert-row:
id: simon
Here's a demo you can run on your own machine. Save the above to permissions.yaml and run the following in one terminal window:
This will create the docs.db database if it doesn't already exist, and start Datasette with the permissions.yaml metadata file.
It sets --secret to a known value (you should always use a random secure secret in production) so we can easily use it with create-token in the next step:
The first line creates a token that can act on behalf of the simon actor. The second curl line then uses that token to create a table using the /-/create endpoint.
With the 1.0a2 release I'm reasonably confident that Datasette 1.0 is new-feature-complete. There's still a lot of work to do before the final release, but the remaining work is far more intimidating: I need to make clean backwards-incompatible breakages to a whole host of existing features in order to ship a 1.0 that I can keep stable for as long as possible.
The rows key is there so I can add extra keys to the output, based on additional ?_extra= request parameters. You'll be able to get back everything you can get in the current full-fat table API, but you'll have to ask for it.
There are a ton of other changes I want to make to Datasette as a whole - things like renaming metadata.yaml to config.yaml to reflect that it's gone way beyond its origins as a way of attaching metadata to a database.
The 1.0 milestone is a dumping ground for many of these ideas. It's not a canonical reference though: I'd be very surprised if everything currently in that milestone makes it into the final 1.0 release.
As I get closer to 1.0 though I'll be refining that milestone so it should get more accurate over time.
Once again: now is the time to be providing feedback on this stuff! The Datasette Discord is a particularly valuable way for me to get feedback on the work so far, and my plans for the future.
Riffusion takes an audio file, converts it to a spectrogram (much like Capo can do) and then passes it through Stable Diffusion to make new spectrograms, and then back to an audio file.
It's like AI art, but for music.
I'm blown away by this, especially the sample where it makes a "beautiful 20-step interpolation from typing to jazz".
Sure, it's not amazing - but here's the thing; it's early days. And you know I'm absolutely going to use this to make music to play along with in the future.
My test suite for Datasette has grown so large that running the whole thing sometimes causes me to run out of file handles.
I've not solved this yet, but I did figure out a pattern to get pytest to show me which new files were opened by which tests.
Add the following to conftest.py:
import psutil
@pytest.fixture(autouse=True)
def check_for_new_file_handles(request):
proc = psutil.Process()
before_files = set(proc.open_files())
yield
after_files = proc.open_files()
new_files = [f for f in after_files if f not in before_files]
if new_files:
print("{} opened by {}".format(new_files, request.node))
This uses psutil (pip install psutil) to build a set of the open files before and after the test runs. It then uses a list comprehension to figure out which file handles are new.
Using @pytest.fixture(autouse=True) means it will automatically be used for every test.
It's a yield fixture, which means the part of the code before the yield statement runs before the test, then the part afterwards runs after the test function has finished.
Accepting the request argument means it gets access to a pytest request object, which includes request.node which is an object representing the test that is being executed.
You need to run pytest -s to see the output (without the -s the output is hidden).
Example output:
tests/test_permissions.py .[popenfile(path='/private/var/folders/wr/hn3206rs1yzgq3r49bz8nvnh0000gn/T/tmp76w2ukin/fixtures.db', fd=8)] opened by <Function test_view_padlock[/-None-200-200]>..
If you watch a war movie to see people shooting from all over, that’s what this almost felt like. One thing after the next after next, you can’t even catch up with what has to happen.
Many healthcare workers contracted COVID themselves, and not all of them survived, including friends of mine. This plaque now sits outside Bellevue Hospital to memorialize workers there who died during that first wave.
I say this all to make an important but simple point. You don’t need hard data to know that COVID hit New York City badly in the spring of 2020. Of course, variations of this would soon play out around the world. New York City was hit hard and early, but our experience didn’t turn out to be that much of an outlier, sadly. Hospitals continued to be deluged even after vaccines were available.
However, clever internet sleuths, safe on their couches, claim to have discovered something remarkable: None of this really happened. Myself and many thousands of others are said to have hallucinated or even caused the entire thing. I am referring to an article by Dr. Jessica Hockett, an educational psychologist, titled “More Questions about Spring 2020 Covid in New York City Hospitals“, which was recently posted at the anti-vaccine site, The Brownstone Institute. It claimed that “New York City’s hospital emergency departments were not at a breaking point in spring 2020. In fact, they were relatively empty and saw a 50% drop in visits”. This startling conclusion was based on five “observations”:
NYC Emergency Departments weren’t overrun by people with COVID-19 (this is false).
NYC Emergency Room respiratory visit spike may have been panic-driven (this is false).
Most people who visited NYC emergency rooms between March 2020 and June 2021 for respiratory symptoms were not admitted to the hospital (many were admitted to the hospital).
Many patients counted as COVID hospitalizations in spring 2020 were not admitted with COVID-like illness (CLI; this is false).
The relationship between hospital inpatient deaths with COVID on the death certificate and people who were hospitalized because they had COVID is unclear (this is false).
The article (falsely) concluded that doctors may have been deadlier than the virus. It said:
It’s no wonder Michael Senger, Ethical Skeptic, and other analysts (including me) have said it was misuse of ventilators, protocol-induced staffing shortages, isolation, failure to treat, similar factors that resulted in thousands of Spring 2020 iatrogenic deaths in New York City and elsewhere.
Dr. Eric Burnett, an internist at Columbia University, deconstructed Ms. Hockett’s five “observations” on Twitter. It’s worth quoting his entire thread [Editor’s note: minor changes were made for readability and clarity].
This is absolute rubbish, coming from a non-clinician who never once treated a patient, let alone treated patients in the epicenter of a global pandemic. So allow me, a NYC hospitalist, to break apart this “analysis”. A brief look at this “analysis” shows that she relied heavily upon medical billing codes during the pandemic. This is not an accurate reflection of what we were actually seeing in the hospital as I will get to later. But let me address each of her claims one by one.
Her first claim: “NYC Emergency Departments weren’t overrun by people with covid-19.”
This is objectively false. Our ERs were over capacity for weeks during the initial surge. We had critically ill, ICU level patients intubated and vented in our ED, this hasn’t happened before. She backs this claim up by saying “Only 3% of the people who came to New York City hospital EDs during the spring 2020 March [were diagnosed – Ed.]” this is because we had little to no testing in March of 2020! The testing we did have was reserved for people who traveled from mainland China.
When we secured a test it took a week to get back bc there was only one lab that ran the PCR. We had to test patients for Flu and other resp viruses. When those were neg we gave them a presumed dx ofC19 (along with the clinical presentation supporting the diagnosis).
Saying our EDs weren’t overrun bc you didn’t see a lot of lab confirmed C19 at that time is ridiculous. On a personal note, we lost an ED physician to suicide bc of the sheer amount of devastation she bore witness to. It’s extremely disrespectful to suggest a this.
Claim number 2: NYC Emergency Room respiratory visit spike may have been panic-driven.
She backs this claim up by saying “But most emergency room visitors with respiratory symptoms were not diagnosed with covid. Huh.” I’ll refer you to my point about lack of testing above.
The amount of pts p/w acute hypoxemic respiratory failure was so great we had to train non pulm faculty on how to manage vents, HFNC, and BiPAP. We had ethics meetings about the possibility of scarce resource allocation should we run out of ventilators. This is not a normal.
Point 3: Most people who visited NYC emergency rooms between March 2020 and June 2021 for respiratory symptoms were not admitted to the hospital
We literally had to convert non-clinical spaces like our lobby into patient care units.
We had to convert a football field into a patient ward. We needed to expand hospital capacity in the state by 50% to accommodate admissions. Our traditional hospitalist census is around 100-110 patients, that ballooned to 250 during the worst of the surge. save me this excuse.
She backs this up by saying “Peak hospital admissions for covid-like illness (CLI) were 40% of respiratory emergency department visits”
We didn’t admit everyone with a respiratory illness. If they weren’t hypoxic then they didn’t get admitted.
That’s because our hospitals were over capacity and we couldn’t admit every single person with resp symptoms. It’s called triage, you should look it up. Only the sickest covid patients were admitted to the hospital.
Claim 4: Many patients counted as covid hospitalizations in spring 2020 were not admitted with covid-like illness (CLI). Data indicate that approximately 40% of inpatients with a covid diagnosis[…]from mid-March through April 2020 had not been admitted with covid-like illness.
This is what happens when you rely solely upon medical billing codes rather than talking to actual HCW. NYS issued immunity from record keeping liability during the worst of the pandemic. Medical coding [didn’t] accurately reflect the reality.
re medical record keeping liability:
“Including, but not limited to, requirements to maintain medical records that accurately reflect the evaluation and treatment of patients, or requirement to assign diagnostic codes, or to create or maintain other records for billing purposes.”
When a patient came in with covid we documented it, but didn’t always list every other symptom they had. Medical billing and coding took a backseat to admitting and treating our patients, running codes, updating families, and trying to keep our patients alive.
Claim 5: The relationship between hospital inpatient deaths with covid on the death certificate and people who were hospitalized because they had covid is unclear.
This is also ridiculous. There is clear evidence of a spike in deaths during the peak of the pandemic. We needed morgue trucks to accommodate the overflow of dead patients as a result of this disease.
She attributes these deaths to iatrogenic causes without a shred of evidence to back it up. It’s clear she’s never taken care of a critically Ill covid patient. My guess is she never had to call a family member and tell them that their loved one died despite our best efforts.
She doesn’t have to live with the pain of making those calls. She never laid in bed awake at night worrying if her patients were still going to be there in the morning.
This is pure gaslighting at a time when healthcare workers are burnt out and leaving the profession in record numbers. If Jessica would like to join me on rounds this fall/winter during our respiratory virus surge I would be happy to accommodate her.
Something tells me Ms. Hockett will decline this invitation.
However, we again have the opportunity to witness a pernicious medical myth being created in real time. Despite abundant evidence to the contrary, sheltered disinformation agents will successfully convince many Americans that COVID’s threat was always overblown. Their message can be summarized as: Don’t believe the newspapers. Don’t believe the videos or photographs. Don’t believe the official death statistics. Don’t believe thousands of healthcare workers. Don’t believe gravediggers. Don’t believe those who lost multiple family members. We told you COVID wouldn’t be that bad in the spring of 2020, and we were right. Frontline doctors were always to blame.
Asking for “evidence” that New York City got hit hard by COVID makes as much sense as asking for “evidence” that New York City exists in the first place. George Orwell understood this all very well.
Dr. Jonathan Howard is a neurologist and psychiatrist based in New York City who has been interested in vaccines since long before COVID-19.
Visualization still seems like a relatively new thing, but it has a history that goes back a few centuries. The Information Graphic Visionaries book series celebrates this history with a profile of three makers — Florence Nightingale, Emma Willard, and Étienne-Jules Marey — and their work.
The series started as a Kickstarter campaign and the books have been making their way out. I just got my copy on Marey and the graphic method. I’m looking forward to digging in.
I was trying to figure out if SQLite has the ability to use more than one index as part of executing a single query, or if it only ever picks a single index that it thinks will give the best performance.
So which index, Idx1 or Idx2, will SQLite choose? If the ANALYZE command has been run on the database, so that SQLite has had an opportunity to gather statistics about the available indices, then SQLite will know that the Idx1 index usually narrows the search down to a single item (our example of fruit='Orange' is the exception to this rule) whereas the Idx2 index will normally only narrow the search down to two rows. So, if all else is equal, SQLite will choose Idx1 with the hope of narrowing the search to as small a number of rows as possible.
I tried that on my global-power-plants table, which has an index owner and another on country_long:
explain query plan
select
country_long,
count(*)
from
[global-power-plants]
where
owner = 'Cypress Creek Renewables'
Sure enough, that query indicates that only one of the indexes was used:
SEARCH TABLE global-power-plants USING INDEX "global-power-plants_owner" (owner=?)
Interesting to note that explain query plan select country_long, count(*) from [global-power-plants] reports using a covering index scan:
SCAN TABLE global-power-plants USING COVERING INDEX "global-power-plants_country_long"
But SQLite uses multiple indexes for UNION queries
On a hunch, I decided to try the following query:
explain query plan
select country_long, count(*) from [global-power-plants]
union all
select owner, count(*) from [global-power-plants]
These are skis put aside by skiers on a mountain while they're drinking hot chocolate in the chalet. Anyone, including that guy sitting in the Adirondack chair looking at his phone, could steal any of these skis. He could put a dozen pairs in his car and sell them in his car, or he could take just one and never have to rent again. But he doesn’t, because people generally don’t cheat.
Life presents us with opportunities to cheat all the time:
Bittorrent is still alive and well
You could just walk out of a restaurant or a taxi without tipping. Remember, Uber ratings happen before the tip is revealed.
You can steal someone else’s joke or media on social media and present it as your own
You can lie to would-be investors about the performance of your business
I’ve long believed that the real mystery of Silicon Valley isn’t the outsider question, “How is Silicon Valley so wild and crazy”, but actually the insider question: “How is Silicon Valley so stable?” It’s built on speculative finance, it’s full of experiments whose outcome you can’t know for years, and it has to move fast enough and fluidly enough that (at early stage anyway) it effectively works on the honour system despite the FOMO environment. It’s so interesting how, in this environment, there aren’t any scams like this...I’ve long believed that the real mystery of Silicon Valley isn’t the outsider question, “How is Silicon Valley so wild and crazy”, but actually the insider question: “How is Silicon Valley so stable?”
Why is it that people don't cheat more often when it seems like they'd have something to gain and almost nothing to lose?
Why don’t people cheat more often?
Sure, there are people out there who, when faced with these opportunities to cheat, take the immoral path. Why don’t people cheat? Three reasons:
Fear of getting caught. This is why we have a justice system, and to be clear I’m not suggesting that if convenience stores or car dealerships switched to a “pay what you want” model that people would generally pay fair value. But from Bittorrenting to tipping or stealing social media there’s almost no method to even mete out punishment, and people still generally do the right thing. (Yes of course every Instagram meme account is just re-posting others' memes but I think everyone, blockchain-provenance maximalists aside, would agree we have a pretty well functioning meme economy).
Self-esteem. I’d venture to guess that 90% of people believe they’re in the top 10% of moral behavior, and that’s an important belief to maintain in order to get out of bed every morning. By contrast, the reason people believe that sociopaths like SBF, Elizabeth Holmes and Bernie Madoff will eventually get caught—that is, we all know they won't cheat enough just to get ahead and stop—is that tolerance for lying is a fatal flaw; a person with that kind of sociopathy has as much chance at survival as an organism with no fear of or ability to experience pain. It’s also worth noting that people’s overestimation of their own rectitude explains why they overestimate other people's proclivity to cheat; surely the 90% of people who are less moral, everyone thinks, must be jumping at the chance to cheat. But of course only 10% of those people are actually in the top 10%.
People are convenience seekers more than they are capital-seekers. We all know how the Napster/Bittorrent story ends: Spotify and Netflix etc. have such good user experiences that they’re worth the $12/month. It’s for similar reasons that people don’t just steal other people’s skis; ski rentals are convenient enough to be worth the price. It’s not so much an economic calculation as a Larry-David-esque eh when comparing the convenient paid option with the free immoral option. Heck even the ski dude on the Adirondack chair fiddling with his phone is evidence of this; fiddling with your phone is more convenient than stealing a bunch of skis.
Anxiety about cheating generally reveals anxiety about systems that are already flawed
As Byrne Hobart puts it in Deepfakes Paranoia Considered Pointless, the anxiety about deepfakes is similar to the anxiety we once had about Napster: it’s generally an expression of a system whose distribution monopoly is eroding.
Music once had an atom-based distribution monopoly on the production of records and CD’s the same way the media once had a distribution monopoly on plopping newspapers on people’s driveways. The erosion of those monopolies naturally causes finger-pointing at bad things that will happen in this new world: artists not getting paid because of torrents and people with no editorial standards influencing the conversation. Sure we experienced some pain and attrition with Napster just as we’re experiencing some pain now with the unbundling of media organizations, but then again if you’re a media organization today you might look at how all the music groups survived just fine. If Soundcloud was born out of a new bottom-up promise in music, and Substack is to media and Soundcloud is to music, that’s a pretty tolerable outcome.
The same is true in education, where there are newfound concerns with cheating via GPT. But in reality cheating isn’t really much of a problem:
Cheating is a minor issue in education and the AI cheating arms race that is about to occur doesn’t matter that much.
Education is primarily about helping a student willingly learn. It is not primarily about validating qualifications for a credential.
Cheating isn’t a problem in school because deep down, even the less motivated kids acknowledge that there’s some merit in school, and cheating your way through K-12 and college would render all those years a waste of time and opportunity. Also, cheating feels bad.
It’s also true that Education has some monopoly on education, but we can deal with that. Some new technologies have become inconveniently convenient to the status quo, but not only is human behavior pretty Lindy, people are generally more upright than we give them credit for.
The first video game was a 1952 research product called OXO — tic-tac-toe played on a computer the size of a large room:
Copyright Computer Laboratory, University of Cambridge, CC BY 2.0
Fifteen years later Ralph Baer produced “The Brown Box”; Magnavox licensed Baer’s device and released it as the Odyssey five years later — it was the first home video game console:
The Odyssey made Magnavox a lot of money, but not through direct sales: the company sued Atari for ripping off one of the Odyssey’s games to make “Pong”, the company’s first arcade game and, in 1975, first home video game, eventually reaping over $100 million in royalties and damages. In other words, arguments about IP and control have been part of the industry from the beginning.
In 1977 Atari released the 2600, the first console I ever owned:1
All of the games for the Atari were made by Atari, because of course they were; IBM had unbundled mainframe software and hardware in 1969 in an (unsuccessful) attempt to head off an antitrust case, but video games barely existed as a category in 1977. Indeed, it was only four years earlier when Steve Wozniak had partnered with Steve Jobs to design a circuit board for Atari’s Breakout arcade game; this story is most well-known for the fact that Jobs lied to Wozniak about the size of the bonus he earned, but the pertinent bit for this Article is that video game development was at this point intrinsically tied to hardware.
That, though, was why the 2600 was so unique: games were not tied to hardware but rather self-contained in cartridges, meaning players would use the same system to play a whole bunch of different games:
The implications of this separation did not resonate within Atari, which had been sold by founder Nolan Bushnell to Warner Communications in 1976, in an effort to get the 2600 out the door. Game Informer explains what happened:
In early 1979, Atari’s marketing department issued a memo to its programing staff that listed all the games Atari had sold the previous year. The list detailed the percentage of sales each game had contributed to the company’s overall profits. The purpose of the memo was to show the design team what kinds of games were selling and to inspire them to create more titles of a similar breed…David Crane, Larry Kaplan, Alan Miller, and Bob Whitehead were four of Atari’s superstar programmers. Collectively, the group had been responsible for producing many of Atari’s most critical hits…
“I remember looking at that memo with those other guys,” recalls Crane, “and we realized that we had been responsible for 60 percent of Atari’s sales in the previous year – the four of us. There were 35 people in the department, but the four of us were responsible for 60 percent of the sales. Then we found another announcement that [Atari] had done $100 million in cartridge sales the previous year, so that 60 percent translated into $60 million.”
These four men may have produced $60 million in profit, but they were only making about $22,000 a year. To them, the numbers seemed astronomically disproportionate. Part of the problem was that when the video game industry was founded, it had molded itself after the toy industry, where a designer was paid a fixed salary and everything that designer produced was wholly owned by the company. Crane, Kaplan, Miller, and Whitehead thought the video game industry should function more like the book, music, or film industries, where the creative talent behind a project got a larger share of the profits based on its success.
The four walked into the office of Atari CEO Ray Kassar and laid out their argument for programmer royalties. Atari was making a lot of money, but those without a corner office weren’t getting to share the wealth. Kassar – who had been installed as Atari’s CEO by parent company Warner Communications – felt obligated to keep production costs as low as possible. Warner was a massive corporation and everyone helped contribute to the company’s success. “He told us, ‘You’re no more important to those projects than the person on the assembly line who put them together. Without them, your games wouldn’t have sold anything,’” Crane remembers. “He was trying to create this corporate line that it was all of us working together that make games happen. But these were creative works, these were authorships, and he didn’t get it.”
“Kassar called us towel designers,” Kaplan told InfoWorld magazine back in 1983, “He said, ‘I’ve dealt with your kind before. You’re a dime a dozen. You’re not unique. Anybody can do a cartridge.’”
That “anyone” included the so-called “Gang of Four”, who decided to leave Atari and form the first 3rd-party video game company; they called it Activision.
3rd-Pary Software
Activision represented the first major restructuring of the video game value chain; Steve Wozniak’s Breakout was fully integrated in terms of hardware and software:
The Atari 2600 with its cartridge-based system modularized hardware and software:2
Activision took that modularization to its logical (and yet, at the time, unprecedented) extension, by being a different company than the one that made the hardware:
Activision, which had struggled to raise money given the fact it was targeting a market that didn’t yet exist, and which faced immediate lawsuits from Atari, was a tremendous success; now venture capital was eager to fund the market, leading to a host of 3rd-party developers, few of whom had the expertise or skill of Activision. The result was a flood of poor quality games that soured consumers on the entire market, leading to the legendary video game crash of 1983: industry revenue plummeted from $3.2 billion in 1983 to a mere $100 million in 1985. Activision survived, but only by pivoting to making games for the nascent personal computing market.
The personal computer market was modular from the start, and not just in terms of software. Compaq’s success in reverse-engineering the IBM PC’s BIOS created a market for PC-compatible computers, all of which ran the increasingly ubiquitous Microsoft operating system (first DOS, then Windows). This meant that developers like Activision could target Windows and benefit from competition in the underlying hardware.
Moreover, there were so many more use cases for the personal computer, along with a burgeoning market in consumer-focused magazines that reviewed software, that the market was more insulated from the anarchy that all but destroyed the home console market.
That market saw a rebirth with Nintendo’s Famicom system, christened the “Nintendo Entertainment System” for the U.S. market (Nintendo didn’t want to call it a console to avoid any association with the 1983 crash, which devastated not just video game makers but also retailers). Nintendo created its own games like Super Mario Bros. and Zelda, but also implemented exacting standards for 3rd-party developers, requiring them to pass a battery of tests and pay a 30% licensing fee for a maximum of five games a year; only then could they receive a dedicated chip for their cartridge that allowed it to work in the NES.
Nintendo’s firm control of the third-party developer market may look familiar: it was an early precedent for the App Store battles of the last decade. Many of the same principles were in play:
Nintendo had a legitimate interest in ensuring quality, not simply for its own sake but also on behalf of the industry as a whole; similarly, the App Store, following as it did years of malware and viruses in the PC space, restored customer confidence in downloading third-party software.
It was Nintendo that created the 30% share for the platform owner that all future console owners would implement, and which Apple would set as the standard for the App Store.
While Apple’s App Store lockdown is rooted in software, Nintendo had the same problem that Atari had in terms of the physical separation of hardware and software; this was overcome by the aforementioned lockout chips, along with branding the Nintendo “Seal of Quality” in an attempt to fight counterfeit lockout chips.
Nintendo’s strategy worked, but it came with long-term costs: developers, particularly in North America, hated the company’s restrictions, and were eager to support a challenger; said challenger arrived in the form of the Sega Genesis, which launched in the U.S. in 1989. Sega initially followed Nintendo’s model of tight control, but Electronic Arts reverse-engineered Sega’s system, and threatened to create their own rival licensing program for the Genesis if Sega didn’t dramatically loosen their controls and lower their royalties; Sega acquiesced and went on to fight the Super Nintendo, which arrived in the U.S. in 1991, to a draw, thanks in part to a larger library of third-party games.
Sony’s Emergence
The company that truly took the opposite approach to Nintendo was Sony; after being spurned by Nintendo in humiliating fashion — Sony announced the Play Station CD-ROM add-on at CES in 1991, only for Nintendo to abandon the project the next day — the electronics giant set out to create their own console which would focus on 3D-graphics and package games on CD-ROMs instead of cartridges. The problem was that Sony wasn’t a game developer, so it started out completely dependent on 3rd-party developers.
One of the first ways that Sony addressed this was by building an early partnership with Namco, Sega’s biggest rival in terms of arcade games. Coin-operated arcade games were still a major market in the 1990s, with more revenue than the home market for the first half of the decade. Arcade games had superior graphics and control systems, and were where new games launched first; the eventual console port was always an imitation of the original. The problem, however, is that it was becoming increasingly expensive to build new arcade hardware, so Sony proposed a partnership: Namco could use modified PlayStation hardware as the basis of its System 11 arcade hardware, which would make it easy to port its games to PlayStation. Namco, which also rebuilt its more powerful Ridge Racer arcade game for the PlayStation, took Sony’s offer: Ridge Racer launched with the Playstation, and Tekken was a massive hit given its near perfect fidelity to the arcade version.
Sony was much better for 3rd-party developers in other ways, as well: while the company maintained a licensing program, its royalty rates were significantly lower than Nintendo’s, and the cost of manufacturing CD-ROMs was much lower than manufacturing cartridges; this was a double whammy for the Nintendo 64 because while cartridges were faster and offered the possibility of co-processor add-ons, what developers really wanted was the dramatically increased amount of storage CD-ROMs afforded. The Playstation was also the first console to enable development on the PC in a language (C) that was well-known to existing developers. In the end, despite the fact that the Nintendo 64 had more capable hardware than the PlayStation, it was the PlayStation that won the generation thanks to a dramatically larger game library, the vast majority of which were third-party games.
Sony extended that advantage with the PlayStation 2, which was backwards compatible with the PlayStation, meaning it had a massive library of 3rd-party games immediately; the newly-launched Xbox, which was basically a PC, and thus easy to develop for, made a decent showing, while Nintendo struggled with the Gamecube, which had both a non-standard controller and non-standard microdisks that once again limited the amount of content relative to the DVDs used for PlayStation 2 and Xbox (and it couldn’t function as a DVD player, either).
This period for video games was the high point in terms of console competition for 3rd-party developers for two reasons:
First, there were still meaningful choices to be made in terms of hardware and the overall development environment, as epitomized by Sony’s use of CD-ROMs instead of cartridges.
Second, developers were still constrained by the cost of developing for distinct architectures, which meant it was important to make the right choice (which dramatically increased the return of developing for the same platform as everyone else).
It was the Sony-Namco partnership, though, that was a harbinger of the future: it behooved console makers to have similar hardware and software stacks to their competitors, so that developers would target them; developers, meanwhile, were devoting an increasing share of their budget to developing assets, particularly when the PS3/Xbox 360 generation targeted high definition, which increased their motivation to be on multiple platforms to better leverage their investments. It was Sony that missed this shift: the PS3 had a complicated Cell processor that was hard to develop for, and a high price thanks to its inclusion of a Blu-Ray player; the Xbox 360 had launched earlier with a simpler architecture, and most developers built for the Xbox first and Playstation 3 second (even if they launched at the same time).
The real shift, though, was the emergence of game engines as the dominant mode of development: instead of building a game for a specific console, it made much more sense to build a game for a specific engine which abstracted away the underlying hardware. Sometimes these game engines were internally developed — Activision launched its Call of Duty franchise in this time period (after emerging from bankruptcy under new CEO Bobby Kotick) — and sometimes they were licensed (i.e. Epic’s Unreal Engine). The impact, though, was in some respects similar to cartridges on the Atari 2600:
In this new world it was the consoles themselves that became modularized: consumers picked out their favorite and 3rd-party developers delivered their games on both.
Nintendo, meanwhile, dominated the generation with the Nintendo Wii. What was interesting, though, is that 3rd-party support for the Wii was still lacking, in part because of the underpowered hardware (in contrast to previous generations): the Wii sold well because of its unique control method — which most people used to play Wii Sports — and Nintendo’s first-party titles. It was, in many respects, Nintendo’s most vertically-integrated console yet, and was incredibly successful.
Sony Exclusives
Sony’s pivot after the (relatively) disappointing PlayStation 3 was brilliant: if the economic imperative for 3rd-party developers was to be on both Xbox and PlayStation (and the PC), and if game engines made that easy to implement, then there was no longer any differentiation to be had in catering to 3rd-party developers.
Instead Sony beefed up its internal game development studios and bought up several external ones, with the goal of creating PlayStation 4 exclusives. Now some portion of new games would not be available on Xbox not because it had crappy cartridges or underpowered graphics, but because Sony could decide to limit its profit on individual titles for the sake of the broader PlayStation 4 ecosystem. After all, there would still be a lot of 3rd-party developers; if Sony had more consoles than Microsoft because of its exclusives, then it would harvest more of those 3rd-party royalty fees.
Those fees, by the way, started to head back up, particularly for digital-only versions, which returned to that 30% cut that Nintendo had pioneered many years prior; this is the downside of depending on universal abstractions like game engines while bearing high development costs: you have no choice but to be on every platform no matter how much it costs.
Sony bet correctly: the PS4 dominated its generation, helped along by Microsoft making a bad bet of its own by packing in the Kinect with the Xbox One. It was a repeat of Sony’s mistake with the PS3, in that it was a misguided attempt to differentiate in hardware when the fundamental value chain had long since dictated that the console was increasingly a commodity. Content is what mattered — at least as long as the current business model persisted.
Nintendo, meanwhile, continued to march to its own vertically-integrated drum: after the disastrous Wii U the company quickly pivoted to the Nintendo Switch, which continues to leverage its truly unique portable form factor and Nintendo’s first-party games to huge sales. Third party support, though, remains extremely tepid; it’s just too underpowered, and the sort of person that cares about third-party titles like Madden or Call of Duty has long since bought a PlayStation or Xbox.
First, the video game market has proven to be extremely dynamic, particularly in terms of 3rd-party developers:
Atari was vertically integrated
Nintendo grew the market with strict control of 3rd-party developers
Sony took over the market by catering to 3rd-party developers and differentiating on hardware
Xbox’s best generation leaned into increased commodification and ease-of-development
Sony retook the lead by leaning back into vertical integration
That is quite the round trip, and it’s worth pointing out that attempting to freeze the market in its current iteration at any point over the last forty years would have foreclosed future changes.
At the same time, Sony’s vertical integration seems more sustainable than Atari’s. First, Sony owns the developers who make the most compelling exclusives for its consoles; they can’t simply up-and-leave like the Gang of Four. Second, the costs of developing modern games has grown so high that any 3rd-party developer has no choice but to develop for all relevant consoles. That means that there will never be a competitor who wins by offering 3rd-party developers a better deal; the only way to fight back is to have developers of your own, or a completely different business model.
The first fear raised by the FTC is that Microsoft, by virtue of acquiring Activision, is looking to fight its own exclusive war, and at first blush it’s a reasonable concern. After all, Activision has some of the most popular 3rd-party games, particularly the aforementioned Call of Duty franchise. The problem with this reasoning, though, is that the price Microsoft paid for Activision was a multiple of Activision’s current revenues, which include billions of dollars for games sold on Playstation. To suddenly cut Call of Duty (or Activision’s other multi-platform titles) off from Playstation would be massively value destructive; no wonder Microsoft said it was happy to sign a 10-year deal with Sony to keep Call of Duty on PlayStation.
Just for clarity’s sake, the distinction here from Sony’s strategy is the fact that Microsoft is acquiring these assets. It’s one thing to develop a game for your own platform — you’re building the value yourself, and choosing to harvest it with an ecosystem strategy as opposed to maximizing that games’ profit. An acquirer, though, has to pay for the business model that already exists.
At the same time, though, it’s no surprise that Microsoft has taken in-development assets from its other acquisition like ZeniMax and made them exclusives; that is the Sony strategy, and Microsoft was very clear when it acquired ZeniMax that it would keep cross-platform games cross-platform but may pursue a different strategy for new intellectual property. CEO of Microsoft Gaming Phil Spencer told Bloomberg at the time:
In terms of other platforms, we’ll make a decision on a case-by-case basis.
Given this, it’s positively bizarre that the FTC also claims that Microsoft lied to the E.U. with regards to its promises surrounding the ZeniMax acquisition: the company was very clear that existing cross-platform games would stay cross-platform, and made no promises about future IP. Indeed, the FTC’s claims were so off-base that the European Commission felt the need to clarify that Microsoft didn’t mislead the E.U.; from Mlex:
Microsoft didn’t make any “commitments” to EU regulators not to release Xbox-exclusive content following its takeover of ZeniMax Media, the European Commission has said. US enforcers yesterday suggested that the US tech giant had misled the regulator in 2021 and cited that as a reason to challenge its proposed acquisition of Activision Blizzard. “The commission cleared the Microsoft/ZeniMax transaction unconditionally as it concluded that the transaction would not raise competition concerns,” the EU watchdog said in an emailed statement.
The absence of competition concerns “did not rely on any statements made by Microsoft about the future distribution strategy concerning ZeniMax’s games,” said the commission, which itself has opened an in-depth probe into the Activision Blizzard deal and appears keen to clarify what happened in the previous acquisition. The EU agency found that even if Microsoft were to restrict access to ZeniMax titles, it wouldn’t have a significant impact on competition because rivals wouldn’t be denied access to an “essential input,” and other consoles would still have a “large array” of attractive content.
The FTC’s concerns about future IP being exclusive ring a bit hypocritical given the fact that Sony has been pursuing the exact same strategy — including multiple acquisitions — without any sort of regulatory interference; more than that, though, to effectively make up a crime is disquieting. To be fair, those Sony acquisitions were a lot smaller than Activision, but this goes back to the first point: the entire reason Activision is expensive is because of its already-in-market titles, which Microsoft has every economic incentive to keep cross-platform (and which it is willing to commit to contractually).
Whither Competition
It’s the final FTC concern, though, that I think is dangerous. From the complaint:
These effects are likely to be felt throughout the video gaming industry. The Proposed Acquisition is reasonably likely to substantially lessen competition and/or tend to create a monopoly in both well-developed and new, burgeoning markets, including highperformance consoles, multi-game content library subscription services, and cloud gaming subscription services…
Multi-Game Content Library Subscription Services comprise a Relevant Market. The anticompetitive effects of the Proposed Acquisition also are reasonably likely to occur in any relevant antitrust market that contains Multi-Game Content Library Subscription Services, including a combined Multi-Game Content Library and Cloud Gaming Subscription Services market.
Cloud Gaming Subscription Services are a Relevant Market. The anticompetitive effects of the Proposed Acquisition alleged in this complaint are also likely to occur in any relevant antitrust market that contains Cloud Gaming Subscription Services, including a combined Multi-Game Content Library and Cloud Gaming Subscription Services market.
A huge amount of discussion around this acquisition was focused on Microsoft needing its own stable of exclusives in order to compete with Sony, but it’s important to note that making all of ZeniMax’s games exclusives would be hugely value destructive, at least in the short-to-medium term. Microsoft is paying $7.5 billion for a company that currently makes money selling games on PC, Xbox, and PS5, and simply cutting off one of those platforms — particularly when said platform is willing to pay extra for mere timed exclusives, not all-out exclusives — is to effectively throw a meaningful chunk of that value away. That certainly doesn’t fit with Nadella’s statement that “each layer has to stand on its own for what it brings”…
Microsoft isn’t necessarily buying ZeniMax to make its games exclusive, but rather to apply a new business model to them — specifically, the Xbox Game Pass subscription. This means that Microsoft could, if it chose, have its cake and eat it too: sell ZeniMax games at their usual $60~$70 price on PC, PS5, Xbox, etc., while also making them available from day one to Xbox Game Pass subscribers. It won’t take long for gamers to quickly do the math: $180/year — i.e. three games bought individually — gets you access to all of the games, and not just on one platform, but on all of them, from PC to console to phone.
Sure, some gamers will insist on doing things the old way, and that’s fine: Microsoft can make the same money ZeniMax would have as an independent company. Everyone else can buy into Microsoft’s model, taking advantage of the sort of win-win-win economics that characterize successful bundles. And, if they have a PS5 and thus can’t get access to Xbox Game Pass on their TVs, an Xbox is only an extra $10/month away.
Microsoft is willing to cannibalize itself to build a new business model for video games, and it’s a business model that is pretty darn attractive for consumers. It’s also a business model that Activision wouldn’t pursue on its own, because it has its own profits to protect. Most importantly, though, it’s a business model that is anathema to Sony: making titles broadly available to consumers on a subscription basis is the exact opposite of the company’s exclusive strategy, which is all about locking consumers into Sony’s platform.
Here’s the thing: isn’t this a textbook example of competition? The FTC is seeking to preserve a model of competition that was last relevant in the PS2/Xbox generation, but that plane of competition has long since disappeared. The console market as it is today is one that is increasingly boring for consumers, precisely because Sony has won. What is compelling about Microsoft’s approach is that they are making a bet that offering consumers a better deal is the best way to break up Sony’s dominance, and this is somehow a bad thing?
What makes this determination to outlaw future business models particularly frustrating is that the real threat to gaming today is the dominance of storefronts that exact their own tax while contributing nothing to the development of the industry. The App Store and Google Play leverage software to extract 30% from mobile games just because they can — and sure, go ahead and make the same case about Microsoft and Sony. If the FTC can’t be bothered to check the blatant self-favoring inherent in these models, at the minimum it seems reasonable to give a chance to a new kind of model that could actual push consumers to explore alternative ways to game on their devices.
For the record, I do believe this acquisition demands careful overview, and it’s completely appropriate to insist that Microsoft continue to deliver Activision titles to other platforms, even if it wouldn’t make economic sense to do anything but. It’s increasingly difficult, though, to grasp any sort of coherent theory to the FTC’s antitrust decisions beyond ‘big tech bad’. There are real antitrust issues in the industry, but that requires actually understanding the industry to tease them out; that sort of understanding applied to this case would highlight Sony’s actual dominance and that having multiple compelling platforms with different business models is the essence of competition.
Ten years later, as a hand-me-down from a relative ↩
The Fairchild Channel F, which was released in 1976, was the actual first console-based video game system, but the 2600 was by far the most popular. ↩
It was always “Oh, you’re only at risk of automation if your job has a high degree of repetition, creative jobs are less at risk” but it feels like over the course of the past year Copilot, Dall-e, Midjourney, Stable Diffusion, and ChatGPT have decided upend that assumption. Writing, code, art… all with computers nipping at the heels with competency and speed. Fascinating. Unexpected in my lifetime. A mild bit alarming, but fascinating nonetheless.
I don’t think it’s all bad, but my brain is still ramping up to the new reality that these handicrafts have (likely) been permanently altered. We should celebrate the lower bar for creative endeavors; you no longer need to be an expert at Photoshop to produce a creative image, just an expert at generating prompts. People are extracting beautiful artifacts from these machines. Incredible.
As interesting a future this creates, I’m a member of an old caste of people that still believes massive gains don’t come without realized costs; or more explicitly, electricity isn’t the only cost. What if the cost we’re paying is our perception of reality itself? It’s increasingly likely that the next thing you read or watch is the product of a content extruder. Your favorite author, artist, creator, influencer, job applicant, or manager; the curtain pulled back to reveal a series of six word prompts. Rather than be left behind, I should start the augmentation process now…
After lunch at Kozak Eatery, a Ukrainian restaurant in #Gastown, I picked up some bread, a poppyseed pastry, and a sour cherry bun to take home. They have a mini bakery & deli at the front.
I’m trying to add AP to my site here to be able to provide streams to approved followers of otherwise unlisted content in my site. E.g. travel plans like Dopplr did, or Swarm style check-ins (normally posted to WP with micropub, e.g. here). Both those activities exist in ActivityStreams and thus in AP. That would be possible to follow with various existing AP clients. If more people do it, it might be useful to create a client surface to combine the various travel plan streams of others I follow and show crossing paths etc.
He completed his purchase of Twitter right before the annual meeting of the Association of Internet Researchers, held in Dublin in November of this year.
Coincidence? I think not.
The Musk takeover of Twitter prompted a conversation at AOIR’s meeting in Dublin in early November: should AOIR start a Mastodon (specifically, a Hometown) instance? As someone who has been advocating for alternative social media for years, I was all about this. Internet researchers have been among the first to recognize the perils of corporate social media. But of course, AOIR members often deeply engage online, which means using those systems for their pleasures and professional opportunities.
As the old commercial says, there’s got to be a better way: a way to do social media but to do it on our terms. If the Musk takeover is the catalyst that pushes AOIR to adopt the fediverse, then as disturbing as things have gotten, at least there will be a positive outcome.
Spurred on by Aram Sinnreich, we started having informal discussions at AOIR’s 2022 meeting about starting up our own social media. What would it entail? How would we do it? The informal discussion involved some of my favorite AOIR folks: Nik John, Adrienne Massanari, Nick Couldry, Pat Aufderheide, and Esther Hammelburg (if I left anyone out, please let me know).
The conversation went well but we all knew there was a lot of work ahead. Last week, I met with the AOIR Executive Committee to continue the work. They’ve agreed to my posting about this process to this blog.
This post is meant to do two things. First, it documents how an academic association deliberates over whether and how to establish a presence on the fediverse. That ought to be useful for other organizations considering doing the same. I know there are quite a few.
Second, my hope is that by sharing AOIR’s deliberations, the rest of the fediverse can have some insight into our decision to proceed (should it come to that). Given that AOIR members engage in Internet Research, there may be trepidation about AOIR joining the fediverse – would AOIR come to the fedi to study it? To turn its users into objects of research?
Put another way, will AOIR be a good organizational citizen of the fediverse? Will it host a well-moderated instance? Will it respect fediverse cultures and norms? Please read on, fedifriends. I hope that it’s clear AOIR is going to do it right – otherwise, AOIR is not going to do it at all.
Tough Questions
The meeting with AOIR Executive Committee went, in my view, extremely well, because they asked me the hardest questions. And for anyone starting a fediverse instance, I recommend asking similar questions. The questions included:
Do we spin up our own cloud server, a la Digital Ocean, or do we seek out managed hosting?
Do we plan for our total membership to be involved (this year, 1000 people) or for a fraction of them?
Do we block instances up front, or do we do so after bad actors appear?
Should we proceed if we can’t attract a pool of moderators?
How do we deal with minor infractions of a code of conduct?
How do we teach our members the ways of the fediverse – including the context-specific aspects of privacy and safety, especially in relation to research?
What would AOIR members get out of this?
The good news is: the conversation ended up answering these questions in the right way. The Executive Committee is on the right track, in my view.
No, we shouldn’t just spin up a DO droplet. We need managed hosting, because we do not have the expertise nor time to manage the backend.
And our anticipated growth from a few dozen interested early adoptors to potentially our full 1000-person membership also suggests working with managed hosting, since managed hosts have the expertise to scale up resources.
Yes to blocking instances from the outset. Rather than reacting to fascist BS after it happens, block the fascists first. This is the advice I’m hearing from the experienced admins out there, and it sounds like AOIR is going to do it, too.
No, we should not proceed if we can’t recruit moderators. First of all, having no moderators would send the wrong signal to the rest of the fediverse, namely that we are not serious about this. Second, if we can’t recruit moderators from our membership, then perhaps the membership isn’t showing enough interest in AOIR having an instance.
Speaking of moderation, minor infractions should not be a basis to boot people. Discussion is the best course. (For me, this is the promise of the fediverse: moderation at a human scale. It’s not easy, but at least we’re not under the illusion that AI can moderate, or that one moderator to 100K members is a good ratio). This is social media, after all, and it’s a new system. People will make minor mistakes. We need to be ready to help them.
Related to the above, yes, we need to onboard our members. The fediverse isn’t Twitter. Moreover, AOIR is the group that produced Internet Research Ethics guides. And our ethics guides clearly state that Internet research needs to be very sensitive to context. The context of the fediverse, in my view, is that consent is ultra-important. That means lots of discussions with the membership about new research methods that take into account consent of the fediverse members. In my view, this will be the true struggle of an AOIR instance, and the way in which we address it will make it or break it. Because if we fail to respect the consent culture of the fediverse, our instance will be isolated.
Finally, what would AOIR members get out of it? I mean, if you ask me, life beyond corporate social media is totally worth it. But the EC also suggests that this would allow for more communication among the membership – more opportunities for grad students and early researchers to connect with the senior researchers at AOIR. More opportunities to collaborate. More opportunities to share our work and celebrate it. And more cat pictures. Definitely more cat pictures.
More to come
The conversation isn’t over, and that means more tough questions. But it’s a good sign that it’s the Executive Committee asking them.
I will post more as things develop.
Edit for Credit
I didn’t mention in the original post that Sarah T. Roberts, Aram, and I drafted a Code of Conduct for the Executive Committee ahead of the meeting. I want to acknowledge Sarah and Aram’s work on that document, too. I imagine we can share a draft of the COC with the fediverse, but for now we’re working on it in-house.
An exploration of ChatGPTs reasoning through the logical / relational structure of diagrams.
Following on from the previous post —Fragment — Student Led Socratic Dialogues With an Unreliable ChatGPT — I wondered if ChatGPT to help us think visually (Can We use ChatGPT to Render Diagrams From Accessible Diagram Descriptions). In the following transcript, I am not really looking at the content of the flow charts to see if they make sense, just the structure of them and then asking gut feeling questions that might make the diagram look “more structureful”. (I may revisit this post and add commentary about the flow charts at some point… It might also be interesting to have a conversation where my follow on questions are actually based on reading the content of the previously suggested flow chart!;-)
using mermaid.js syntax, generate a flow chart that demonstrates the learning process emobided by a socratic dialogue
Me to Chat GPT
Here is an example flow chart using mermaid.js syntax that demonstrates the learning process embodied by a socratic dialogue:
graph TD;
A[Question] --> B[Answer];
B --> C[Reflection];
C --> D[New question];
D --> E[Answer];
E --> F[Reflection];
F --> G[New question];
This flow chart shows the process of a socratic dialogue, where one person asks a question (A), the other person answers (B), and then both reflect on the answer (C) and come up with a new question (D) based on that reflection. This process continues, with each question and answer leading to reflection and a new question, until the learning goal is reached.
Shouldn’t there be a loop in the diagram somewhere?
Me to ChatGPT
Yes, you are correct. In the original flow chart, there is no loop to represent the ongoing nature of a socratic dialogue. Here is an updated version of the flow chart that includes a loop:
graph TD;
A[Question] --> B[Answer];
B --> C[Reflection];
C --> D[New question];
D --> E[Answer];
E --> F[Reflection];
F --> G[New question];
G --> A;
This updated flow chart shows that the process of a socratic dialogue is ongoing, with each question and answer leading to reflection and a new question, and the process repeating until the learning goal is reached. The loop represents the continuous nature of the dialogue.
Shouldn’t the new question loop to an answer? In your diagram, remove any redundant or repeated steps
Me to ChatGPT
Note that the second sentence was added to the prompt after the the first part of the prompt alone gave rather long flow charts with duplicated steps.
You are correct, in the updated flow chart the new question (D) should loop back to an answer (E), rather than going directly to a reflection (F). Here is a revised flow chart that removes any redundant or repeated steps:
graph TD;
A[Question] --> B[Answer];
B --> C[Reflection];
C --> D[New question];
D --> E[Answer];
E --> F[Reflection];
F --> D;
This revised flow chart shows the process of a socratic dialogue, where one person asks a question (A), the other person answers (B), and then both reflect on the answer (C) and come up with a new question (D) based on that reflection. This process continues, with each question and answer leading to reflection and a new question, until the learning goal is reached. The loop at the end represents the continuous nature of the dialogue.
But now you have a question looping back to a question. Aren’t they the same question?
Me to ChatGPT
Suppose the person answering the question provided unreliable answers. How might the questioner add a step to check that the answer was correct?
Me to ChatGPT
If the person answering the question is providing unreliable answers, the questioner might add a step to check the accuracy of the answer before moving on to the reflection and new question stages. Here is an updated flow chart that includes this step:
graph TD;
A[Question] --> B[Answer];
B --> C[Check accuracy];
C --> D[Reflection];
D --> E[New question];
E --> F[Answer];
F --> G[Check accuracy];
G --> H[Reflection];
H --> I[New question];
I --> A;
This updated flow chart shows the process of a socratic dialogue, where the questioner asks a question (A) and the other person answers (B). The questioner then checks the accuracy of the answer (C) before moving on to the reflection and new question stages (D and E). This process continues, with each question and answer leading to a check for accuracy, reflection, and a new question, until the learning goal is reached. The loop at the end represents the continuous nature of the dialogue.
How about a process where the person asking the question is suspicious about the answer and asks the person answering the question to break down how they reached the answer into two or more smaller steps so that each of those steps could be checked, starting with the first, then if that is correct, the second, etc. Once again, please try to remove any repeated sequences through the efficient use of loops and branches (decisions).
Me to ChatGPT
This prompt was revised to request an “efficient” diagram wihtout repetition, and that might include branches.
Here is an updated flow chart that includes the process you described, where the person asking the question is suspicious about the answer and asks the person answering the question to break it down into smaller steps that can be checked for accuracy:
graph TD;
A[Question] --> B[Answer];
B --> C{Is answer correct?};
C -->|Yes| D[Reflection];
C -->|No| E[Break down answer into smaller steps];
E --> F[Check first step];
F --> G{Is first step correct?};
G -->|Yes| H[Check second step];
G -->|No| I[Reflection];
H --> J{Is second step correct?};
J -->|Yes| K[Check third step];
J -->|No| L[Reflection];
K --> M{Is third step correct?};
M -->|Yes| N[Reflection];
M -->|No| O[Reflection];
D --> P[New question];
P --> Q[Answer];
Q --> R[Reflection];
R --> P;
L --> P;
N --> P;
O --> P;
This updated flow chart shows the process of a socratic dialogue, where the questioner asks a question (A) and the other person answers (B). The questioner then checks the accuracy of the answer (C) and, if it is incorrect, asks the other person to break it down into smaller steps that can be checked (E). Each of these steps is checked for accuracy (F, H, and K), and if any of them are incorrect, the reflection stage is skipped and the process moves directly to the new question stage (P). If all of the steps are correct, the process moves on to the reflection stage (N) before continuing to the new question stage. This process continues, with each question and answer leading to reflection and a new question, until the learning goal is reached. The loops at the end represent the continuous nature of the dialogue.
Without really trying to understand that answer because it looked a bit complicated, I asked:
Is there any way of simplifying or abstracting that process a bit more to use a question like “check step” rather than “check first step”, “check second step?” etc
Me to ChatGPT
Yes, it is possible to simplify the process by using a generic "check step" instead of specifying "check first step," "check second step," etc. Here is an updated flow chart that uses a generic "check step" and removes any redundant or repeated steps:
graph TD;
A[Question] --> B[Answer];
B --> C{Is answer correct?};
C -->|Yes| D[Reflection];
C -->|No| E[Break down answer into smaller steps];
E --> F[Check step];
F --> G{Is step correct?};
G -->|Yes| H[Check next step];
G -->|No| I[Reflection];
H --> F;
D --> J[New question];
J --> K[Answer];
K --> L[Reflection];
L --> J;
I --> J;
This updated flow chart shows the process of a socratic dialogue, where the questioner asks a question (A) and the other person answers (B). The questioner then checks the accuracy of the answer (C) and, if it is incorrect, asks the other person to break it down into smaller steps that can be checked (E). Each of these steps is checked for accuracy (F) using a generic "check step" process, and if any of them are incorrect, the reflection stage is skipped and the process moves directly to the new question stage (J). If all of the steps are correct, the process moves on to the reflection stage (L) before continuing to the new question stage. This process continues, with each question and answer leading to reflection and a new question, until the learning goal is reached. The loops at the end represent the continuous nature of the dialogue.
Hmmm.. don’t we need a loop from the end of the chart re-entering the chart higher up somewhere? Or maybe we need to ask about a process with decisions that check whether a learning goal has been achieved?
I also had a follow up question — How does this final model compare in terms of ability to achieve a learning goal by identifying correct answers to each question, particularly in cases where the original answer is incorrect? — which perhaps should have been split over two prompts, but my session appeared to have timed out and was unable to complete any more responses.
PS another thought re: the resilience of using ChatGPT as part of an unreliable answerer Socratic process: each time you try the conversation, or replay a particular step, it may give you a different answer. Does that change things? How might that be modelled or represented in a flow chart?!
 The Orange Pi 5 has finally arrived! I received my pre-order and the board is great. So should you go out and buy it? Probably, but there are some things you should know first that you may not be expecting.
The biggest thing to know is that there is no WiFi/Bluetooth included. If you were planning on using Ethernet anyway this doesn't have much of an impact. If you do need wireless capabilities we'll cover what options are available.
In this review we'll cover what you need to know about the Orange Pi 5 including it's onboard capabilities, the available RAM options as well as benchmark the board. Let's get started!
The Orange Pi 5 has finally arrived! I received my pre-order and the board is great. So should you go out and buy it? Probably, but there are some things you should know first that you may not be expecting.
The biggest thing to know is that there is no WiFi/Bluetooth included. If you were planning on using Ethernet anyway this doesn't have much of an impact. If you do need wireless capabilities we'll cover what options are available.
In this review we'll cover what you need to know about the Orange Pi 5 including it's onboard capabilities, the available RAM options as well as benchmark the board. Let's get started!



 is equal to the angle of incidence
is equal to the angle of incidence  . This means that nearly all the light from the headlights ends up being directed forward, away from the car, and you don’t see any light on the pavement ahead of you.
. This means that nearly all the light from the headlights ends up being directed forward, away from the car, and you don’t see any light on the pavement ahead of you.